Inicio rápido: Clasificación de texto personalizada
Use este artículo para empezar a crear un proyecto de clasificación de texto personalizada en el que puede entrenar modelos personalizados para la clasificación de texto. Un modelo es software de inteligencia artificial que se entrena para hacer una tarea determinada. Para este sistema, los modelos clasifican texto y se entrenan mediante el aprendizaje de datos etiquetados.
La clasificación de texto personalizada admite dos tipos de proyectos:
- Clasificación de etiqueta única: se puede asignar una sola clase a cada documento del conjunto de datos. Por ejemplo, el guion de una película solo podría clasificarse como "Romance" o como "Comedia".
- Clasificación mediante varias etiquetas: se pueden asignar varias clases a cada documento del conjunto de datos. Por ejemplo, el guion de una película podría clasificarse como "Comedia" o "Romance" y como "Comedia".
En este inicio rápido, puede usar los conjuntos de datos de ejemplo proporcionados para crear una clasificación de varias etiquetas donde puede clasificar scripts de películas en una o varias categorías, o bien puede usar un conjunto de datos de clasificación de etiquetas única, donde puede clasificar resúmenes de artículos científicos en uno de los dominios definidos.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
Creación de un recurso de Lenguaje de Azure AI y una cuenta de almacenamiento de Azure
Para poder usar la clasificación de texto personalizado, deberá crear un recurso de Lenguaje de Azure AI, que le proporcionará las credenciales que necesita para crear un proyecto y empezar a entrenar un modelo. También necesitará una cuenta de almacenamiento de Azure, donde pueda cargar el conjunto de datos que se usará para compilar el modelo.
Importante
Para comenzar a trabajar rápidamente, se recomienda crear un recurso de Lenguaje de Azure AI mediante los pasos que se proporcionan en este artículo. Con los pasos en este artículo podrá crear el recurso de idioma y la cuenta de almacenamiento al mismo tiempo, lo que resulta más fácil que hacerlo más tarde.
Si tiene un recurso preexistente que le gustaría usar, deberá conectarlo a la cuenta de almacenamiento.
Creación de un nuevo recurso en Azure Portal
Vaya a Azure Portal y cree un recurso de Lenguaje de Azure AI.
En la ventana que se abre, seleccione Clasificación de texto personalizado y reconocimiento de entidades con nombre personalizadas en las características personalizadas. Seleccione Continuar para crear el recurso en la parte inferior de la pantalla.
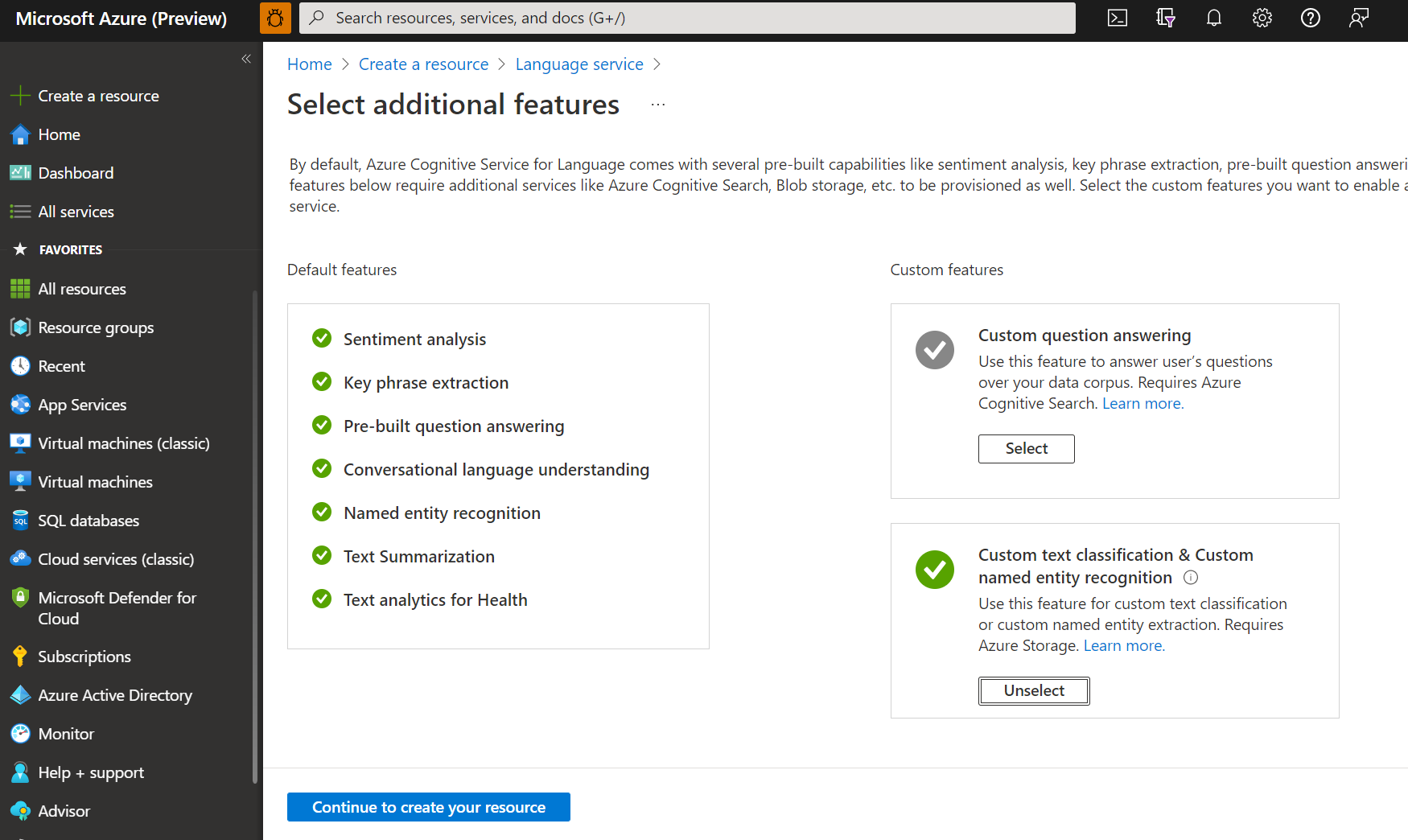
Cree un recurso de idioma con los detalles siguientes.
Nombre Valor obligatorio Subscription Su suscripción de Azure. Grupo de recursos Grupo de recursos que contendrá su recurso. Puede elegir uno existente o crear uno. Region Una de las regiones admitidas. Por ejemplo, "Oeste de EE. UU. 2". Nombre Nombre del recurso. Plan de tarifa Uno de los planes de tarifa admitidos. Puede usar el nivel de servicio Gratis (F0) para probar el servicio. Si recibe un mensaje que indica "la cuenta de inicio de sesión no es propietaria del grupo de recursos de la cuenta de almacenamiento seleccionada", la cuenta debe tener asignado un rol de propietario en el grupo de recursos para poder crear un recurso de idioma. Póngase en contacto con el propietario de la suscripción de Azure para obtener ayuda.
Para determinar el propietario de la suscripción de Azure, busque en el grupo de recursos y siga el vínculo a su suscripción asociada. A continuación:
- Seleccione la pestaña Control de acceso (IAM).
- Seleccione Asignaciones de roles.
- Filtre por Role:Owner.
En la sección Clasificación de texto personalizado y reconocimiento de entidades con nombre personalizadas, seleccione una cuenta de almacenamiento existente o Nueva cuenta de almacenamiento. Cabe decir que estos valores son para ayudarle a empezar; no son necesariamente los valores de la cuenta de almacenamiento que querrá usar en entornos de producción. Para evitar la latencia durante la compilación del proyecto, conéctese a cuentas de almacenamiento en la misma región que el recurso de idioma.
Valor de la cuenta de almacenamiento Valor recomendado Nombre de la cuenta de almacenamiento Cualquier nombre Tipo de cuenta de almacenamiento LRS estándar Asegúrese de que el Aviso de IA responsable esté activado. En la parte inferior de la página, seleccione Revisar y crear.

Carga de los datos de ejemplo en el contenedor de blobs
Después de crear una cuenta de almacenamiento de Azure y conectarla al recurso de idioma, deberá cargar los documentos del conjunto de datos de muestra en el directorio raíz de su contenedor. Estos archivos se usarán más adelante para entrenar el modelo.
Descargue el conjunto de datos de ejemplo para proyectos de clasificación de varias etiquetas.
Abra el archivo .zip y extraiga la carpeta que contiene los documentos.
El conjunto de datos de ejemplo proporcionado contiene aproximadamente 200 documentos, cada uno de los cuales es el resumen de una película. Cada documento pertenece a una o varias de las siguientes clases:
- "Misterio"
- "Drama"
- "Thriller"
- "Comedia"
- "Acción"
En Azure Portal, navegue hasta la cuenta de almacenamiento que ha creado y selecciónela. Para ello, haga clic en Cuentas de almacenamiento y escriba el nombre de la cuenta de almacenamiento en Filter for any field (Filtrar por cualquier campo).
Si el grupo de recursos no aparece, asegúrese de que el filtro Subscription equals (La suscripción es igual a) está establecido en Todo.
En la cuenta de almacenamiento, seleccione Contenedores en el menú de la izquierda, que se encuentra debajo de Almacenamiento de datos. En la pantalla que aparece, seleccione + Contenedor. Asigne al contenedor el nombre example-data y deje el Nivel de acceso público predeterminado.

Una vez creado el contenedor, haga clic en él. A continuación, seleccione el botón Cargar para seleccionar los archivos
.txty.jsonque descargó anteriormente.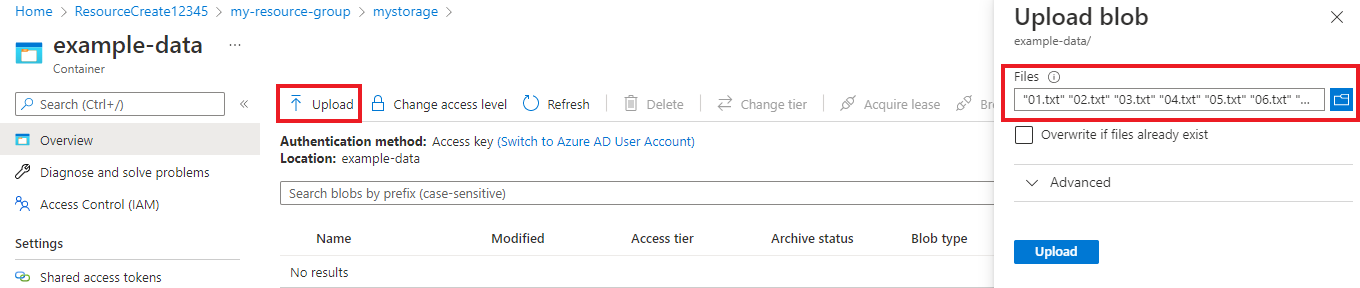


Crear un proyecto de clasificación de texto personalizado
Una vez configurados el recurso y el contenedor de almacenamiento, cree un nuevo proyecto de clasificación de texto personalizado. Un proyecto es un área de trabajo para compilar modelos de Machine Learning personalizados basados en los datos. A su proyecto solo puede acceder usted y otros usuarios que tengan acceso al recurso de idioma que se usa.
Inicie sesión en Language Studio. Aparecerá una ventana que le permitirá seleccionar la suscripción y el recurso de idioma. Seleccione el recurso de idioma.
En la sección Classify text (Clasificar texto) de Language Studio, busque Custom text classification (Clasificación de texto personalizado).

Seleccione Create new project (Crear proyecto) en el menú superior de la página de proyectos. La creación de un proyecto le permitirá etiquetar datos, entrenar, evaluar, mejorar e implementar los modelos.
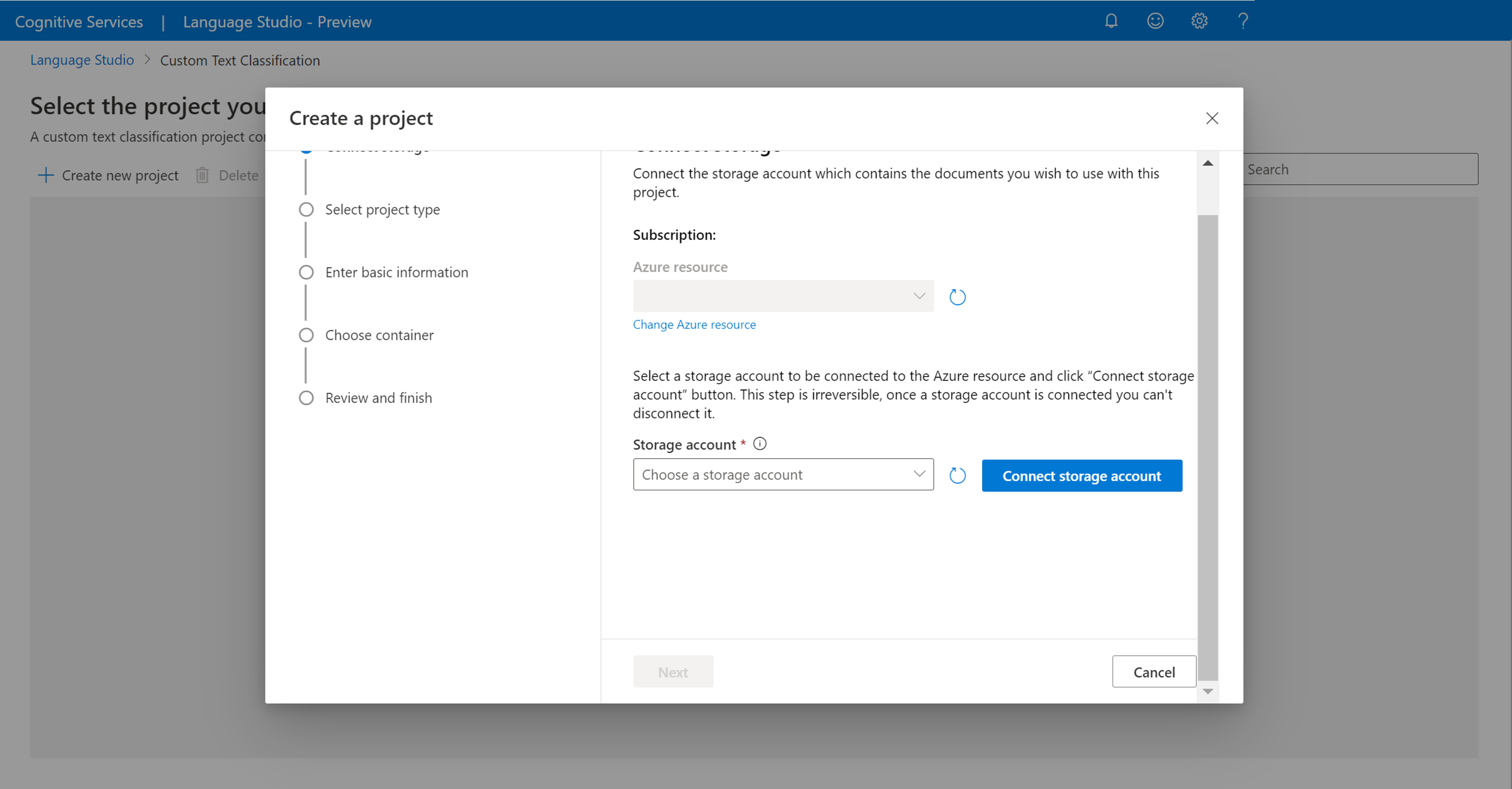
Después de hacer clic en Create new project (Crear proyecto), aparecerá una ventana para conectar la cuenta de almacenamiento. Si ya ha conectado una cuenta de almacenamiento, verá la cuenta de almacenamiento conectada. Si no es así, elija la cuenta de almacenamiento en la lista desplegable que aparece y seleccione Conectar cuenta de almacenamiento; esto establecerá los roles necesarios para la cuenta de almacenamiento. Este paso posiblemente devolverá un error si no está asignado como propietario en la cuenta de almacenamiento.
Nota
- Solo debe realizar este paso una vez con cada nuevo recurso de idioma que use.
- Este proceso es irreversible: si conecta una cuenta de almacenamiento al recurso de idioma, no podrá desconectarla más tarde.
- Solo puede conectar el recurso de idioma a una cuenta de almacenamiento.
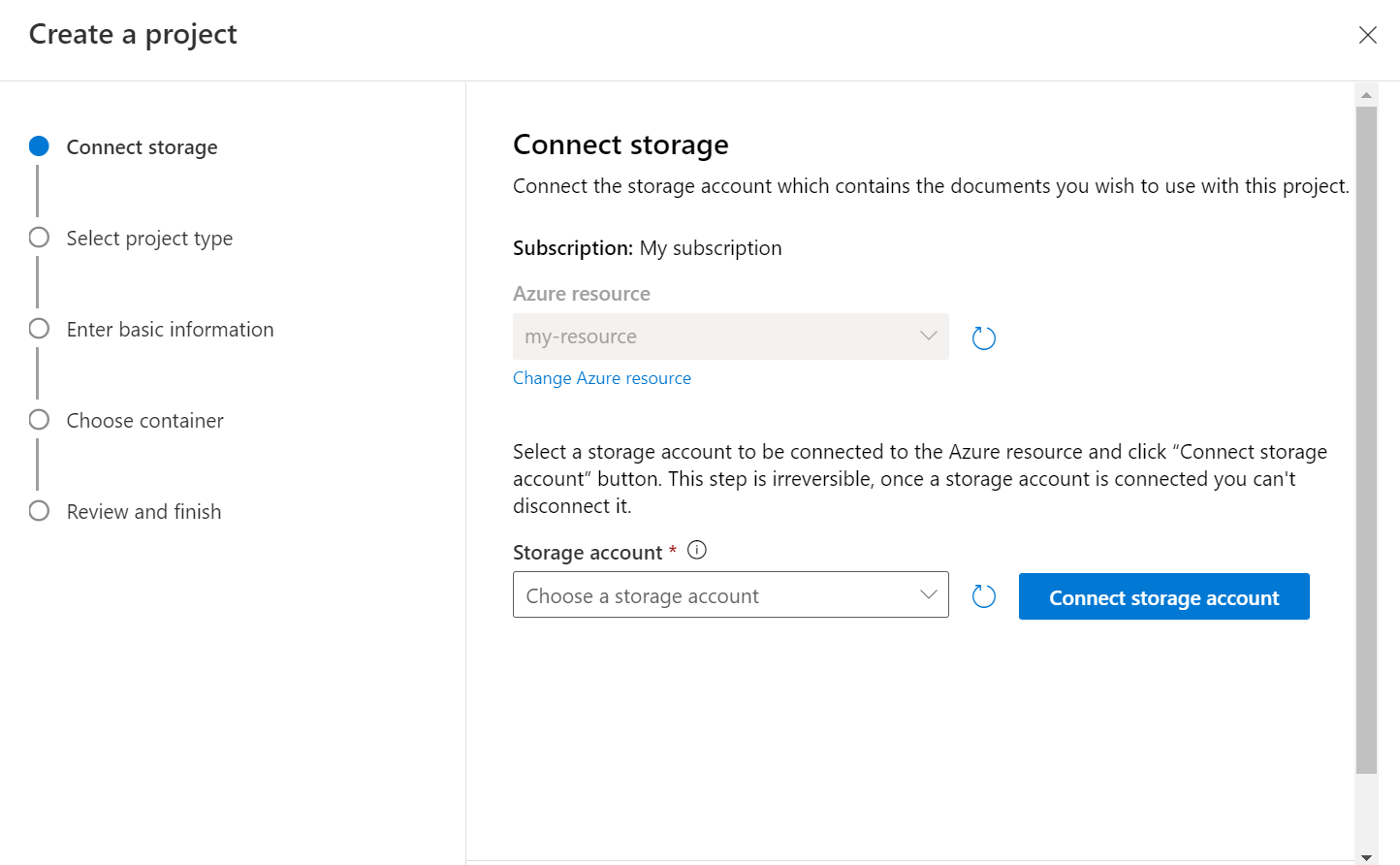
Seleccione el tipo de proyecto. Puede crear un proyecto de clasificación de varias etiquetas, donde cada documento puede pertenecer a una o varias clases, o un proyecto de clasificación de etiqueta única, donde cada documento solo puede pertenecer a una clase. El tipo seleccionado no se puede cambiar más adelante. Más información sobre los tipos de proyecto
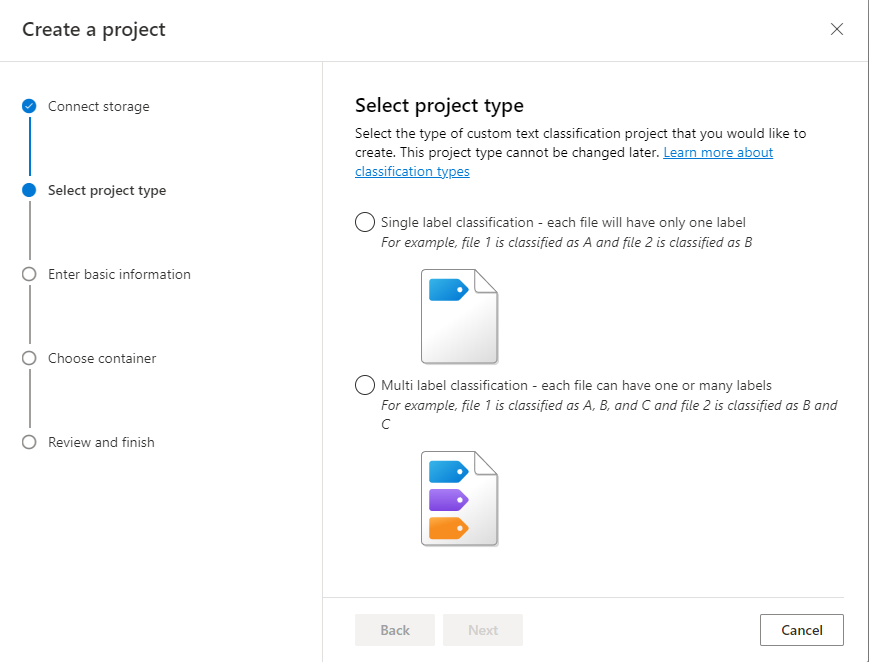
Introduzca la información del proyecto, como el nombre, una descripción y el idioma de los documentos del proyecto. Si usa el conjunto de datos de ejemplo, seleccione Inglés. El nombre del proyecto no se podrá cambiar posteriormente. Seleccione Next (Siguiente).
Sugerencia
El conjunto de datos no tiene que estar completamente en el mismo idioma. Puede tener varios documentos, cada uno de ellos con distintos idiomas admitidos. Si el conjunto de datos contiene documentos de distintos idiomas o si espera textos en idiomas diferentes durante el tiempo de ejecución, seleccione la opción Enable multi-lingual dataset (Habilitar conjunto de datos multilingüe) al especificar la información básica del proyecto. Esta opción se puede habilitar más adelante desde la página Configuración del proyecto.
Seleccione el contenedor en el que ha cargado el conjunto de datos.
Nota
Si ya ha etiquetado los datos, asegúrese de que siguen el formato admitido y seleccione Sí, mis documentos ya están etiquetados y he formateado el archivo de etiquetas JSON, y seleccione el archivo de etiquetas en el menú desplegable siguiente.
Si usa uno de los conjuntos de datos de ejemplo, use el archivo json
webOfScience_labelsFileomovieLabelsincluido. Luego, seleccione Siguiente.Revise los datos especificados y seleccione Create Project (Crear proyecto).




Entrenamiento de un modelo
Después de crear un proyecto, continúe y empiece a etiquetar los documentos que tiene en el contenedor conectado al proyecto. En este artículo de inicio rápido, ha importado un conjunto de datos etiquetado de ejemplo e inicializado el proyecto con el archivo de etiquetas JSON de ejemplo.
Para empezar a entrenar el modelo desde Language Studio:
Seleccione Trabajos de entrenamiento en el menú de la izquierda.
Seleccione Iniciar un trabajo de entrenamiento en el menú superior.
Seleccione Train a new model (Entrenar un nuevo modelo) y escriba el nombre del modelo en el cuadro de texto. Para sobrescribir un modelo existente, seleccione esta opción y elija el modelo que quiera sobrescribir del menú desplegable. La sobrescritura de un modelo entrenado es irreversible, pero no afectará a los modelos implementados hasta que implemente el nuevo modelo.

Seleccione el método de división de datos. Puede elegir Automatically splitting the testing set from training data (Dividir automáticamente el conjunto de pruebas de los datos de entrenamiento), y el sistema dividirá los datos etiquetados entre los conjuntos de entrenamiento y pruebas, según los porcentajes especificados. También puede usar una división manual de datos de entrenamiento y pruebas; esta opción solo está habilitada si ha agregado documentos al conjunto de pruebas durante el etiquetado de datos. Consulte Entrenamiento de un modelo para obtener información sobre la división de datos.
Seleccione el botón Entrenar.
Si selecciona el id. de trabajo de entrenamiento de la lista, aparecerá un panel lateral donde podrá comprobar el Progreso del entrenamiento, el Estado del trabajo y otros detalles de este trabajo.
Nota
- Los trabajos de entrenamiento completados correctamente serán los únicos que generarán modelos.
- El tiempo para entrenar el modelo puede llevar entre unos minutos y varias horas en función del tamaño de los datos etiquetados.
- Solo puede haber un trabajo de entrenamiento ejecutándose en un momento dado. No se puede iniciar otro trabajo de entrenamiento dentro del mismo proyecto hasta que se complete el trabajo en ejecución.

Implementación del modelo
Por lo general, después de entrenar un modelo, revisaría sus detalles de evaluación y realizaría mejoras si fuera necesario. En este inicio rápido, solo implementará el modelo y estará a su disposición para que lo pruebe en Language Studio, o bien puede llamar a la API de predicción.
Para implementar el modelo desde Language Studio:
Seleccione Implementación de un modelo en el menú de la izquierda.
Seleccione Agregar implementación para iniciar un nuevo trabajo de implementación.
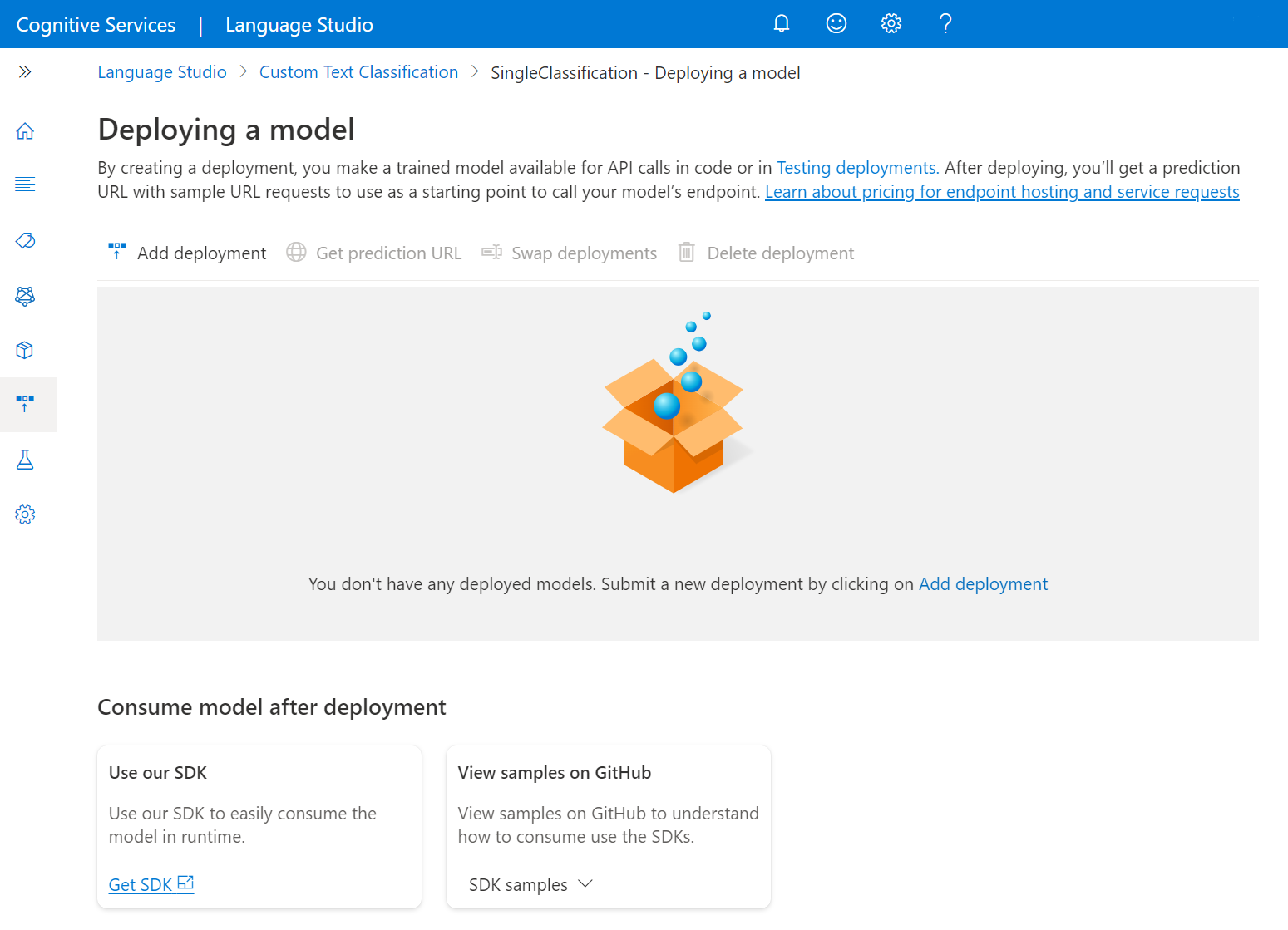
Seleccione Crear nueva implementación para crear una nueva implementación y asignar un modelo entrenado de la lista desplegable siguiente. También puede sobrescribir una implementación existente; para ello, seleccione esta opción y el modelo entrenado que quiere asignar en la lista desplegable siguiente.
Nota:
La sobrescritura de una implementación existente no requiere cambios en la llamada de la API de predicción, pero los resultados que obtendrá se basarán en el modelo recién asignado.
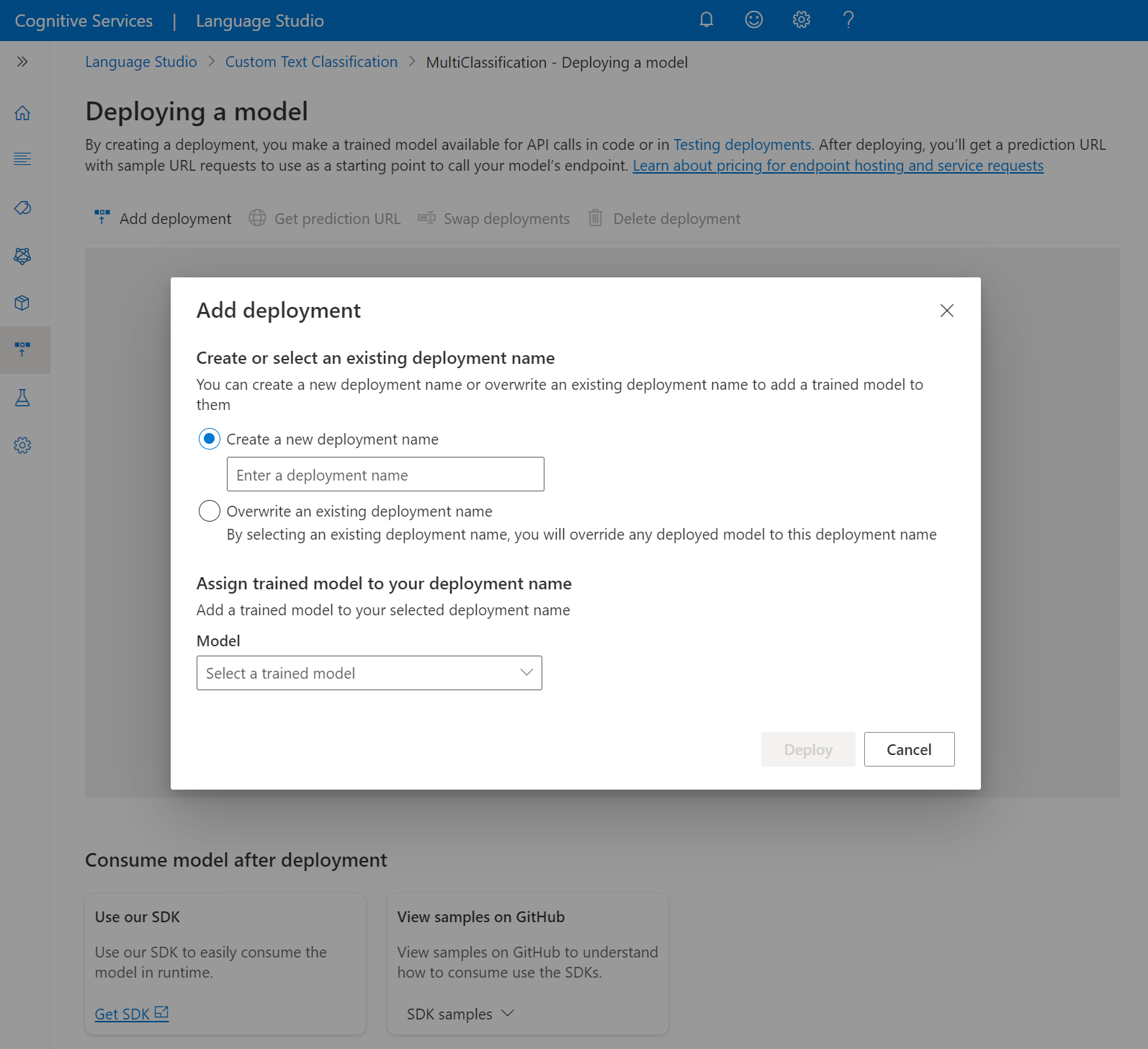
seleccione Implementar para iniciar el trabajo de implementación.
Después de que la implementación se realice correctamente, aparecerá una fecha de expiración junto a ella. La expiración de la implementación aparece cuando el modelo implementado deja de estar disponible para usarlo en la predicción, lo que suele ocurrir doce meses después de que expire una configuración de entrenamiento.


Comprobación del modelo
Una vez implementado el modelo, puede empezar a usarlo para clasificar el texto mediante Prediction API. Para este inicio rápido, usará Language Studio para enviar la tarea de clasificación de texto personalizado y ver los resultados. En el conjunto de datos de ejemplo que descargó anteriormente, puede encontrar algunos documentos de prueba que puede usar en este paso.
Para probar los modelos implementados en Language Studio:
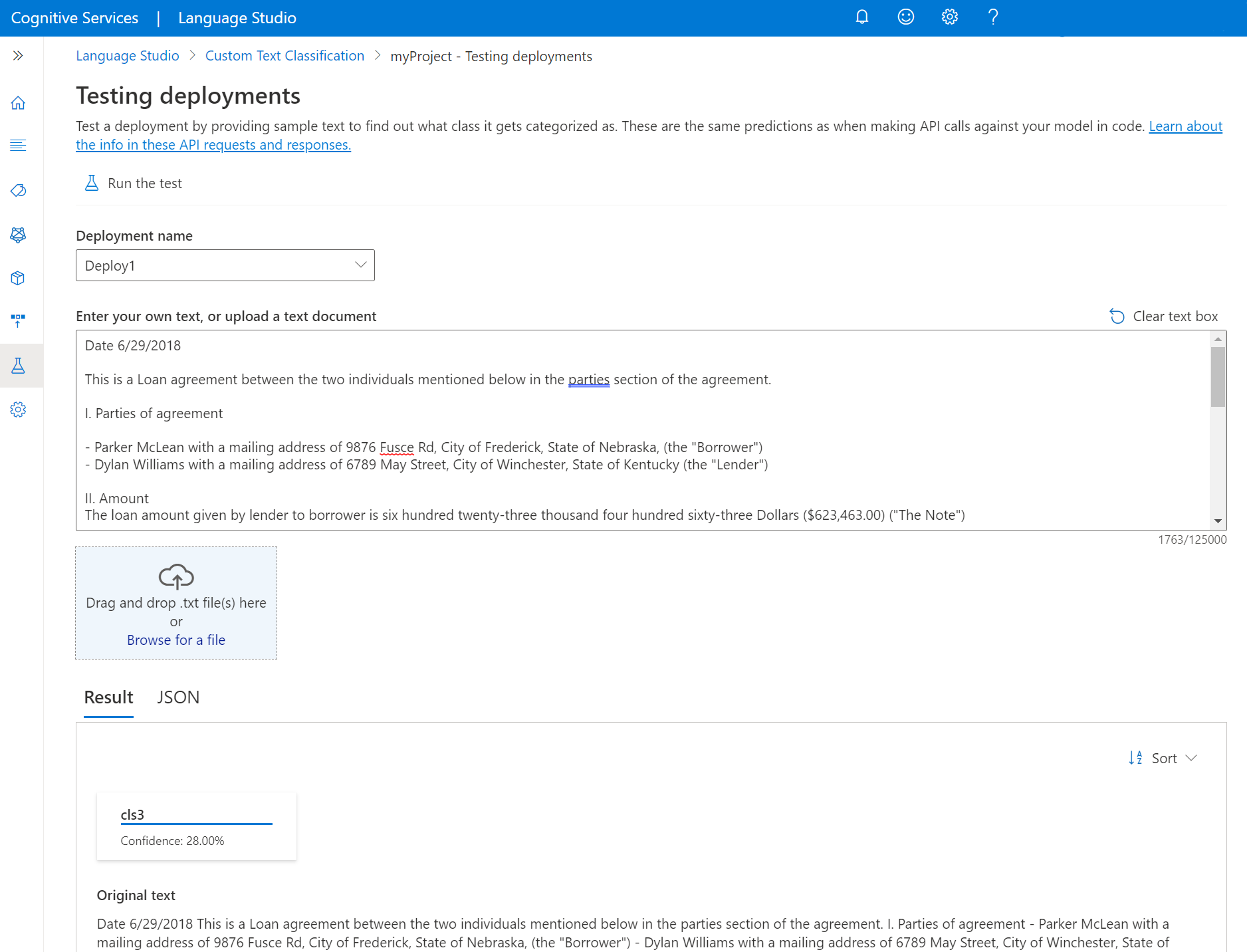
Seleccione Implementaciones de prueba en el menú del lado izquierdo de la pantalla.
Seleccione la implementación que quiere probar. Solo se pueden probar modelos que estén asignados a implementaciones.
En proyectos multilingües, seleccione el idioma del texto que está probando mediante la lista desplegable de idiomas.
Seleccione la implementación que quiera consultar/probar en la lista desplegable.
Escriba el texto que quiera enviar con la solicitud o cargue un documento
.txtpara usarlo. Si usa uno de los conjuntos de datos de ejemplo, puede usar uno de los archivos .txt incluidos.En el menú superior, seleccione Ejecutar la prueba.
En la pestaña Resultado, puede ver las clases de predicción para el texto. También puede ver la respuesta JSON en la pestaña JSON. El siguiente ejemplo corresponde a un proyecto de clasificación de una etiqueta. Un proyecto de clasificación de varias etiquetas puede devolver más de una clase en el resultado.

Limpieza de proyectos
Cuando ya no necesite el proyecto, puede eliminarlo mediante Language Studio. Seleccione Clasificación de texto personalizado en la parte superior y, a continuación, seleccione el proyecto que quiere eliminar. Seleccione Eliminar en el menú superior para eliminar el proyecto.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
Creación de un recurso de Lenguaje de Azure AI y una cuenta de almacenamiento de Azure
Para poder usar la clasificación de texto personalizado, deberá crear un recurso de Lenguaje de Azure AI, que le proporcionará las credenciales que necesita para crear un proyecto y empezar a entrenar un modelo. También necesitará una cuenta de almacenamiento de Azure, en la que pueda cargar el conjunto de datos que se usará para compilar el modelo.
Importante
Para empezar a trabajar rápidamente, se recomienda crear un recurso de Lenguaje de Azure AI mediante los pasos que se indican en este artículo, que le permitirán crear el recurso de lenguaje y crear o conectar una cuenta de almacenamiento al mismo tiempo, lo que resulta más fácil que hacerlo después.
Si tiene un recurso preexistente que le gustaría usar, deberá conectarlo a la cuenta de almacenamiento.
Creación de un nuevo recurso en Azure Portal
Vaya a Azure Portal y cree un recurso de Lenguaje de Azure AI.
En la ventana que se abre, seleccione Clasificación de texto personalizado y reconocimiento de entidades con nombre personalizadas en las características personalizadas. Seleccione Continuar para crear el recurso en la parte inferior de la pantalla.
Cree un recurso de idioma con los detalles siguientes.
Nombre Valor obligatorio Subscription Su suscripción de Azure. Grupo de recursos Grupo de recursos que contendrá su recurso. Puede elegir uno existente o crear uno. Region Una de las regiones admitidas. Por ejemplo, "Oeste de EE. UU. 2". Nombre Nombre del recurso. Plan de tarifa Uno de los planes de tarifa admitidos. Puede usar el nivel de servicio Gratis (F0) para probar el servicio. Si recibe un mensaje que indica "la cuenta de inicio de sesión no es propietaria del grupo de recursos de la cuenta de almacenamiento seleccionada", la cuenta debe tener asignado un rol de propietario en el grupo de recursos para poder crear un recurso de idioma. Póngase en contacto con el propietario de la suscripción de Azure para obtener ayuda.
Para determinar el propietario de la suscripción de Azure, busque en el grupo de recursos y siga el vínculo a su suscripción asociada. A continuación:
- Seleccione la pestaña Control de acceso (IAM).
- Seleccione Asignaciones de roles.
- Filtre por Role:Owner.
En la sección Clasificación de texto personalizado y reconocimiento de entidades con nombre personalizadas, seleccione una cuenta de almacenamiento existente o Nueva cuenta de almacenamiento. Cabe decir que estos valores son para ayudarle a empezar; no son necesariamente los valores de la cuenta de almacenamiento que querrá usar en entornos de producción. Para evitar la latencia durante la compilación del proyecto, conéctese a cuentas de almacenamiento en la misma región que el recurso de idioma.
Valor de la cuenta de almacenamiento Valor recomendado Nombre de la cuenta de almacenamiento Cualquier nombre Tipo de cuenta de almacenamiento LRS estándar Asegúrese de que el Aviso de IA responsable esté activado. En la parte inferior de la página, seleccione Revisar y crear.
Carga de los datos de ejemplo en el contenedor de blobs
Después de crear una cuenta de almacenamiento de Azure y conectarla al recurso de idioma, deberá cargar los documentos del conjunto de datos de muestra en el directorio raíz de su contenedor. Estos archivos se usarán más adelante para entrenar el modelo.
Descargue el conjunto de datos de ejemplo para proyectos de clasificación de varias etiquetas.
Abra el archivo .zip y extraiga la carpeta que contiene los documentos.
El conjunto de datos de ejemplo proporcionado contiene aproximadamente 200 documentos, cada uno de los cuales es el resumen de una película. Cada documento pertenece a una o varias de las siguientes clases:
- "Misterio"
- "Drama"
- "Thriller"
- "Comedia"
- "Acción"
En Azure Portal, navegue hasta la cuenta de almacenamiento que ha creado y selecciónela. Para ello, haga clic en Cuentas de almacenamiento y escriba el nombre de la cuenta de almacenamiento en Filter for any field (Filtrar por cualquier campo).
Si el grupo de recursos no aparece, asegúrese de que el filtro Subscription equals (La suscripción es igual a) está establecido en Todo.
En la cuenta de almacenamiento, seleccione Contenedores en el menú de la izquierda, que se encuentra debajo de Almacenamiento de datos. En la pantalla que aparece, seleccione + Contenedor. Asigne al contenedor el nombre example-data y deje el Nivel de acceso público predeterminado.
Una vez creado el contenedor, haga clic en él. A continuación, seleccione el botón Cargar para seleccionar los archivos
.txty.jsonque descargó anteriormente.
Obtención del punto de conexión y las claves del recurso
Vaya a la página de información general del recurso en Azure Portal.
En el menú de la izquierda, seleccione Claves y punto de conexión. Usará el punto de conexión y la clave para las solicitudes de API.

Crear un proyecto de clasificación de texto personalizado
Una vez configurados el recurso y el contenedor de almacenamiento, cree un nuevo proyecto de clasificación de texto personalizado. Un proyecto es un área de trabajo para compilar modelos de Machine Learning personalizados basados en los datos. A su proyecto solo puede acceder usted y otros usuarios que tengan acceso al recurso de idioma que se usa.
Desencadenamiento del trabajo del proyecto de importación
Envíe una solicitud POST con la dirección URL, los encabezados y el cuerpo JSON que se incluyen a continuación para importar el archivo de etiquetas. Asegúrese de que el archivo de etiquetas siga el formato aceptado.
Si ya existe un proyecto con el mismo nombre, se reemplazan los datos de ese proyecto.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión más reciente publicada. Obtenga más información sobre otras versiones de API disponibles | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Body
Utilice el siguiente código JSON en la solicitud. Reemplace los valores de los marcadores de posición por sus propios valores.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Clave | Marcador de posición | Valor | Ejemplo |
|---|---|---|---|
| api-version | {API-VERSION} |
Versión de la API a la que se llama. La versión que se use aquí debe ser la misma versión de API en la dirección URL. Obtenga más información sobre otras versiones de API disponibles | 2022-05-01 |
| projectName | {PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
| projectKind | customMultiLabelClassification |
El tipo de proyecto. | customMultiLabelClassification |
| language | {LANGUAGE-CODE} |
Una cadena que especifica el código de idioma de los documentos que se usan en el proyecto. Si el proyecto es un proyecto multilingüe, elija el código de idioma de la mayoría de los documentos. Consulte Compatibilidad de idiomas para obtener más información sobre la compatibilidad multilingüe. | en-us |
| multilingües | true |
Un valor booleano que le permite tener documentos en varios idiomas del conjunto de datos y, cuando se implementa el modelo, puede consultar el modelo en cualquier idioma admitido (no necesariamente incluido en los documentos de entrenamiento. Consulte Compatibilidad de idiomas para obtener más información sobre la compatibilidad multilingüe. | true |
| storageInputContainerName | {CONTAINER-NAME} |
Nombre del contenedor de almacenamiento de Azure donde ha cargado los documentos. | myContainer |
| clases | [] | Matriz que contiene todas las clases que tiene en el proyecto. Se trata de las clases en las que desea clasificar los documentos. | [] |
| Documentos | [] | Matriz que contiene todos los documentos del proyecto y cuáles son las clases etiquetadas en este documento. | [] |
| ubicación | {DOCUMENT-NAME} |
Ubicación de los documentos en el contenedor de almacenamiento. Puesto que todos los documentos están en la raíz del contenedor, este debe ser el nombre del documento. | doc1.txt |
| dataset | {DATASET} |
Conjunto de pruebas al que este documento irá cuando se divida antes del entrenamiento. Consulte Entrenamiento de un modelo para obtener información sobre la división de datos. Los valores posibles que admite este campo son Train y Test. |
Train |
Una vez que envíe la solicitud de API, recibirá una respuesta 202 que indica que el trabajo se ha enviado correctamente. En los encabezados de respuesta, extraiga el valor operation-location. Tendrá el formato siguiente:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} se usa para identificar la solicitud, ya que esta operación es asincrónica. Usará esta dirección URL para obtener el estado del trabajo de importación.
Posibles escenarios de error de esta solicitud:
- El recurso seleccionado no tiene los permisos adecuados para la cuenta de almacenamiento.
- El valor de
storageInputContainerNameespecificado no existe. - Se ha usado un código de idioma no válido, o el tipo de código de idioma no es una cadena.
- El valor de
multilinguales una cadena y no un valor booleano.
Obtención del estado del trabajo de importación
Use la siguiente solicitud GET para obtener el estado de la importación del proyecto. Reemplace los valores de los marcadores de posición por sus propios valores.
URL de la solicitud
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{JOB-ID} |
Id. para buscar el estado del entrenamiento del modelo. Este valor se encuentra en el valor de encabezado location que recibió en el paso anterior. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión más reciente publicada. Obtenga más información sobre otras versiones de API disponibles | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Entrenamiento de un modelo
Después de crear un proyecto, continúe y empiece a etiquetar los documentos que tiene en el contenedor conectado al proyecto. En este inicio rápido, ha importado un conjunto de datos etiquetado de ejemplo e inicializado el proyecto con el archivo de etiquetas JSON de ejemplo.
Inicio del entrenamiento del modelo
Una vez importado el proyecto, puede empezar a entrenar el modelo.
Envíe una solicitud POST mediante la dirección URL, los encabezados y el cuerpo JSON para enviar un trabajo de entrenamiento. Reemplace los valores de los marcadores de posición por sus propios valores.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión más reciente publicada. Obtenga más información sobre otras versiones de API disponibles | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la solicitud
Use el siguiente código JSON en el cuerpo de la solicitud. El modelo se denominará {MODEL-NAME} una vez completado el entrenamiento. Solo los trabajos de entrenamiento correctos generarán modelos.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Clave | Marcador de posición | Valor | Ejemplo |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Nombre que se asignará al modelo una vez entrenado correctamente. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Se trata de la versión de modelo que se usará para entrenar el modelo. | 2022-05-01 |
| evaluationOptions | Opción para dividir los datos en conjuntos de entrenamiento y pruebas. | {} |
|
| kind | percentage |
Métodos de división. Los valores posibles son percentage o manual. Para más información, consulte Cómo entrenar un modelo. |
percentage |
| trainingSplitPercentage | 80 |
Porcentaje de los datos etiquetados que se incluirán en el conjunto de entrenamiento. El valor recomendado es 80. |
80 |
| testingSplitPercentage | 20 |
Porcentaje de los datos etiquetados que se incluirán en el conjunto de pruebas. El valor recomendado es 20. |
20 |
Nota
trainingSplitPercentage y testingSplitPercentage solo son necesarios si Kind está establecido en percentage y la suma de ambos porcentajes es igual a 100.
Una vez que envíe la solicitud de API, recibirá una respuesta 202 que indica que el trabajo se ha enviado correctamente. En los encabezados de respuesta, extraiga el valor location. Tendrá el formato siguiente:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} se usa para identificar la solicitud, ya que esta operación es asincrónica. Puede usar esta dirección URL para obtener el estado del entrenamiento.
Obtén el estado del trabajo de entrenamiento
El entrenamiento puede tardar entre 10 y 30 minutos. Puede usar la siguiente solicitud para mantener el sondeo del estado del trabajo de entrenamiento hasta que se complete correctamente.
Use la siguiente solicitud GET para obtener el estado del proceso de entrenamiento del modelo. Reemplace los valores de los marcadores de posición por sus propios valores.
URL de la solicitud
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{JOB-ID} |
Id. para buscar el estado del entrenamiento del modelo. Este valor se encuentra en el valor de encabezado location que recibió en el paso anterior. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión más reciente publicada. Consulte Ciclo de vida del modelo para obtener más información sobre otras versiones de API disponibles. | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la respuesta
Una vez que envíe la solicitud, recibirá la siguiente respuesta.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Implementación del modelo
Por lo general, después de entrenar un modelo, revisaría sus detalles de evaluación y realizaría mejoras si fuera necesario. En este inicio rápido, solo implementará el modelo y estará a su disposición para que lo pruebe en Language Studio, o bien puede llamar a la API de predicción.
Envío del trabajo de implementación
Envíe una solicitud PUT mediante la dirección URL, los encabezados y el cuerpo JSON para enviar un trabajo de implementación. Reemplace los valores de los marcadores de posición por sus propios valores.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{DEPLOYMENT-NAME} |
Nombre de la implementación. Este valor distingue mayúsculas de minúsculas. | staging |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión más reciente publicada. Obtenga más información sobre otras versiones de API disponibles | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la solicitud
Use el siguiente código JSON en el cuerpo de la solicitud. Use el nombre del modelo que se va a asignar a la implementación.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Clave | Marcador de posición | Valor | Ejemplo |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nombre del modelo que se asignará a la implementación. Solo puede asignar modelos entrenados correctamente. Este valor distingue mayúsculas de minúsculas. | myModel |
Una vez que envíe la solicitud de API, recibirá una respuesta 202 que indica que el trabajo se ha enviado correctamente. En los encabezados de respuesta, extraiga el valor operation-location. Tendrá el formato siguiente:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} se usa para identificar la solicitud, ya que esta operación es asincrónica. Puede usar esta dirección URL para obtener el estado de la implementación.
Obtención del estado del trabajo de implementación
Use la siguiente solicitud GET para consultar el estado del trabajo de implementación. Puede usar la dirección URL que recibió en el paso anterior o reemplazar los valores de los marcadores de posición siguientes por sus propios valores.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{DEPLOYMENT-NAME} |
Nombre de la implementación. Este valor distingue mayúsculas de minúsculas. | staging |
{JOB-ID} |
Id. para buscar el estado del entrenamiento del modelo. Se encuentra en el valor de encabezado location que recibió en el paso anterior. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión más reciente publicada. Obtenga más información sobre otras versiones de API disponibles | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | Valor |
|---|---|
Ocp-Apim-Subscription-Key |
Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Cuerpo de la respuesta
Una vez que envíe la solicitud, recibirá la siguiente respuesta. Siga sondeando este punto de conexión hasta que el parámetro status cambie a "succeeded". Debe obtener un código 200 para indicar el éxito de la solicitud.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Clasificación de texto
Una vez implementado el modelo correctamente, puede empezar a usarlo para clasificar el texto mediante Prediction API. En el conjunto de datos de ejemplo que descargó anteriormente, puede encontrar algunos documentos de prueba que puede usar en este paso.
Enviar una tarea de clasificación de texto personalizado
Use esta solicitud POST para iniciar una tarea de clasificación de texto.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión más reciente publicada. Consulte Ciclo de vida del modelo para obtener más información sobre otras versiones de API disponibles. | 2022-05-01 |
encabezados
| Clave | valor |
|---|---|
| Ocp-Apim-Subscription-Key | La clave que proporciona acceso a esta API. |
Body
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Clave | Marcador de posición | Valor | Ejemplo |
|---|---|---|---|
displayName |
{JOB-NAME} |
Nombre del trabajo. | MyJobName |
documents |
[{},{}] | Lista de documentos en los que se van a ejecutar las tareas. | [{},{}] |
id |
{DOC-ID} |
Nombre o identificador del documento. | doc1 |
language |
{LANGUAGE-CODE} |
Cadena donde se especifica el código de idioma del documento. Si esta clave no se ha especificado, el servicio toma el idioma predeterminado del proyecto que se seleccionó durante la creación del proyecto. Consulte Compatibilidad de idiomas para ver una lista de los códigos de idioma admitidos. | en-us |
text |
{DOC-TEXT} |
Tarea de documento en la que ejecutar las tareas. | Lorem ipsum dolor sit amet |
tasks |
Lista de tareas que queremos realizar. | [] |
|
taskName |
CustomMultiLabelClassification | Nombre de la tarea. | CustomMultiLabelClassification |
parameters |
Lista de parámetros que se van a pasar a la tarea. | ||
project-name |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Nombre de la implementación. Este valor distingue mayúsculas de minúsculas. | prod |
Response
Recibirá una respuesta 202 que indica que se ha realizado correctamente. En los encabezados de la respuesta, extraiga el valor de operation-location.
operation-location tiene el formato siguiente:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Puede usar esta dirección URL para consultar el estado de finalización de la tarea y obtener los resultados cuando la tarea se complete.
Obtención de resultados de la tarea
Use la siguiente solicitud GET para consultar el estado o los resultados de la tarea de clasificación de texto.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión del modelo publicada más reciente. | 2022-05-01 |
encabezados
| Clave | valor |
|---|---|
| Ocp-Apim-Subscription-Key | La clave que proporciona acceso a esta API. |
Response body
La respuesta será un documento JSON con los parámetros siguientes.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Limpieza de recursos
Cuando ya no necesite el proyecto, puede eliminarlo con la siguiente solicitud DELETE. Reemplace los valores de los marcadores de posición por sus propios valores.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Marcador de posición | Valor | Ejemplo |
|---|---|---|
{ENDPOINT} |
Punto de conexión para autenticar la solicitud de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nombre del proyecto. Este valor distingue mayúsculas de minúsculas. | myProject |
{API-VERSION} |
Versión de la API a la que se llama. El valor al que se hace referencia aquí se corresponde con la versión más reciente publicada. Obtenga más información sobre otras versiones de API disponibles | 2022-05-01 |
encabezados
Use el siguiente encabezado para autenticar la solicitud.
| Clave | valor |
|---|---|
| Ocp-Apim-Subscription-Key | Clave para el recurso. Se usa para autenticar las solicitudes de API. |
Una vez que envíe la solicitud de API, recibirá una respuesta 202 que indica que se ha realizado correctamente, lo que significa que el proyecto se ha eliminado. Una llamada correcta devuelve un encabezado Operation-Location que se usa para comprobar el estado del trabajo.
Pasos siguientes
Después de crear un modelo de clasificación de texto personalizado, puede pasar a:
Cuando empiece a crear sus propios proyectos de clasificación de texto personalizado, use los artículos de procedimientos para obtener información detallada sobre el desarrollo del modelo: