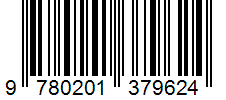Funcionalidades del complemento Documento de inteligencia
Artículo
Importante
Las versiones preliminares públicas de Documento de inteligencia proporcionan acceso anticipado a las características que están en desarrollo activo. Antes de la disponibilidad general (GA), las características, los enfoques y los procesos podrían cambiar en función de los comentarios de los usuarios.
La versión preliminar pública de las bibliotecas cliente de Documento de inteligencia tiene como valor predeterminado la versión de la API de REST 2024-07-31-preview.
La versión preliminar pública 2024-07-31-preview solo está disponible en las siguientes regiones de Azure. Tenga en cuenta que el modelo generativo personalizado (extracción de campos del documento) en AI Studio solo está disponible en la región Centro-norte de EE. UU.:
Este de EE. UU.
Oeste de EE. UU. 2
Oeste de Europa
Centro-Norte de EE. UU
Este contenido se aplica a:v4.0 (versión preliminar) | versiones anteriores:v3.1 (GA)
Documento de inteligencia es compatible con capacidades de análisis más sofisticadas y modulares. Use las características del complemento para ampliar los resultados para incluir más características extraídas de los documentos. Algunas características del complemento conllevan un costo adicional. Estas características opcionales se pueden habilitar y deshabilitar en función del escenario de extracción de documentos. Para habilitar una característica, agregue el nombre de la característica asociada a la propiedad de cadena de consulta features. Puede habilitar más de una característica de complemento en una solicitud proporcionando una lista separada por comas de características. Las siguientes funcionalidades de complemento están disponibles para 2023-07-31 (GA) y versiones posteriores.
No todas las funcionalidades del complemento son compatibles con todos los modelos. Para obtener más información, veaextracción de datos del modelo.
Actualmente no se admiten funcionalidades de complemento para los tipos de archivo de Microsoft Office.
Document Intelligence admite características opcionales que se pueden habilitar y deshabilitar en función del escenario de extracción de documentos. Las siguientes funcionalidades de complemento están disponibles para 2023-10-31-preview y versiones posteriores:
La implementación de campos de consulta en la API 2023-10-30-preview es diferente de la última versión preliminar. La nueva implementación es menos costosa y funciona bien con documentos estructurados.
✱ Complemento: los campos de consulta tienen un precio diferente al de las otras características del complemento. Consulte Precios para obtener detalles.
Formatos de archivos admitidos
PDF
Imágenes: JPEG/JPG, PNG, BMP, TIFF, HEIF
✱ Los archivos de Microsoft Office no se admiten actualmente.
Extracción de alta resolución
La tarea de reconocer texto pequeño en documentos de gran tamaño, como dibujos de ingeniería, es un desafío. A menudo, el texto se mezcla con otros elementos gráficos y tiene fuentes, tamaños y orientaciones variables. Además, el texto puede dividirse en distintas partes o estar conectado con otros símbolos. Documento de inteligencia ahora admite la extracción de contenido de estos tipos de documentos con la funcionalidad ocr.highResolution. Para mejorar la calidad de la extracción de contenido de documentos A1, A2 y A3, habilite esta funcionalidad de complemento.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
La funcionalidad ocr.formula extrae todas las fórmulas identificadas, como ecuaciones matemáticas, de la colección formulas como un objeto de nivel superior en content. Dentro de content, las fórmulas detectadas se representan como :formula:. Cada entrada de esta colección representa una fórmula que incluye el tipo de fórmula como inline o display, y su representación LaTeX como value junto con sus coordenadas polygon. Inicialmente, las fórmulas aparecen al final de cada página.
Nota:
La puntuación confidence está codificada de forma rígida.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Extracción de propiedades de fuente
La funcionalidad ocr.font extrae todas las propiedades de fuente del texto extraído de la colección styles como un objeto de nivel superior en content. Cada objeto de estilo especifica una sola propiedad de fuente, el intervalo de texto al que se aplica y su puntuación de confianza correspondiente. La propiedad de estilo existente se amplía con más propiedades de fuente, como similarFontFamily para la fuente del texto, fontStyle para estilos como cursiva y normal, fontWeight para negrita o normal, color para color del texto y backgroundColor para el color del cuadro de límite de texto.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
La capacidad ocr.barcode extrae todos los códigos de barras identificados en la barcodes como objeto de nivel superior en content. Dentro de contentlos códigos de barras detectados se representan como :barcode:. Cada entrada de esta colección representa un código de barras e incluye el tipo de código de barras como kind y el contenido de código de barras incrustado como value junto con sus coordenadas polygon. Inicialmente, los códigos de barras aparecen al final de cada página. El confidence está codificado como 1.
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
Al agregar la característica languages a la solicitud de analyzeResult, se predice el idioma principal detectado para cada línea de texto junto con el confidence de la colección languages en analyzeResult.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
La funcionalidad de PDF utilizable en búsquedas le permite convertir un PDF analógico, como los archivos PDF de imágenes escaneadas, en un PDF con texto insertado. El texto insertado permite la búsqueda profunda de texto dentro del contenido extraído del PDF mediante la superposición de las entidades de texto detectadas sobre los archivos de imagen.
Importante
Actualmente, la funcionalidad de PDF utilizable en búsquedas solo es compatible con el modelo de lectura de OCR prebuilt-read. Al usar esta característica, especifique modelId como prebuilt-read, ya que otros tipos de modelo devolverán un error para esta versión preliminar.
PDF utilizable en búsquedas se incluye con el modelo 2024-07-31-preview prebuilt-read sin costo de uso para el consumo general de PDF.
Uso de PDF utilizable en búsquedas
Para usar PDF utilizable en búsquedas, envíe una solicitud POST mediante la operación Analyze y especifique el formato de salida como pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Una vez que se complete la operación Analyze, realice una solicitud GET para recuperar los resultados de la operación Analyze.
Cuando se complete correctamente, el PDF se puede recuperar y descargar como application/pdf. Esta operación permite la descarga directa del formato de texto insertado de PDF en lugar de JSON codificado en Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Pares clave-valor.
En versiones anteriores de la API, el modelo de prebuilt-document extrajo pares clave-valor de formularios y documentos. Con la adición de la característica keyValuePairs al diseño precompilado, el modelo de diseño ahora genera los mismos resultados.
Los pares clave-valor son intervalos específicos dentro del documento que identifican una etiqueta o una clave y su respuesta o valor asociados. De forma estructurada, estos pares pueden ser la etiqueta y el valor que ha escrito el usuario para ese campo. En una documentación no estructurada, pueden ser la fecha en la que se ejecutó un contrato según el mensaje de texto de un párrafo. El modelo de IA está entrenado para extraer claves y valores identificables basados en una amplia variedad de tipos de documentos, formatos y estructuras.
Las claves también pueden existir de forma aislada cuando el modelo detecta que existe una clave, sin ningún valor asociado, o cuando se procesan campos opcionales. Por ejemplo, un campo de segundo nombre se puede dejar en blanco en un formulario en algunos casos. Los pares clave-valor son intervalos de texto contenidos en el documento. Para documentos donde el mismo valor se describe de diferentes maneras, por ejemplo, cliente/usuario, la clave asociada es cliente o usuario (según el contexto).
Los campos de consulta son una funcionalidad de complemento para ampliar el esquema extraído de cualquier modelo precompilado o definir un nombre de clave específico cuando el nombre de clave es variable. Para usar campos de consulta, establezca las características en queryFields y proporcione una lista separada por comas de nombres de campo en la propiedad queryFields.
Documento de inteligencia ahora es compatible con las extracciones de campos de consulta. Con la extracción de campos de consulta, puede agregar campos al proceso de extracción mediante una solicitud de consulta sin necesidad de entrenamiento adicional.
Use campos de consulta cuando necesite ampliar el esquema de un modelo precompilado o personalizado o necesite extraer algunos campos con la salida del diseño.
Los campos de consulta son una funcionalidad de complemento Premium. Para obtener los mejores resultados, defina los campos que desea extraer mediante "Camel Case" o "Pascal Case" para nombres de campo de varias palabras.
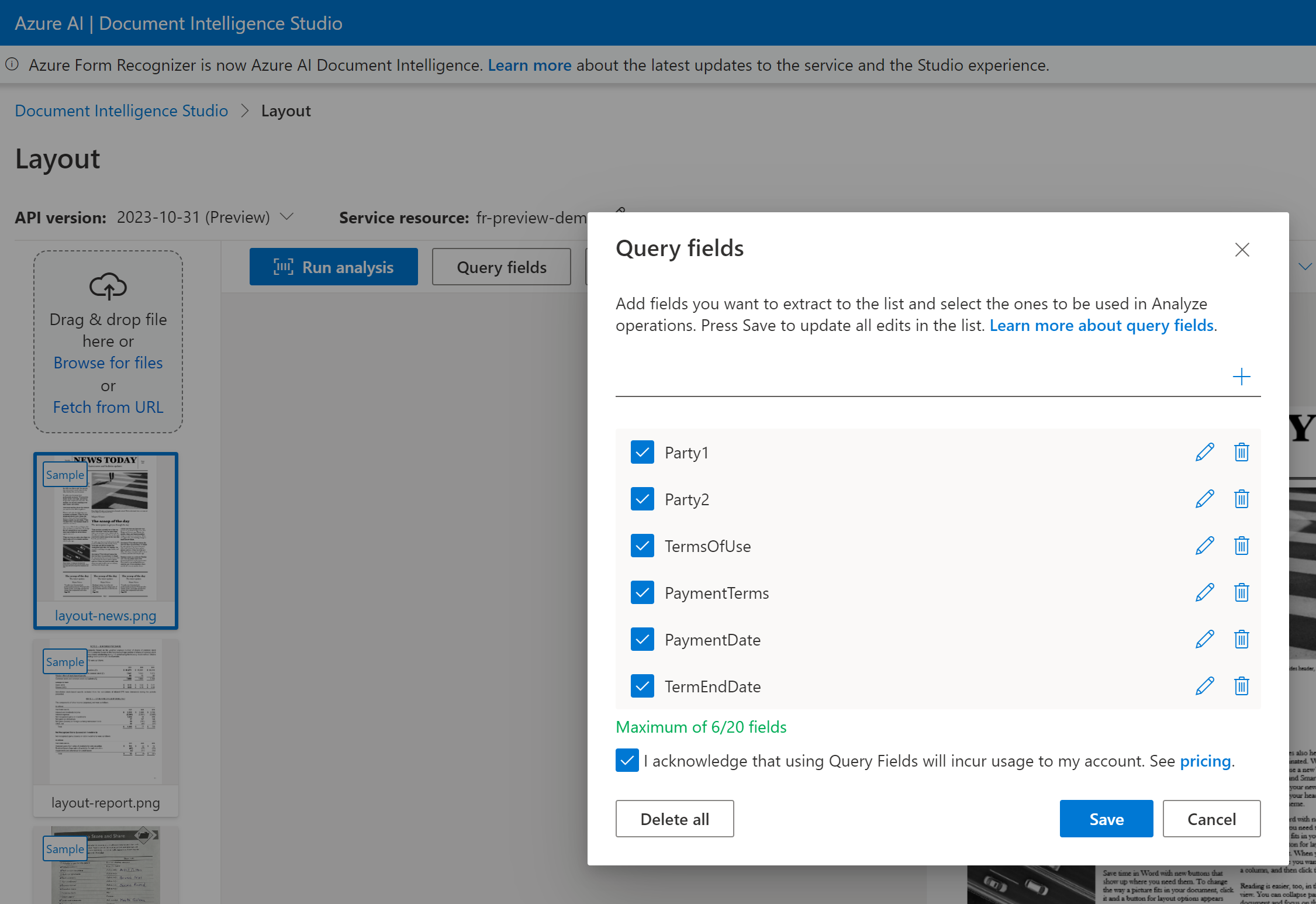
Los campos de consulta admiten un máximo de 20 campos por solicitud. Si el documento contiene un valor para el campo, se devuelve el campo y el valor.
Esta versión tiene una nueva implementación de la funcionalidad de campos de consulta que tiene un precio inferior a la implementación anterior y que se debería validar.
Nota:
La extracción de campos de consulta de Document Intelligence Studio está disponible actualmente con los modelos Layout y Prebuilt 2024-02-29-preview2023-10-31-preview API y versiones posteriores, excepto los modelos de US tax (W2, 1098s y 1099s).
Extracción de campos de consulta
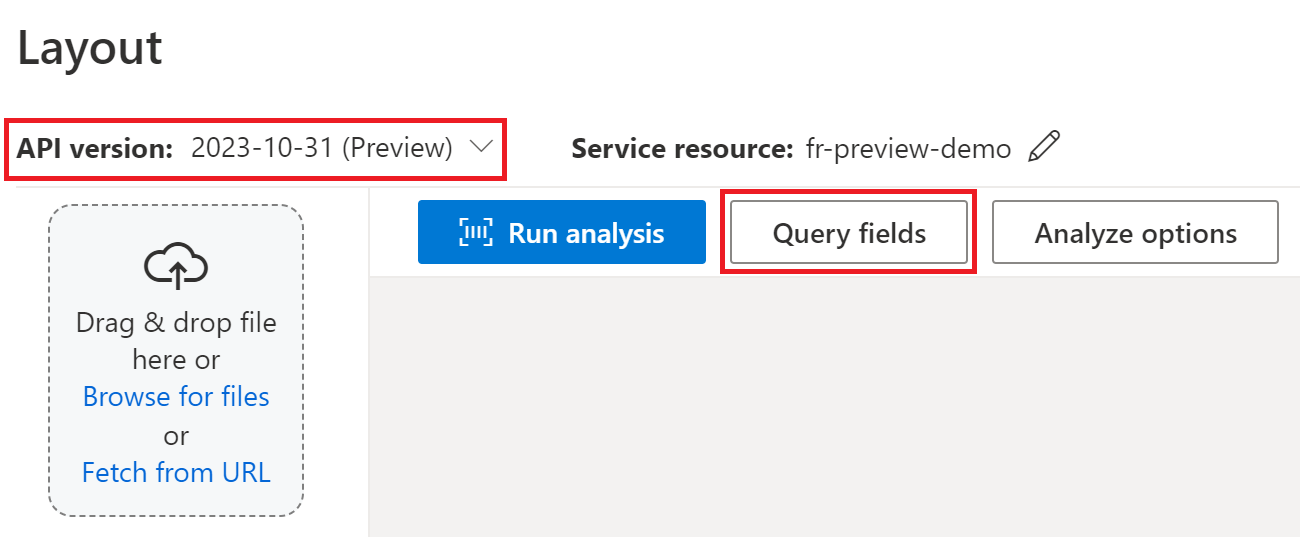
Para la extracción de campos de consulta, especifique los campos que desea extraer y Document Intelligence analizará el documento en consecuencia. Este es un ejemplo:
Si está procesando un contrato en Document Intelligence Studio, use las versiones 2024-02-29-preview o 2023-10-31-preview:
Puede pasar una lista de etiquetas de campo como Party1, Party2, TermsOfUse, PaymentTerms, PaymentDate y TermEndDate como parte de la solicitud analyze document.
Documento de inteligencia es capaz de analizar y extraer los datos de campo y devolver los valores en una salida JSON estructurada.
Además de los campos de consulta, la respuesta incluye texto, tablas, marcas de selección y otros datos pertinentes.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")