Creación y entrenamiento de un modelo de clasificación personalizado
Este contenido se aplica a:![]() v4.0 (versión preliminar) | Versiones anteriores:
v4.0 (versión preliminar) | Versiones anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)
Importante
El modelo de clasificación personalizado se encuentra actualmente en versión preliminar pública. Antes de la disponibilidad general (GA), las características, los enfoques y los procesos podrían cambiar en función de los comentarios de los usuarios.
Los modelos de clasificación personalizados pueden clasificar cada página en un archivo de entrada para identificar uno o varios documentos dentro. Los modelos de clasificación también pueden identificar varios documentos o varias instancias de un único documento en el archivo de entrada. Los modelos personalizados de Documento de inteligencia requieren tan solo cinco documentos de entrenamiento por clase de documento para empezar. Para empezar a entrenar un modelo de clasificación personalizado, necesita al menos cinco documentos para cada clase y dos clases de documentos.
Requisitos de entrada del modelo de clasificación personalizado
Asegúrese de que el conjunto de datos de entrenamiento cumpla con los requisitos de entrada para Documento de inteligencia.
Formatos de archivos admitidos:
Modelo PDF Imagen: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLeer ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Documento general ✔ ✔ Creada previamente ✔ ✔ Extracción personalizada ✔ ✔ Clasificación personalizada ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Para obtener unos resultados óptimos, proporcione una foto clara o una digitalización de alta calidad por documento.
Para PDF y TIFF, se pueden procesar hasta 2000 páginas (con una suscripción de nivel gratis, solo se procesan las dos primeras páginas).
El tamaño de archivo para analizar documentos es de 500 MB para el nivel de pago (S0) y de
4MB para el nivel gratuito (F0).Las imágenes deben tener unas dimensiones entre 50 x 50 píxeles y 10 000 x 10 000 píxeles.
Si los archivos PDF están bloqueados con contraseña, debe desbloquearlos antes de enviarlos.
La altura mínima del texto que se va a extraer es de 12 píxeles para una imagen de 1024 x 768 píxeles. Esta dimensión corresponde aproximadamente a
8puntos de texto a 150 puntos por pulgada (PPP).Para el entrenamiento de modelos personalizados, el número máximo de páginas para los datos de entrenamiento es 500 para el modelo de plantilla personalizada y 50 000 para el modelo neuronal personalizado.
Para el entrenamiento de modelos de extracción personalizados, el tamaño total de los datos de entrenamiento es de 50 MB para el modelo de plantilla y
1GB para el modelo neuronal.Para el entrenamiento del modelo de clasificación personalizada, el tamaño total de los datos de entrenamiento es de
1GB con un máximo de 10 000 páginas. Para 2024-07-31-preview y versiones posteriores, el tamaño total de los datos de entrenamiento se2GB con un máximo de 10 000 páginas.
Sugerencias sobre los datos de aprendizaje
Siga estas sugerencias para optimizar aún más el conjunto de datos para el entrenamiento:
Si es posible, use documentos PDF de texto en lugar de documentos basados en imágenes. Los archivos PDF digitalizados se tratan como imágenes.
Si las imágenes de los formularios son de menor calidad, use un conjunto de datos más grande (con entre 10 y 15 imágenes, por ejemplo).
Carga de los datos de aprendizaje
Cuando haya reunido el conjunto de formularios o documentos para el entrenamiento, debe cargarlo en un contenedor de Azure Blob Storage. Si no sabe cómo crear una cuenta de almacenamiento de Azure con un contenedor, siga el inicio rápido de Azure Storage para Azure Portal. Puede usar el plan de tarifa gratis (F0) para probar el servicio y actualizarlo más adelante a un plan de pago para producción. Si el conjunto de datos se organiza como carpetas, conserve esa estructura, ya que Studio puede usar los nombres de carpeta para las etiquetas para simplificar el proceso de etiquetado.
Creación de un proyecto de clasificación en Documento de inteligencia de Studio
Documento de inteligencia de Studio proporciona y organiza todas las llamadas API necesarias para completar el conjunto de datos y entrenar el modelo.
Para empezar, vaya a Documento de inteligencia Studio. La primera vez que use Studio, debe inicializar la suscripción, el grupo de recursos y el recurso. A continuación, siga los requisitos previos para proyectos personalizados para configurar Studio para acceder a su conjunto de datos de entrenamiento.
En Studio, seleccione el icono Modelo de clasificación personalizados en la sección de los modelos personalizados de la página y seleccione el botón Crear un proyecto.
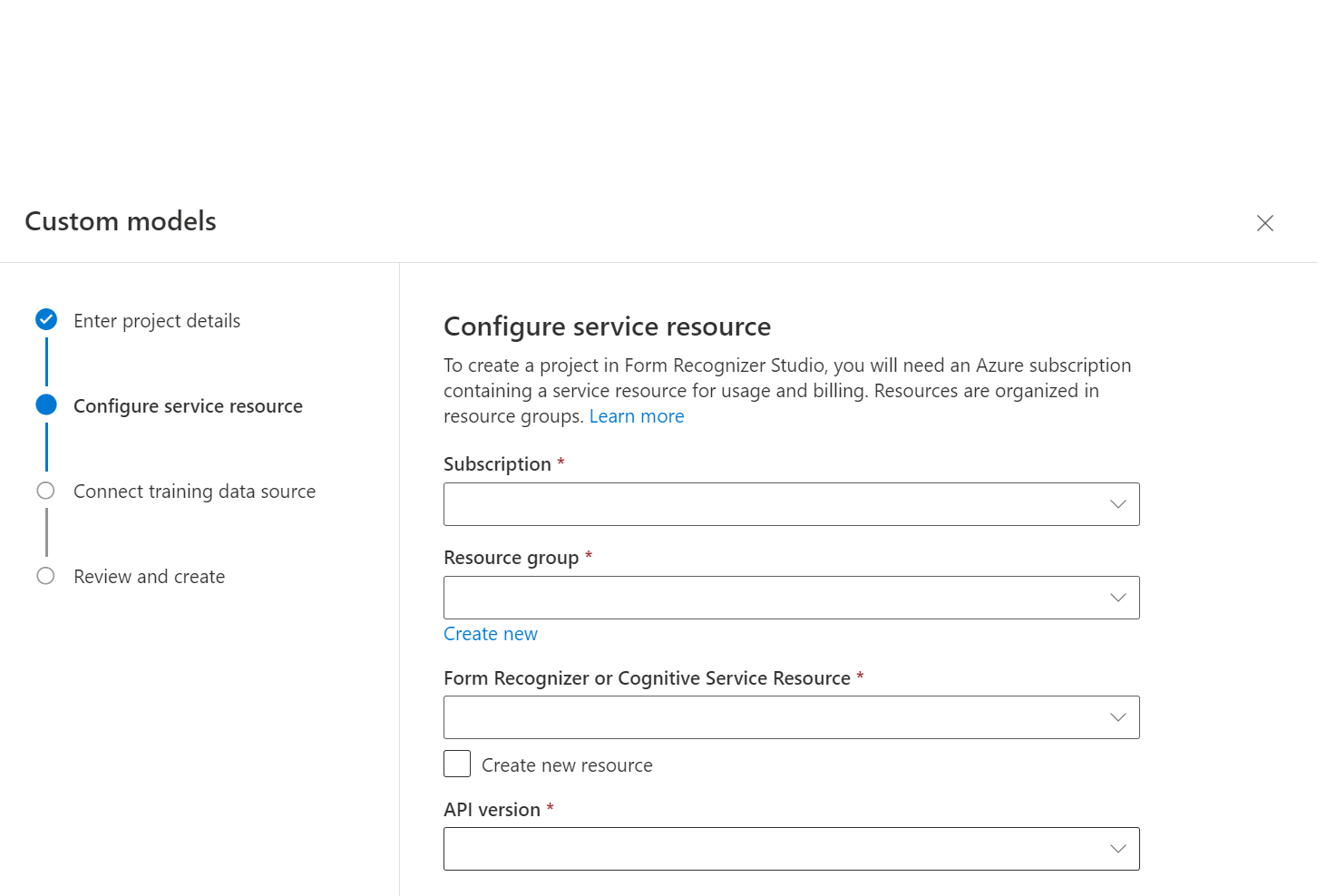
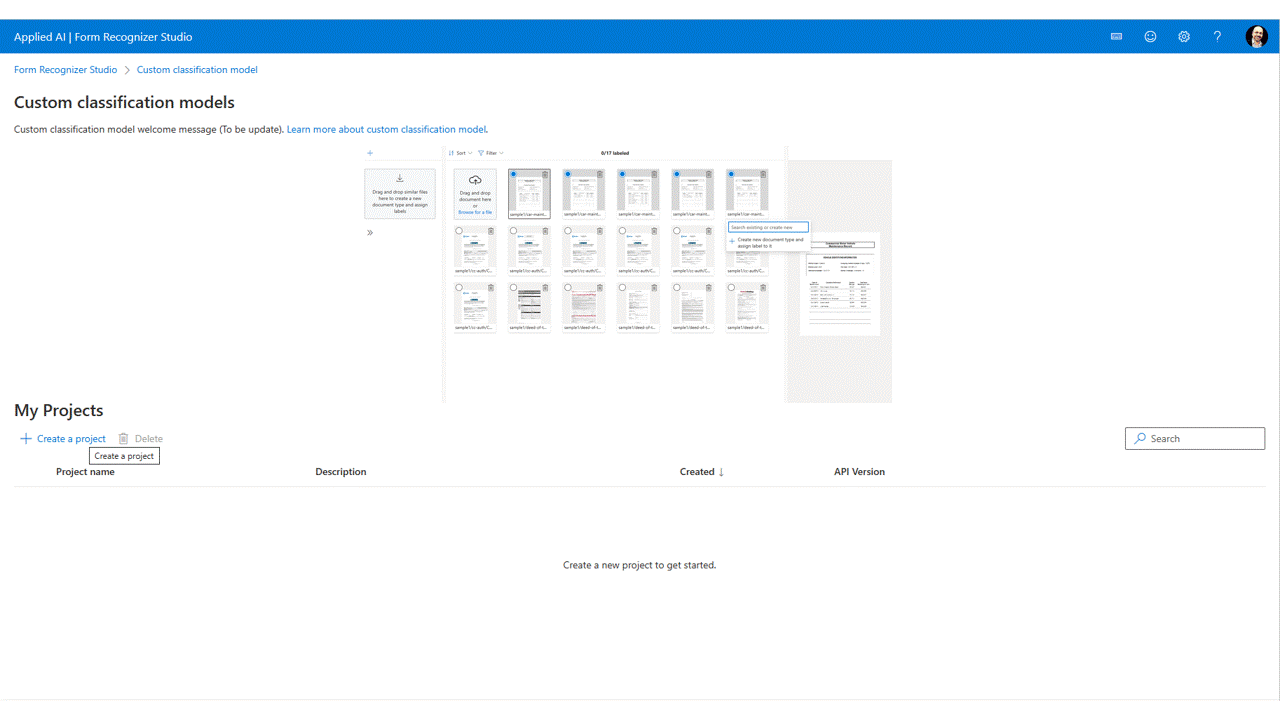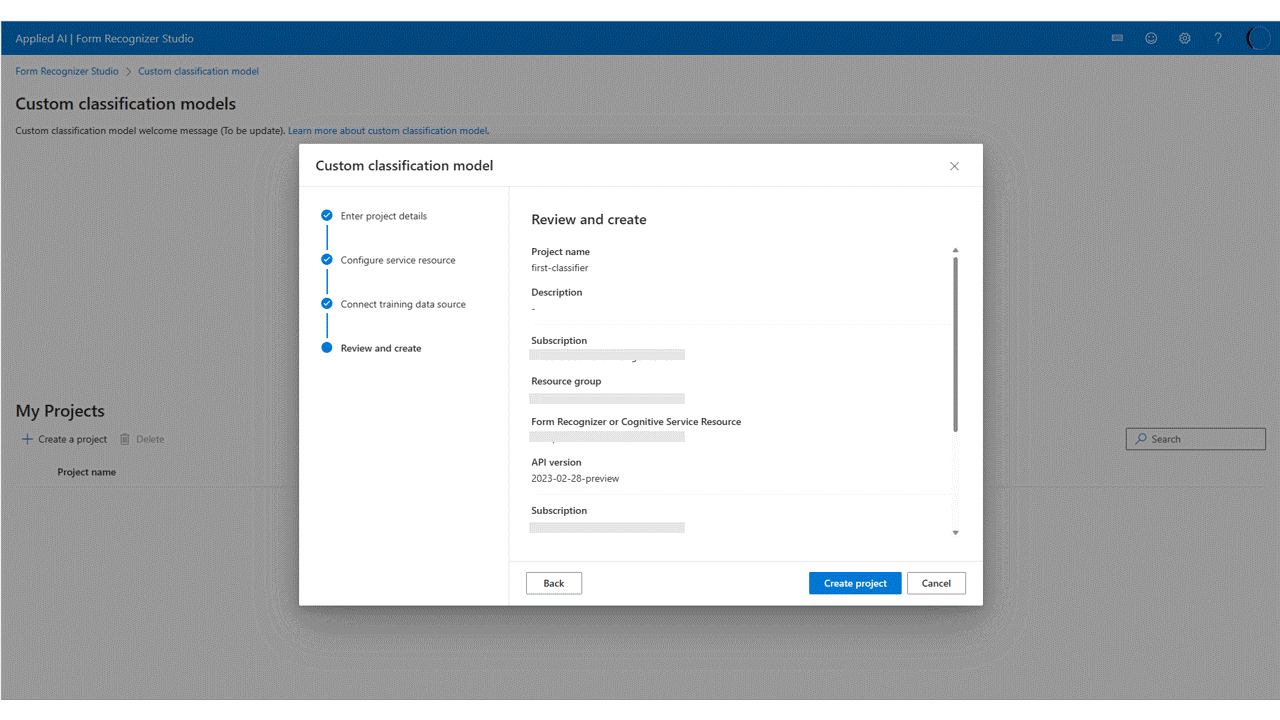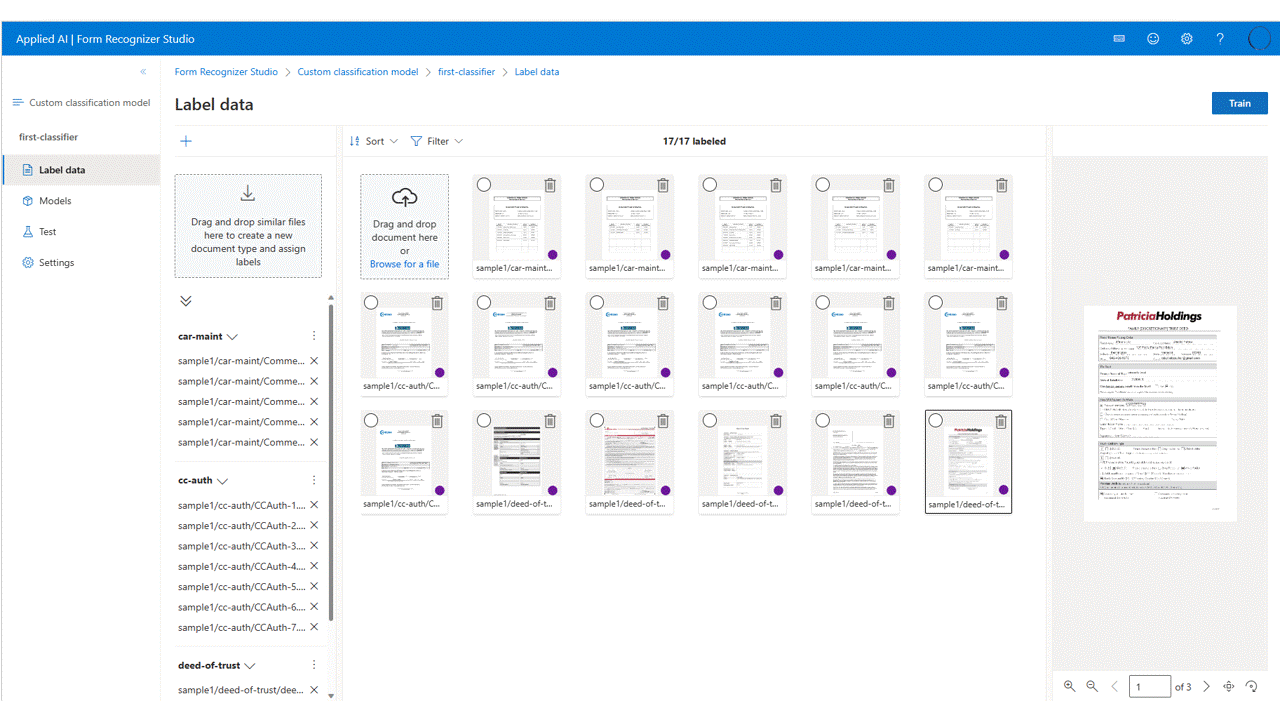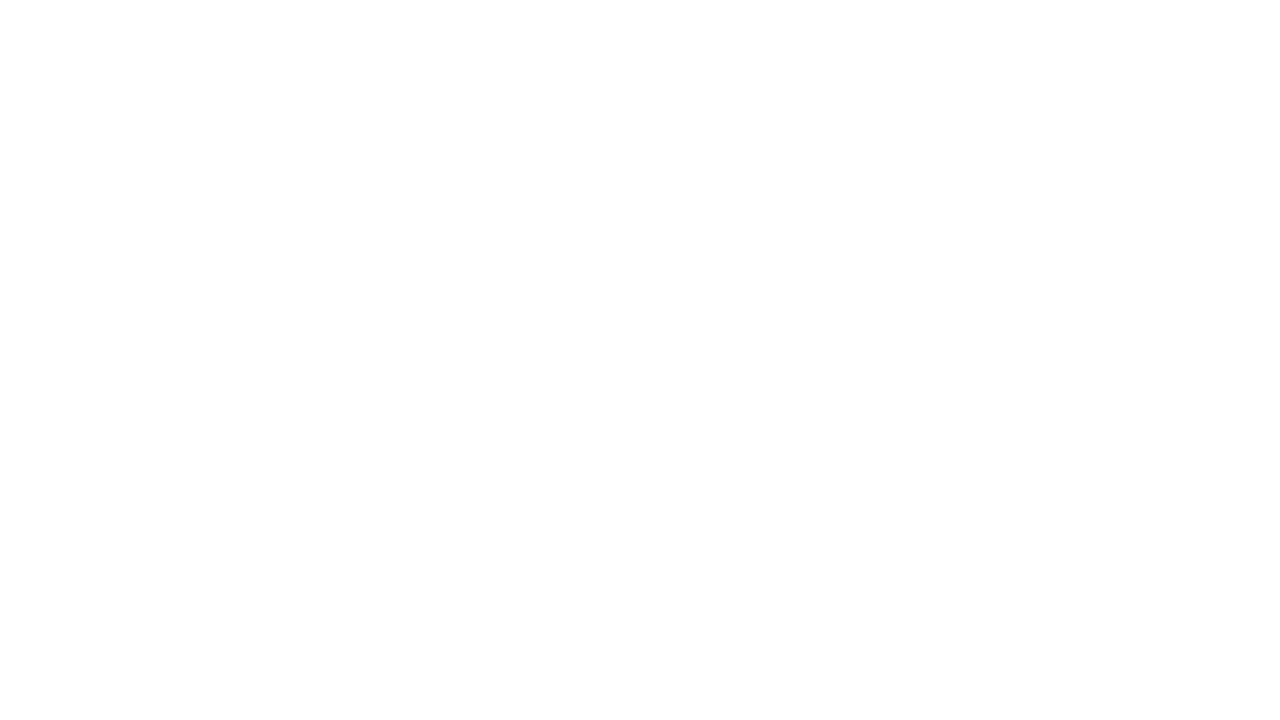
En el cuadro de diálogo
Create Project, proporcione un nombre para el proyecto, opcionalmente una descripción, y seleccione Continuar.A continuación, elija o seleccione Crear un recurso de Document Intelligence antes de continuar.
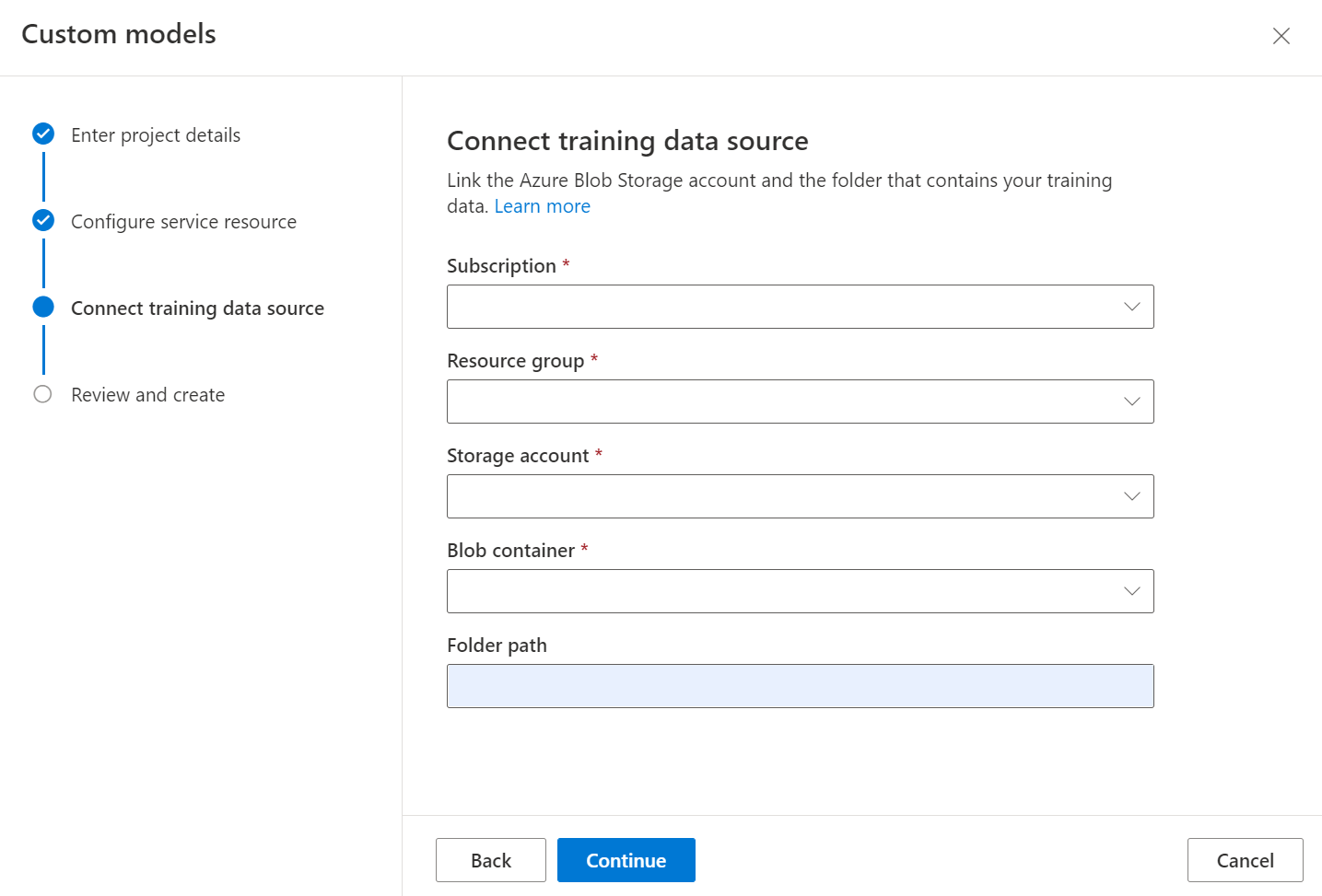
A continuación, seleccione la cuenta de almacenamiento que usó para cargar el conjunto de datos que desea utilizar para entrenar el modelo personalizado. La ruta de acceso a la carpeta debe estar vacía si los documentos de entrenamiento están en la raíz del contenedor. Si los documentos están en una subcarpeta, escriba la ruta de acceso relativa de la raíz del contenedor en el campo Ruta de acceso a la carpeta. Una vez configurada la cuenta de almacenamiento, seleccione Continuar.
Importante
Puede organizar el conjunto de datos de entrenamiento por carpetas en las que el nombre de la carpeta es la etiqueta o clase de los documentos o puede crear una lista plana de documentos a los que puede asignar una etiqueta en Studio.
El entrenamiento de un clasificador personalizado requiere la salida del modelo de diseño para cada documento del conjunto de datos. Ejecute el diseño en todos los documentos antes del proceso de entrenamiento del modelo.
Por último, revise la configuración del proyecto y seleccione Crear proyecto para crear un nuevo proyecto. Ahora debería estar en la ventana de etiquetado y ver los archivos del conjunto de datos enumerados.
Etiquetado de los datos
En el proyecto, solo tiene que etiquetar cada documento con la etiqueta de clase adecuada.
Verá los archivos que cargó para almacenar en la lista de archivos, listos para etiquetar. Tiene algunas opciones para etiquetar el conjunto de datos.
Si los documentos se organizan en carpetas, Studio le pedirá que use los nombres de carpeta como etiquetas. Este paso simplifica el etiquetado hasta una sola selección.
Para asignar una etiqueta a un documento, seleccione en la
add label selection markasignar una etiqueta.Pulse Control para seleccionar varios documentos para asignar una etiqueta
Ahora debe tener todos los documentos del conjunto de datos etiquetados. Si observa la cuenta de almacenamiento, encontrará los archivos .ocr.json que corresponden a cada documento del conjunto de datos de entrenamiento y un archivo class-name.jsonl nuevo para cada clase etiquetada. Este conjunto de datos de entrenamiento se envía para entrenar el modelo.
Entrenamiento de un modelo
Con el conjunto de datos etiquetado, ya está listo para entrenar el modelo. Seleccione el botón para entrenar en la esquina superior derecha.
En el cuadro de diálogo para entrenar el modelo, proporcione un identificador de clasificador único y, opcionalmente, una descripción. El identificador del clasificador acepta un tipo de datos de cadena.
Seleccione Entrenar para iniciar el proceso de entrenamiento.
Los modelos de clasificación se entrenan en unos minutos.
Vaya al menú Modelos para ver el estado de la operación de entrenamiento.
Prueba del modelo
Una vez completado el entrenamiento del modelo, puede probar el modelo seleccionándolo en la página de la lista de modelos.
Seleccione el modelo y haga clic en el botón Probar.
Agregue un nuevo archivo explorando un archivo o colocando un archivo en el selector de documentos.
Con un archivo seleccionado, elija el botón Analizar para probar el modelo.
Los resultados del modelo se muestran con la lista de documentos identificados, una puntuación de confianza para cada documento identificado y el intervalo de páginas de cada uno de los documentos identificados.
Valide el modelo evaluando los resultados de cada documento identificado.
Entrenamiento de un clasificador personalizado mediante el SDK o la API
Studio organiza las llamadas API para que entrene un clasificador personalizado. El conjunto de datos de entrenamiento del clasificador requiere la salida de la API de diseño que coincide con la versión de la API para el modelo de entrenamiento. El uso de los resultados de diseño de una versión de API anterior puede dar lugar a un modelo con menor precisión.
Studio genera los resultados de diseño del conjunto de datos de entrenamiento si el conjunto de datos no contiene resultados de diseño. Al usar la API o el SDK para entrenar un clasificador, debe agregar los resultados de diseño a las carpetas que contienen los documentos individuales. Los resultados del diseño deben estar en el formato de la respuesta de la API al llamar directamente al diseño. El modelo de objetos del SDK es diferente. Asegúrese de que el layout results son los resultados de la API y no el SDK response.
Solución de problemas
El modelo de clasificación requiere resultados del modelo de diseño para cada documento de entrenamiento. Si no proporciona los resultados del diseño, Studio intenta ejecutar el modelo de diseño para cada documento antes de entrenar el clasificador. Este proceso está limitado y puede dar lugar a una respuesta 429.
En Studio, antes de entrenar con el modelo de clasificación, ejecute el modelo de diseño en cada documento y cárguelo en la misma ubicación que el documento original. Una vez agregados los resultados del diseño, podrá entrenar el modelo clasificador con los documentos.