Inicio rápido: Creación de un detector de objetos con el sitio web de Custom Vision
En este inicio rápido, aprenderá a usar el sitio web de Custom Vision para crear un modelo de detector de objetos. Una vez que cree un modelo, puede probarlo con nuevas imágenes e integrarlo en su propia aplicación de reconocimiento de imágenes.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Prerrequisitos
- Un conjunto de imágenes con el que entrenar el modelo de detector. Puede usar el conjunto de imágenes de ejemplo en GitHub. O bien, puede elegir sus propias imágenes con las sugerencias que se indican a continuación.
- Un explorador web compatible
Creación de recursos de Custom Vision
Para usar Custom Vision Service, tendrá que crear recursos de entrenamiento y predicción de Custom Vision en Azure Portal. Para ello, en Azure Portal rellene la ventana del cuadro de diálogo de la página Create Custom Vision (Crear recurso de Custom Vision) para crear un recurso de entrenamiento y predicción.
Creación de un nuevo proyecto
En el explorador web, vaya a la página web de Custom Vision y seleccione Sign in (Iniciar sesión). Inicie sesión con la misma cuenta que usó para iniciar sesión en Azure Portal.
Para crear su primer proyecto, seleccione New Project (Nuevo proyecto). Aparecerá el cuadro de diálogo Crear nuevo proyecto.
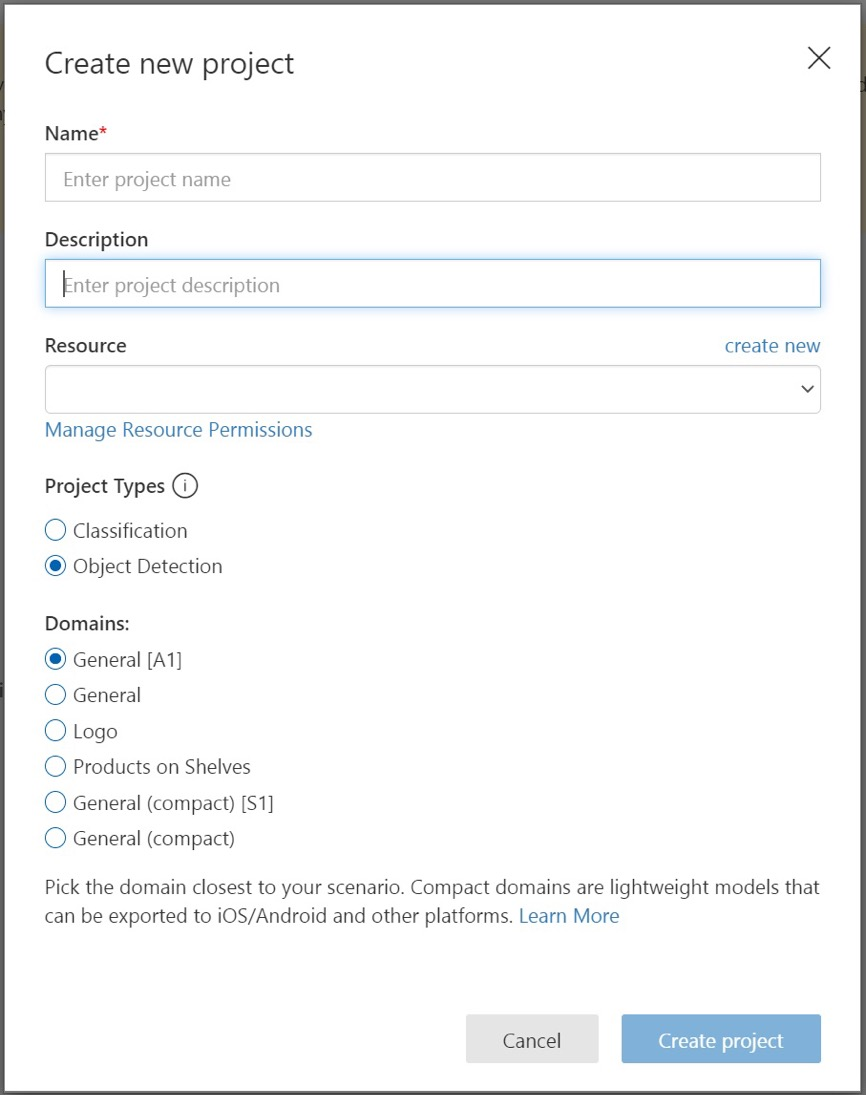
Escriba un nombre y una descripción para el proyecto. Después, seleccione el recurso de aprendizaje de Custom Vision. Si la cuenta con la que ha iniciado sesión está asociada a una cuenta de Azure, el menú desplegable Recursos mostrará todos los recursos compatibles de Azure.
Nota:
Si no hay ningún recurso disponible, confirme que ha iniciado sesión en customvision.ai con la misma cuenta que usó para iniciar sesión en Azure Portal. Además, confirme que el directorio seleccionado en el sitio web de Custom Vision es el mismo que el de Azure Portal donde se encuentran los recursos de Custom Vision. En ambos sitios, puede seleccionar el directorio en el menú de cuentas desplegable de la esquina superior derecha de la pantalla.
En el
En Project Types (Tipos de proyecto), seleccione Object Detection (Detección de objetos).
A continuación, seleccione uno de los dominios disponibles. Cada dominio optimiza el detector para determinados tipos de imágenes, como se describe en la tabla siguiente. Si lo desea, puede cambiar el dominio más adelante.
Domain Propósito General Optimizado para una amplia variedad de tareas de detección de objetos. Si ninguno de los otros dominios es adecuado o si no está seguro de cuál elegir, seleccione el dominio General. Logotipo Optimizado para buscar logotipos de marca en imágenes. Productos en las estanterías Optimizado para detectar y clasificar los productos que están en las estanterías. Dominios compactos Optimizados para las restricciones de detección de objetos en tiempo real en dispositivos móviles. Los modelos generados por los dominios compactos se pueden exportar para ejecutarse localmente. Por último, seleccione Create project (Crear proyecto).
Elección de las imágenes de entrenamiento
Como mínimo, se recomienda que use 30 imágenes por etiqueta en el conjunto de entrenamiento inicial. También conviene recopilar algunas imágenes adicionales para probar el modelo una vez que está entrenado.
Para entrenar el modelo de forma eficaz, use imágenes con variedad visual. Seleccione imágenes que varíen en:
- ángulos de cámara
- iluminación
- background
- estilo visual
- sujetos individuales o grupos
- tamaño
- type
Además, asegúrese de que todas las imágenes de entrenamiento cumplen los criterios siguientes:
- formato .jpg, .png, .bmp o .gif
- tienen menos de 6 MB de tamaño (4 MB en el caso de imágenes de predicción)
- tienen más de 256 píxeles en el borde más corto. Custom Vision Service escalará verticalmente y de forma automática todas las imágenes que sean más cortas
Carga y etiquetado de imágenes
En esta sección cargará y etiquetará manualmente imágenes para ayudar a entrenar el detector.
Para agregar imágenes, seleccione Add images (Agregar imágenes) y, después, Browse local files (Examinar archivos locales). Seleccione Open (Abrir) para cargar las imágenes.
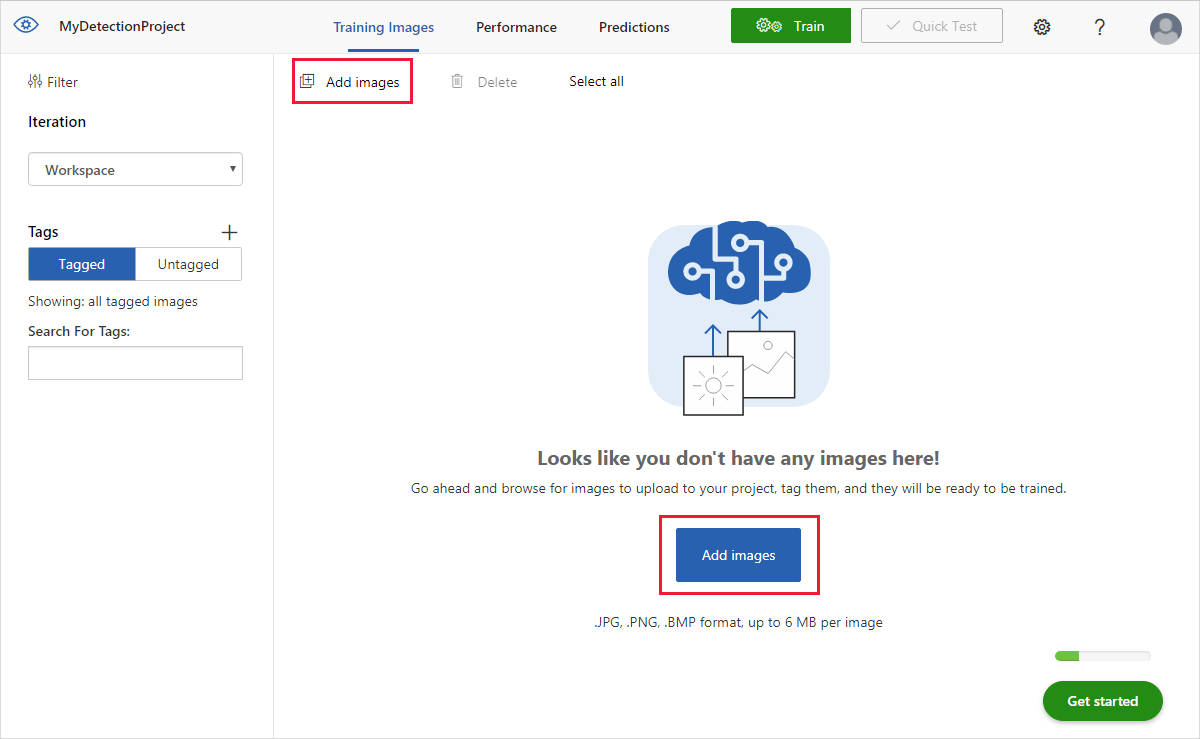
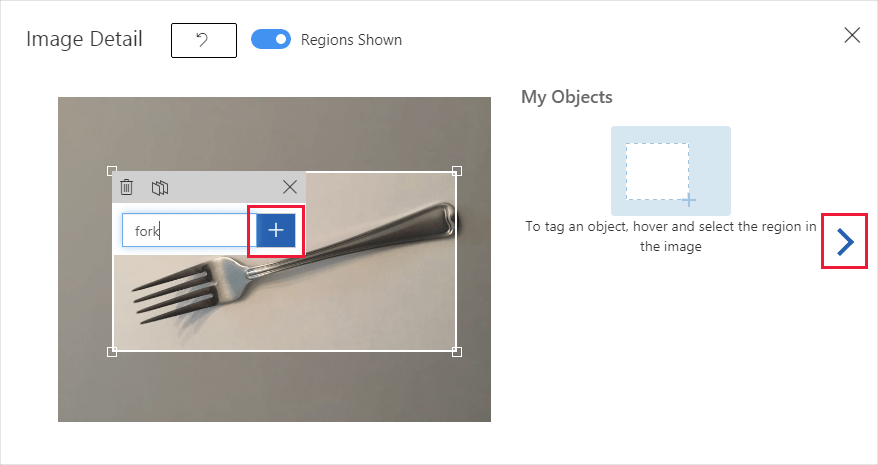
Verá las imágenes cargadas en la sección Untagged (Sin etiqueta) de la interfaz de usuario. El siguiente paso es etiquetar manualmente los objetos que quiere que aprenda a reconocer el detector. Seleccione la primera imagen para abrir la ventana del cuadro de diálogo de etiquetado.
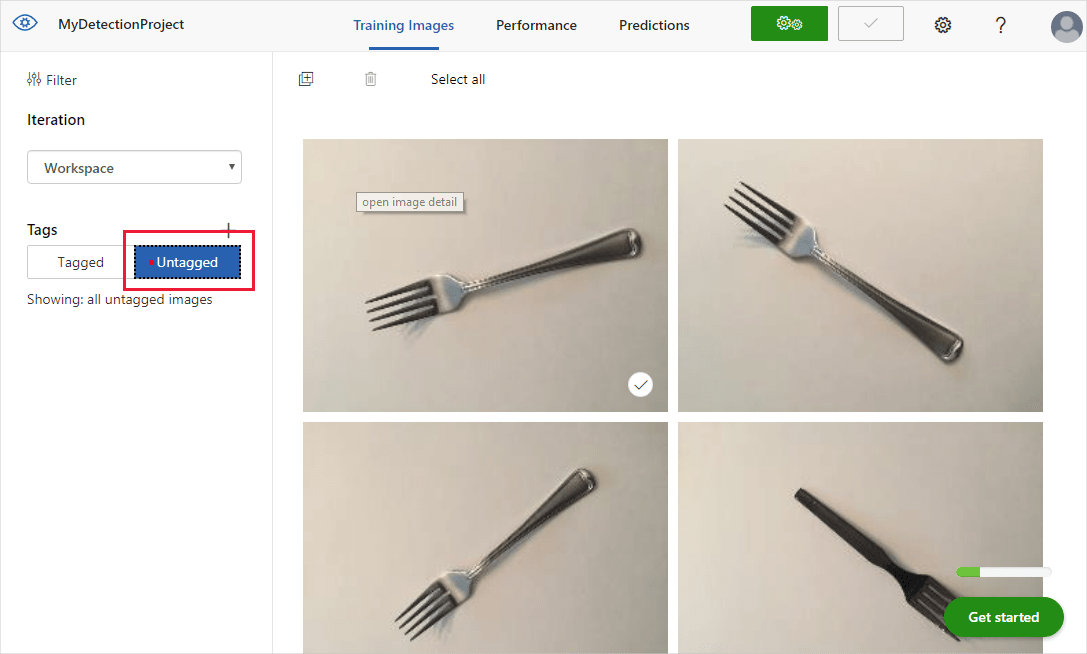
Seleccione y arrastre un rectángulo alrededor del objeto de la imagen. A continuación, escriba un nuevo nombre de etiqueta con el botón + o seleccione una etiqueta existente en la lista desplegable. Es importante etiquetar todas las instancias de los objetos que quiera detectar, ya que el detector usa el área de fondo sin etiqueta como ejemplo negativo en el entrenamiento. Cuando haya terminado de etiquetar, haga clic en la flecha de la derecha para guardar las etiquetas y pasar a la siguiente imagen.
Para cargar otro conjunto de imágenes, vuelva a la parte superior de esta sección y repita los pasos.
Entrenamiento del detector
Para entrenar el modelo de detector, seleccione el botón Train (Entrenar). El detector usa todas las imágenes actuales y sus etiquetas para crear un modelo que identifique cada objeto etiquetado. Este proceso puede tardar varios minutos.

El proceso de entrenamiento solo debe llevar unos minutos. Durante este tiempo, se muestra información sobre el proceso de entrenamiento en la pestaña Performance (Rendimiento).
Evaluación del detector
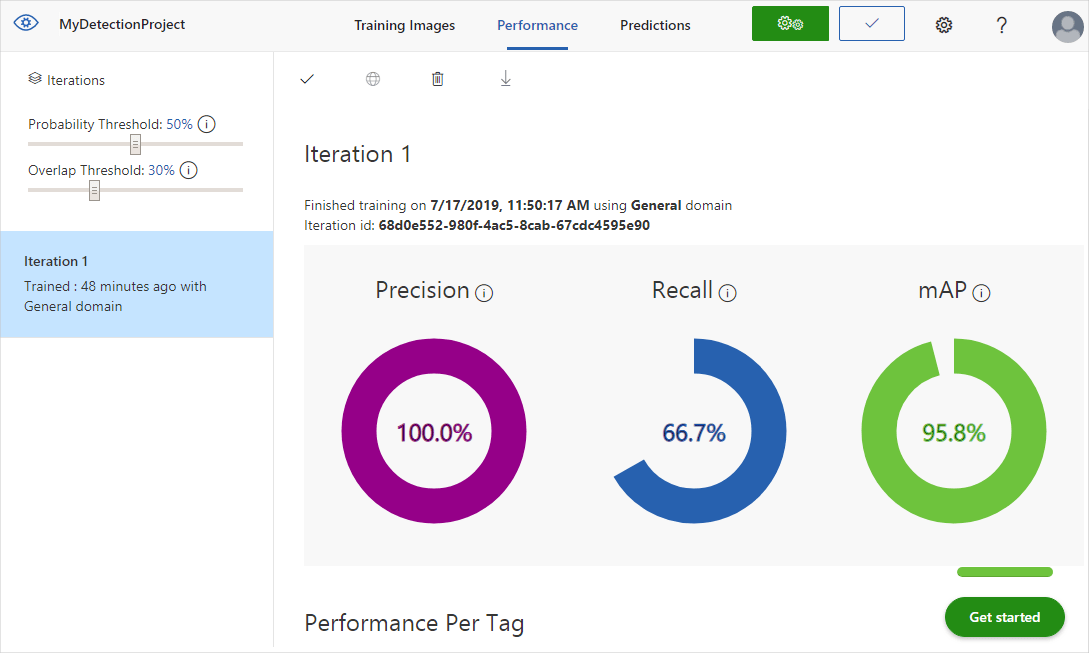
Una vez finalizado el entrenamiento, se calcula y se muestra el rendimiento del modelo. Custom Vision Service usa las imágenes que ha enviado para entrenamiento para calcular la precisión, la coincidencia y la precisión media. La precisión y la coincidencia son dos medidas diferentes de la eficacia de un detector:
- La precisión indica la fracción de las clasificaciones identificadas que fueron correctas. Por ejemplo, si el modelo identificó 100 imágenes como perros y 99 de ellas eran realmente de perros, la precisión sería del 99 %.
- La coincidencia indica la fracción de las clasificaciones reales que se identificaron correctamente. Por ejemplo, si había realmente 100 imágenes de manzanas y el modelo identificó 80 como manzanas, la coincidencia sería del 80 %.
- El promedio de precisión media es el valor promedio de la precisión media. La precisión media es el área de la curva de precisión/recuperación (es decir, la precisión trazada frente a la recuperación para cada predicción realizada).
Umbral de probabilidad
Observe el control deslizante Probability Threshold (Umbral de probabilidad) situado en el panel izquierdo de la pestaña Performance (Rendimiento). Este es el nivel de confianza que debe tener una predicción para que se considere correcta (para los fines de calcular la precisión y la coincidencia).
Al interpretar llamadas de predicción con un umbral alto de probabilidad, tienden a devolver resultados muy precisos pero con una baja coincidencia; las clasificaciones detectadas son correctas, pero muchas siguen sin detectarse. Un umbral bajo de probabilidad tiene el efecto contrario: la mayoría de las clasificaciones reales se detectan, pero hay más falsos positivos en ese conjunto. Teniendo esto en cuenta, debe establecer el umbral de probabilidad según las necesidades específicas de su proyecto. Posteriormente, si va a recibir resultados de predicción en el cliente, debe usar el mismo valor de umbral de probabilidad que el empleado aquí.
Umbral de superposición
El control deslizante Overlap Threshold (Umbral de superposición) sirve para indicar cómo de correcta debe ser una predicción de objeto para que se la considere "correcta" en el entrenamiento. Permite establecer la superposición mínima permitida entre el rectángulo delimitador del objeto predicho y el rectángulo delimitador especificado por el usuario real. Si los cuadros de límite no se superponen en el grado establecido, la predicción no se considerará correcta.
Administración de iteraciones de entrenamiento
Cada vez que entrena al detector, se crea una iteración con sus propias métricas de rendimiento actualizadas. Puede ver todas las iteraciones en el panel izquierdo de la pestaña Performance (Rendimiento). En el panel izquierdo encontrará también el botón Delete (Eliminar), que puede usar para eliminar una iteración si está obsoleta. Cuando se elimina una iteración, elimina las imágenes que están asociadas exclusivamente a ella.
Consulte Uso del modelo con Prediction API para aprender a acceder a los modelos entrenados mediante programación.
Pasos siguientes
En este inicio rápido, ha aprendido a crear y entrenar un modelo de detector de objetos mediante el sitio web de Custom Vision. A continuación, obtenga más información sobre el proceso iterativo de mejora del modelo.