Inicio rápido: flujo de trabajo de orquestación
Use este artículo para empezar a trabajar con los proyectos de flujo de trabajo de orquestación mediante Language Studio y la API de REST. Siga estos pasos para probar un ejemplo.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
- Un proyecto de reconocimiento del lenguaje conversacional.
Inicio de sesión en Language Studio
Vaya a Language Studio e inicie sesión con su cuenta de Azure.
En la ventana Choose a language resource (Elección de recurso de idioma) que aparece, busque la suscripción de Azure y elija el recurso de idioma. Si no tiene un recursos, puede crearlo.
Detalles de la instancia Valor requerido Suscripción de Azure Su suscripción de Azure. Grupo de recursos de Azure El grupo de recursos de Azure. Nombre de recurso de Azure Nombre de su recurso de Azure. Location Una ubicación válida para el recurso de Azure. Por ejemplo, "Oeste de EE. UU. 2". Plan de tarifa Un plan de tarifa compatible con el recurso de Azure. Puede usar el nivel de servicio Gratis (F0) para probar el servicio. 

Creación de un proyecto de flujo de trabajo de orquestación
Una vez que haya creado un recurso de lenguaje, cree un proyecto de flujo de trabajo de orquestación. Un proyecto es un área de trabajo para compilar modelos de Machine Learning personalizados basados en los datos. A su proyecto solo puede acceder usted y otros usuarios que tengan acceso al recurso de idioma que se usa.
Para este inicio rápido, complete el inicio rápido de reconocimiento del lenguaje conversacional para crear un proyecto de reconocimiento del lenguaje conversacional que se usará más adelante.
En Language Studio, busque la sección Comprensión de preguntas y lenguaje conversacional y seleccione Flujo de trabajo de orquestación.

Esta acción lo llevará a la página proyecto de flujo de trabajo de orquestación. Seleccione Create new project (Crear proyecto). Para crear un proyecto, deberá proporcionar los detalles siguientes:

| Value | Descripción |
|---|---|
| Nombre | Nombre del proyecto. |
| Descripción | Descripción opcional del proyecto. |
| Idioma principal de las expresiones | Idioma principal del proyecto. Los datos de entrenamiento deben estar principalmente en este idioma. |
Cuando haya terminado, seleccione Siguiente y revise los detalles. Seleccione Crear proyecto para completar el proceso. Ahora debería ver la pantalla Compilación de esquema en el proyecto.
Compilación de esquema
Después de completar el inicio rápido de reconocimiento del lenguaje conversacional y crear un proyecto de orquestación, el paso siguiente es agregar intenciones.
Para conectarse al proyecto de reconocimiento del lenguaje conversacional creado anteriormente:
- En la página del esquema de compilación del proyecto de orquestación, seleccione Agregar para agregar una intención.
- En la ventana que aparece, dé un nombre a su intención.
- Seleccione Sí, quiero conectarlo a un proyecto existente.
- En el menú desplegable de servicios conectados, seleccione Reconocimiento del lenguaje conversacional.
- En el menú desplegable de nombre de proyecto, seleccione el proyecto de reconocimiento del lenguaje conversacional.
- Seleccione Agregar intención para crear la intención.
Entrenamiento de un modelo
Para entrenar un modelo, debe iniciar un trabajo de entrenamiento. La salida de un trabajo de entrenamiento correcto es el modelo entrenado.
Para empezar a entrenar el modelo desde Language Studio:
Seleccione Trabajos de entrenamiento en el menú de la izquierda.
Seleccione Iniciar un trabajo de entrenamiento en el menú superior.
Seleccione Train a new model (Entrenar un nuevo modelo) y escriba el nombre del modelo en el cuadro de texto. Para sobrescribir un modelo existente, seleccione esta opción y elija el modelo que quiera sobrescribir del menú desplegable. La sobrescritura de un modelo entrenado es irreversible, pero no afectará a los modelos implementados hasta que implemente el nuevo modelo.
Si ha habilitado el proyecto para dividir los datos manualmente al etiquetar las expresiones, verá dos opciones de división de datos:
- Dividir automáticamente el conjunto de pruebas de los datos de entrenamiento: las expresiones etiquetadas se dividirán aleatoriamente entre los conjuntos de entrenamiento y de prueba, según los porcentajes que elija. El porcentaje de división predeterminado es del 80 % para el entrenamiento y del 20 % para la prueba. Para cambiar estos valores, elija el conjunto que desea cambiar y escriba el nuevo valor.
Nota
Si elige la opción Dividir automáticamente el conjunto de pruebas de los datos de entrenamiento, solo se dividirán las expresiones del conjunto de entrenamiento según los porcentajes indicados.
- Use una división manual de datos de entrenamiento y pruebas: asigne cada expresión al conjunto de entrenamiento o pruebas durante el paso de etiquetado del proyecto.
Nota
Use una división manual de la opción de datos de entrenamiento y pruebas solo se habilitará si agrega expresiones al conjunto de pruebas en la página de datos de etiquetas. De lo contrario, se deshabilitará.

Seleccione el botón Entrenar.

Nota
- Los trabajos de entrenamiento completados correctamente serán los únicos que generarán modelos.
- El entrenamiento puede llevar entre un par de minutos y un par de horas en función del tamaño de los datos etiquetados.
- Solo puede haber un trabajo de entrenamiento ejecutándose en un momento dado. No puede iniciar otro trabajo de entrenamiento dentro del mismo proyecto hasta que se complete el trabajo en curso.
Implementación del modelo
Por lo general, después de entrenar un modelo, revisaría sus detalles de evaluación. En este inicio rápido, solo implementará el modelo y estará a su disposición para que lo pruebe en Language Studio, o bien puede llamar a la API de predicción.
Para implementar el modelo desde Language Studio:
Seleccione Implementación de un modelo en el menú de la izquierda.
Seleccione Agregar implementación para iniciar un nuevo trabajo de implementación.
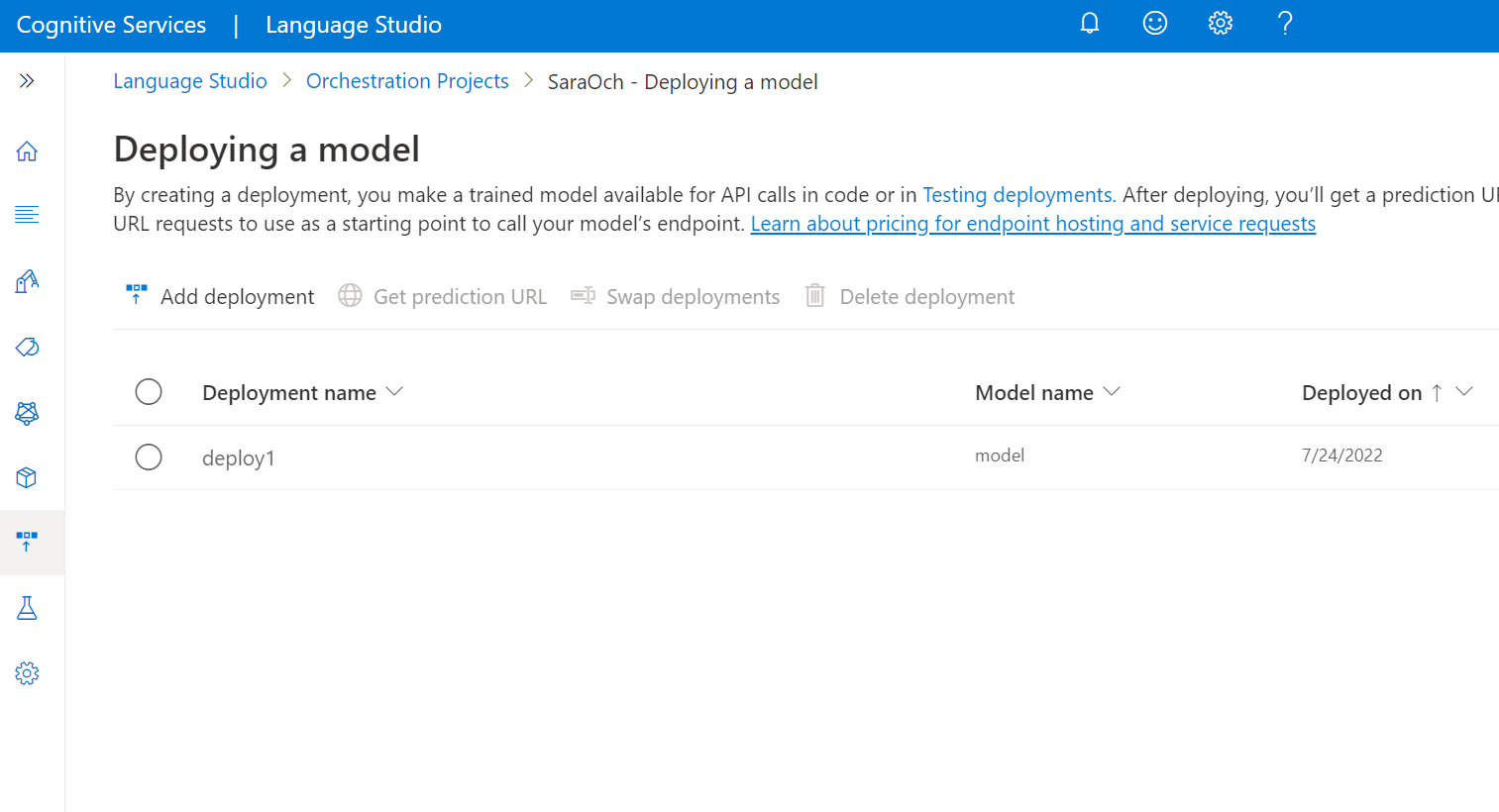
Seleccione Crear nueva implementación para crear una nueva implementación y asignar un modelo entrenado de la lista desplegable siguiente. También puede sobrescribir una implementación existente; para ello, seleccione esta opción y el modelo entrenado que quiere asignar en la lista desplegable siguiente.
Nota:
La sobrescritura de una implementación existente no requiere cambios en la llamada de la API de predicción, pero los resultados que obtendrá se basarán en el modelo recién asignado.

Si va a conectar una o varias aplicaciones de LUIS o proyectos de reconocimiento del lenguaje conversacional, debe especificar el nombre de la implementación.
No se requiere ninguna configuración para las respuestas a preguntas personalizadas ni las intenciones desvinculadas.
Los proyectos de LUIS deben publicarse en el espacio configurado durante la implementación de orquestación, y las knowledge base de respuesta a preguntas personalizada también deben publicarse en espacios de producción.
Seleccione Implementar para enviar su trabajo de implementación.
Después de que la implementación se realice correctamente, aparecerá una fecha de expiración junto a ella. La expiración de la implementación aparece cuando el modelo implementado deja de estar disponible para usarlo en la predicción, lo que suele ocurrir doce meses después de que expire una configuración de entrenamiento.


Probar modelo
Una vez implementado el modelo, puede empezar a usarlo para realizar predicciones a través de la API de predicción. En este inicio rápido, usará Language Studio para enviar una expresión, obtener predicciones y visualizar los resultados.
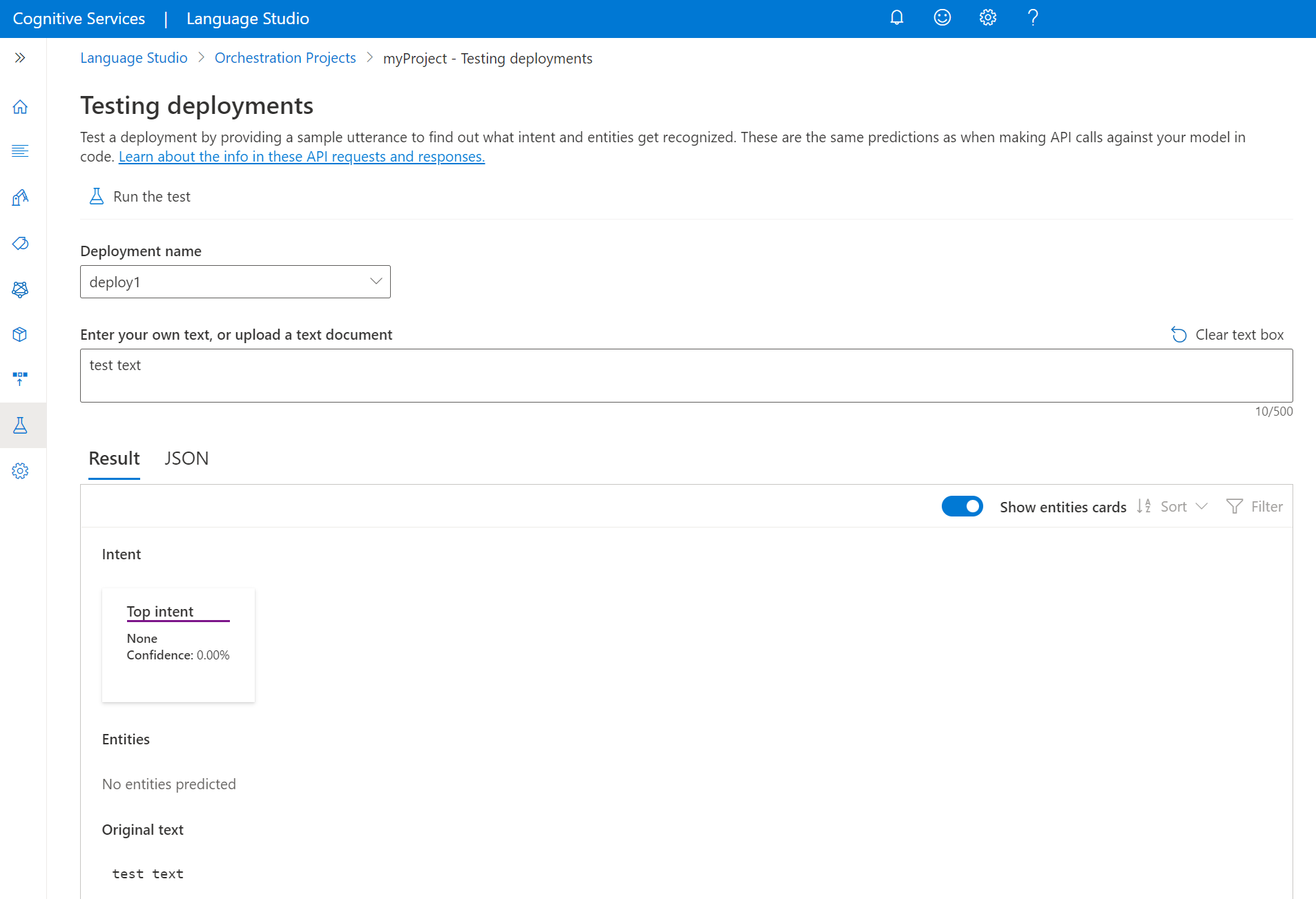
Para probar el modelo desde Language Studio
Seleccione Prueba de implementaciones en el menú lateral izquierdo.
Seleccione el modelo que quiera probar. Solo se pueden probar modelos que estén asignados a implementaciones.
En la lista desplegable nombre de implementación, seleccione el nombre de la implementación.
En el cuadro de texto, escriba una expresión que se va a probar.
En el menú superior, seleccione Ejecutar la prueba.
Después de ejecutar la prueba, debería ver la respuesta del modelo en el resultado. Puede ver los resultados en la vista de tarjetas de entidades o verlo en formato JSON.

Limpieza de recursos
Cuando ya no necesite el proyecto, puede eliminarlo mediante Language Studio. Seleccione Projectos del menú de navegación izquierdo, seleccione el proyecto que quiera eliminar y, a continuación, seleccione Eliminar en el menú superior.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
Crear un recurso de lenguaje desde el Azure Portal
Creación de un nuevo recurso en Azure Portal
Vaya a Azure Portal y cree un recurso de Lenguaje de Azure AI.
Seleccione Continuar para crear el recurso.
Cree un recurso de idioma con los detalles siguientes.
Detalles de la instancia Valor obligatorio Region Una de las regiones admitidas. Nombre Nombre para el recurso lingüístico. Plan de tarifa Uno de los planes de tarifa admitidos.
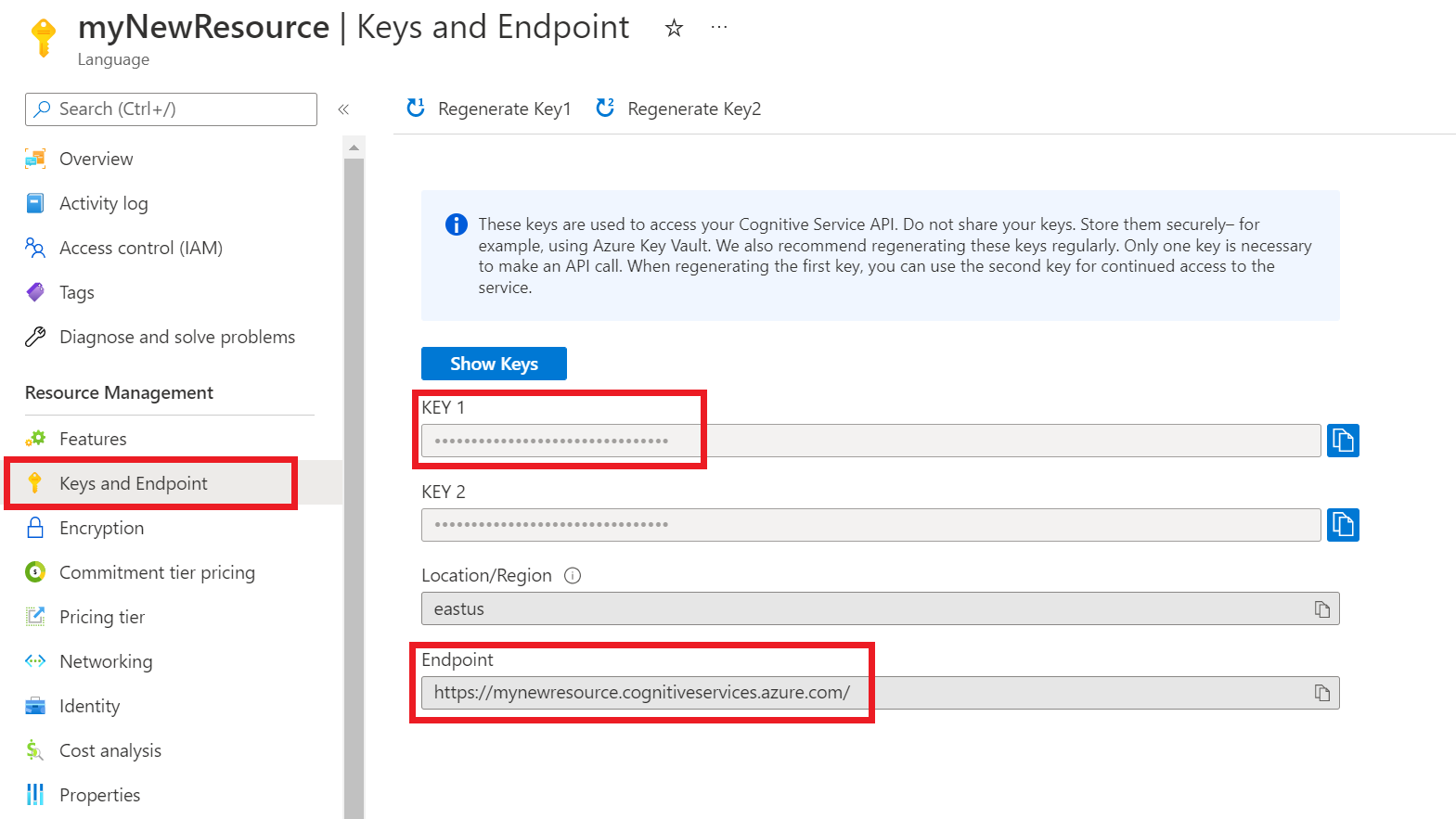
Obtención del punto de conexión y las claves del recurso
Vaya a la página de información general del recurso en Azure Portal.
En el menú de la izquierda, seleccione Claves y punto de conexión. Usará el punto de conexión y la clave para las solicitudes de API.

Creación de un proyecto de flujo de trabajo de orquestación
Una vez que haya creado un recurso de lenguaje, cree un proyecto de flujo de trabajo de orquestación. Un proyecto es un área de trabajo para compilar modelos de Machine Learning personalizados basados en los datos. A su proyecto solo puede acceder usted y otros usuarios que tengan acceso al recurso de idioma que se usa.
Para este inicio rápido, complete el inicio rápido de CLU con el fin de crear un proyecto de CLU que se usará en el flujo de trabajo de orquestación.
Envíe una solicitud PATCH con la dirección URL, los encabezados y el cuerpo JSON que se incluyen a continuación para crear un nuevo proyecto.
URL de la solicitud
Use la siguiente dirección URL al crear la solicitud de API. Reemplace los valores de los marcadores de posición por sus propios valores.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
La versión de la API a la que llama. | 2023-04-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Body
Use el siguiente código JSON de ejemplo como cuerpo.
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "Orchestration",
"description": "Project description"
}
| Clave | Marcador de posición | Valor | Ejemplo |
|---|---|---|---|
projectName |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | EmailApp |
language |
{LANGUAGE-CODE} |
Una cadena que especifica el código de idioma de las expresiones que se usan en el proyecto. Si el proyecto es un proyecto multilingüe, elija el código de idioma de la mayoría de las expresiones. | en-us |
Compilación de esquema
Después de completar el inicio rápido de CLU, y de crear un proyecto de orquestación, el siguiente paso es agregar intenciones.
Envíe una solicitud POST con la dirección URL, los encabezados y el cuerpo JSON que se incluyen a continuación para importar el proyecto.
URL de la solicitud
Use la siguiente dirección URL al crear la solicitud de API. Reemplace los valores de los marcadores de posición por sus propios valores.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
La versión de la API a la que llama. | 2023-04-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Body
Nota:
Cada intención solo debe ser de un único tipo (a elegir entre CLU, LUIS y qna)
Use el siguiente código JSON de ejemplo como cuerpo.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Orchestration",
"settings": {
"confidenceThreshold": 0
},
"projectName": "{PROJECT-NAME}",
"description": "Project description",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Orchestration",
"intents": [
{
"category": "string",
"orchestration": {
"kind": "luis",
"luisOrchestration": {
"appId": "00001111-aaaa-2222-bbbb-3333cccc4444",
"appVersion": "string",
"slotName": "string"
},
"cluOrchestration": {
"projectName": "string",
"deploymentName": "string"
},
"qnaOrchestration": {
"projectName": "string"
}
}
}
],
"utterances": [
{
"text": "Trying orchestration",
"language": "{LANGUAGE-CODE}",
"intent": "string"
}
]
}
}
| Clave | Marcador de posición | Valor | Ejemplo |
|---|---|---|---|
api-version |
{API-VERSION} |
Versión de la API a la que se llama. La versión que se use aquí debe ser la misma versión de API en la dirección URL. | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | EmailApp |
language |
{LANGUAGE-CODE} |
Una cadena que especifica el código de idioma de las expresiones que se usan en el proyecto. Si el proyecto es un proyecto multilingüe, elija el código de idioma de la mayoría de las expresiones. | en-us |
Entrenamiento de un modelo
Para entrenar un modelo, debe iniciar un trabajo de entrenamiento. La salida de un trabajo de entrenamiento correcto es el modelo entrenado.
Cree una solicitud POST mediante la dirección URL, los encabezados y el cuerpo JSON para enviar un trabajo de entrenamiento.
URL de la solicitud
Use la siguiente dirección URL al crear la solicitud de API. Reemplace los valores de los marcadores de posición por sus propios valores.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | EmailApp |
{API-VERSION} |
La versión de la API a la que llama. | 2023-04-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la solicitud
Use el siguiente objeto en la solicitud. El modelo se denominará MyModel una vez completado el entrenamiento.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "standard",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Clave | Marcador de posición | Valor | Ejemplo |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
Nombre del modelo. | Model1 |
trainingMode |
standard |
Modo de entrenamiento. Solo hay un modo para el entrenamiento disponible en la orquestación, el cual es standard. |
standard |
trainingConfigVersion |
{CONFIG-VERSION} |
Versión del modelo de configuración de entrenamiento. De manera predeterminada, se usa la versión más reciente del modelo. | 2022-05-01 |
kind |
percentage |
Métodos de división. Los valores posibles son percentage o manual. Vea cómo entrenar un modelo para obtener más información. |
percentage |
trainingSplitPercentage |
80 |
Porcentaje de los datos etiquetados que se incluirán en el conjunto de entrenamiento. El valor recomendado es 80. |
80 |
testingSplitPercentage |
20 |
Porcentaje de los datos etiquetados que se incluirán en el conjunto de pruebas. El valor recomendado es 20. |
20 |
Nota
trainingSplitPercentage y testingSplitPercentage solo son necesarios si Kind está establecido en percentage y la suma de ambos porcentajes es igual a 100.
Una vez que envíe la solicitud de API, recibirá una respuesta 202 que indica que se ha realizado correctamente. En los encabezados de respuesta, extraiga el valor operation-location. Tendrá el formato siguiente:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Puede usar esta dirección URL para obtener el estado del trabajo de entrenamiento.
Get Training Status
El entrenamiento puede tardar entre 10 y 30 minutos. Puede usar la siguiente solicitud para mantener el sondeo del estado del trabajo de entrenamiento hasta que se complete correctamente.
Use la siguiente solicitud GET para obtener el estado del proceso de entrenamiento del modelo. Reemplace los valores de los marcadores de posición por sus propios valores.
URL de la solicitud
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{YOUR-ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | EmailApp |
{JOB-ID} |
Id. para buscar el estado del entrenamiento del modelo. Este es el valor de encabezado location que recibió al enviar el trabajo de entrenamiento. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versión de la API a la que llama. | 2023-04-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la respuesta
Una vez que envíe la solicitud, recibirá la siguiente respuesta. Siga sondeando este punto de conexión hasta que el parámetro status cambie a "succeeded".
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxxx-xxxxx-xxxxxx-xxxxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Clave | Valor | Ejemplo |
|---|---|---|
modelLabel |
El nombre del modelo | Model1 |
trainingConfigVersion |
La versión de configuración de entrenamiento. De manera predeterminada, se usa la versión más reciente. | 2022-05-01 |
startDateTime |
La hora en que se inició el entrenamiento | 2022-04-14T10:23:04.2598544Z |
status |
El estado del trabajo de entrenamiento | running |
estimatedEndDateTime |
El tiempo estimado para que finalice el trabajo de entrenamiento | 2022-04-14T10:29:38.2598544Z |
jobId |
El identificador del trabajo de entrenamiento | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
La fecha y hora de creación del trabajo de entrenamiento | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
La fecha y hora de la última actualización del trabajo de entrenamiento | 2022-04-14T10:23:45Z |
expirationDateTime |
La fecha y hora de expiración del trabajo de entrenamiento | 2022-04-14T10:22:42Z |
Implementación del modelo
Por lo general, después de entrenar un modelo, revisaría sus detalles de evaluación. En este inicio rápido, solo implementará el modelo y llamará a la API de predicción para consultar los resultados.
Envío del trabajo de implementación
Cree una solicitud PUT con la dirección URL, los encabezados y el cuerpo JSON que se incluyen a continuación para empezar a implementar un modelo de flujo de trabajo de orquestación.
URL de la solicitud
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{DEPLOYMENT-NAME} |
El nombre de la implementación. Este valor distingue mayúsculas de minúsculas. | staging |
{API-VERSION} |
La versión de la API a la que llama. | 2023-04-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la solicitud
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Clave | Marcador de posición | Valor | Ejemplo |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nombre del modelo que se asignará a la implementación. Solo puede asignar modelos entrenados correctamente. Este valor distingue mayúsculas de minúsculas. | myModel |
Una vez que envíe la solicitud de API, recibirá una respuesta 202 que indica que se ha realizado correctamente. En los encabezados de respuesta, extraiga el valor operation-location. Tendrá el formato siguiente:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Puede usar esta dirección URL para obtener el estado del trabajo de implementación.
Obtención del estado del trabajo de implementación
Use la siguiente solicitud GET para consultar el estado del trabajo de implementación. Reemplace los valores de los marcadores de posición por sus propios valores.
URL de la solicitud
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{DEPLOYMENT-NAME} |
El nombre de la implementación. Este valor distingue mayúsculas de minúsculas. | staging |
{JOB-ID} |
Id. para buscar el estado del entrenamiento del modelo. Esto se encuentra en el valor de encabezado location que recibió de la API en respuesta a la solicitud de implementación de modelo. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versión de la API a la que llama. | 2023-04-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la respuesta
Una vez que envíe la solicitud, recibirá la siguiente respuesta. Siga sondeando este punto de conexión hasta que el parámetro status cambie a "succeeded".
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Consulta del modelo
Una vez implementado el modelo, puede empezar a usarlo para realizar predicciones a través de la API de predicción.
Una vez que la implementación se realice correctamente, puede empezar a consultar el modelo de implementación para obtener predicciones.
Cree una solicitud POST con la dirección URL, los encabezados y el cuerpo JSON que se incluyen a continuación para empezar a probar un modelo de flujo de trabajo de orquestación.
URL de la solicitud
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La versión de la API a la que llama. | 2023-04-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la solicitud
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"text": "Text1",
"participantId": "1",
"id": "1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"directTarget": "qnaProject",
"targetProjectParameters": {
"qnaProject": {
"targetProjectKind": "QuestionAnswering",
"callingOptions": {
"context": {
"previousUserQuery": "Meet Surface Pro 4",
"previousQnaId": 4
},
"top": 1,
"question": "App Service overview"
}
}
}
}
}
Cuerpo de la respuesta
Una vez que envíe la solicitud, recibirá la siguiente respuesta para la predicción.
{
"kind": "ConversationResult",
"result": {
"query": "App Service overview",
"prediction": {
"projectKind": "Orchestration",
"topIntent": "qnaTargetApp",
"intents": {
"qnaTargetApp": {
"targetProjectKind": "QuestionAnswering",
"confidenceScore": 1,
"result": {
"answers": [
{
"questions": [
"App Service overview"
],
"answer": "The compute resources you use are determined by the *App Service plan* that you run your apps on.",
"confidenceScore": 0.7384000000000001,
"id": 1,
"source": "https://learn.microsoft.com/azure/app-service/overview",
"metadata": {},
"dialog": {
"isContextOnly": false,
"prompts": []
}
}
]
}
}
}
}
}
}
Limpieza de recursos
Cuando ya no necesite el proyecto, puede eliminarlo mediante las API.
Cree una solicitud deELIMINAR con la dirección URL, los encabezados y el cuerpo JSON que se incluyen a continuación para eliminar un proyecto de reconocimiento del lenguaje conversacional.
URL de la solicitud
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
La versión de la API a la que llama. | 2023-04-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Una vez que envíe la solicitud de API, recibirá una respuesta 202 que indica que se ha realizado correctamente, lo que significa que el proyecto se ha eliminado.