Carga de archivos (C#)
Obtenga información sobre cómo permitir que los usuarios carguen archivos binarios (como documentos Word o PDF) en el sitio web en el que se puedan almacenar en el sistema de archivos del servidor o la base de datos.
Introducción
Todos los tutoriales que hemos examinado hasta ahora han trabajado exclusivamente con datos de texto. Sin embargo, muchas aplicaciones tienen modelos de datos que capturan datos binarios y de texto. Un sitio de citas en línea podría permitir a los usuarios cargar una imagen para asociarla a su perfil. Un sitio web de contratación podría permitir que los usuarios carguen su currículum como un documento de Microsoft Word o PDF.
Trabajar con datos binarios agrega un nuevo conjunto de desafíos. Debemos decidir cómo se almacenan los datos binarios en la aplicación. La interfaz que se usa para insertar nuevos registros debe actualizarse para permitir al usuario cargar un archivo desde su equipo. Además, se deben realizar pasos adicionales para mostrar o proporcionar un medio para descargar los datos binarios asociados de un registro. En este tutorial y los tres siguientes, exploraremos cómo superar estos desafíos. Al final de estos tutoriales, habremos creado una aplicación totalmente funcional que asocia una imagen y un folleto PDF a cada categoría. En este tutorial concreto, veremos diferentes técnicas para almacenar datos binarios y exploraremos cómo permitir a los usuarios cargar un archivo desde su equipo y guardarlo en el sistema de archivos del servidor web.
Nota:
Los datos binarios que forman parte de un modelo de datos de una aplicación se conocen a veces como BLOB, un acrónimo de Binary Large OBject. En estos tutoriales, he elegido usar la terminología "datos binarios", aunque el término BLOB es un sinónimo.
Paso 1: Crear las páginas web de Trabajar con datos binarios
Antes de empezar a explorar los desafíos asociados con la adición de compatibilidad con datos binarios, primero dediquemos un momento a crear las páginas de ASP.NET en nuestro proyecto de sitio web que necesitaremos para este tutorial y los tres siguientes. Empiece agregando una nueva carpeta denominada BinaryData. Después, agregue las siguientes páginas ASP.NET a esa carpeta, asegurándose de asociar cada página a la página maestra Site.master:
Default.aspxFileUpload.aspxDisplayOrDownloadData.aspxUploadInDetailsView.aspxUpdatingAndDeleting.aspx
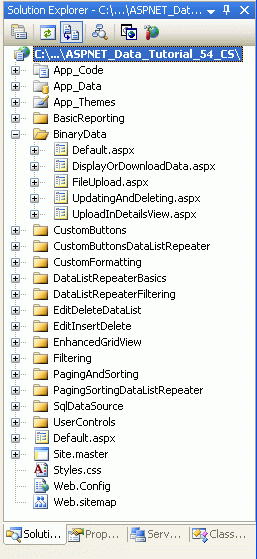
Figura 1: Agregar las páginas de ASP.NET para los tutoriales relacionados con datos binarios
Igual que en las otras carpetas, Default.aspx en la carpeta BinaryData enumerará los tutoriales en su sección. Recuerde que el control de usuario SectionLevelTutorialListing.ascx proporciona esta funcionalidad. Por lo tanto, agregue este control de usuario a Default.aspx arrastrándolo desde el Explorador de soluciones a la vista Diseño de la página.
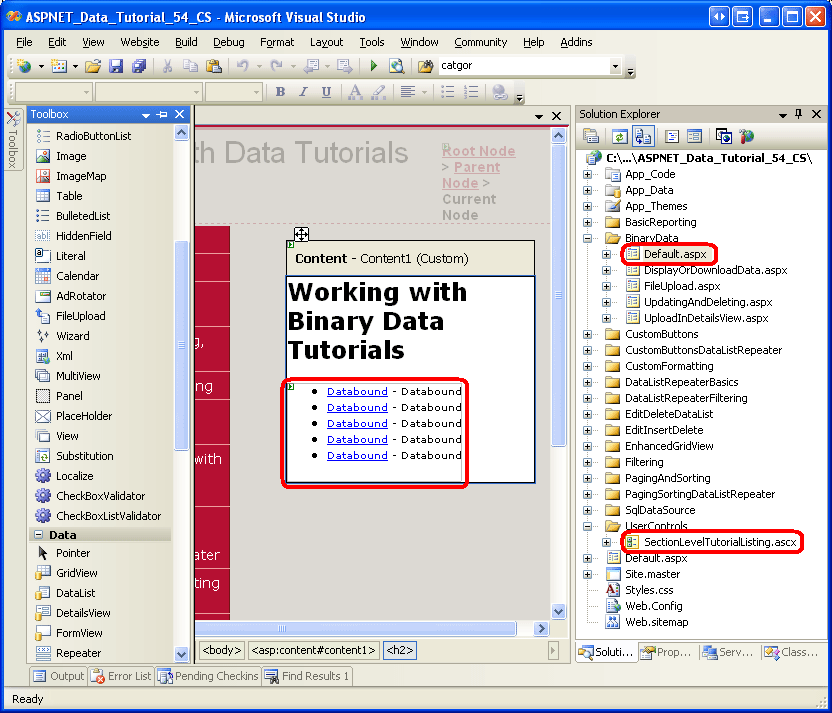
Figura 2: Agregue el control de usuario SectionLevelTutorialListing.ascx a Default.aspx (haga clic aquí para ver la imagen a tamaño completo)
{kind=link}
Por último, agregue las siguientes páginas como entradas al archivo Web.sitemap. En concreto, agregue el marcado siguiente después del <siteMapNode> Mejorar el control GridView:
<siteMapNode
title="Working with Binary Data"
url="~/BinaryData/Default.aspx"
description="Extend the data model to include collecting binary data.">
<siteMapNode
title="Uploading Files"
url="~/BinaryData/FileUpload.aspx"
description="Examine the different ways to store binary data on the
web server and see how to accept uploaded files from users
with the FileUpload control." />
<siteMapNode
title="Display or Download Binary Data"
url="~/BinaryData/DisplayOrDownloadData.aspx"
description="Let users view or download the captured binary data." />
<siteMapNode
title="Adding New Binary Data"
url="~/BinaryData/UploadInDetailsView.aspx"
description="Learn how to augment the inserting interface to
include a FileUpload control." />
<siteMapNode
title="Updating and Deleting Existing Binary Data"
url="~/BinaryData/UpdatingAndDeleting.aspx"
description="Learn how to update and delete existing binary data." />
</siteMapNode>
Después de actualizar Web.sitemap, dedique un momento a ver el sitio web de tutoriales a través de un explorador. El menú de la izquierda ahora incluye elementos para los tutoriales de Trabajar con datos binarios.
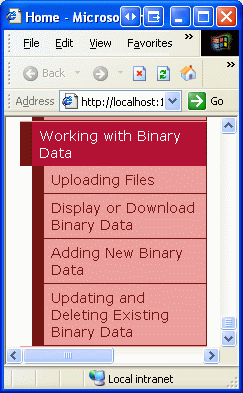
Figura 3: El mapa del sitio ahora incluye entradas para los tutoriales de Trabajar con datos binarios
Paso 2: Decidir dónde almacenar los datos binarios
Los datos binarios asociados al modelo de datos de la aplicación se pueden almacenar en uno de dos lugares: en el sistema de archivos del servidor web con una referencia al archivo almacenado en la base de datos, o directamente dentro de la propia base de datos (vea la figura 4). Cada enfoque tiene su propio conjunto de ventajas y desventajas y merece una discusión más detallada.
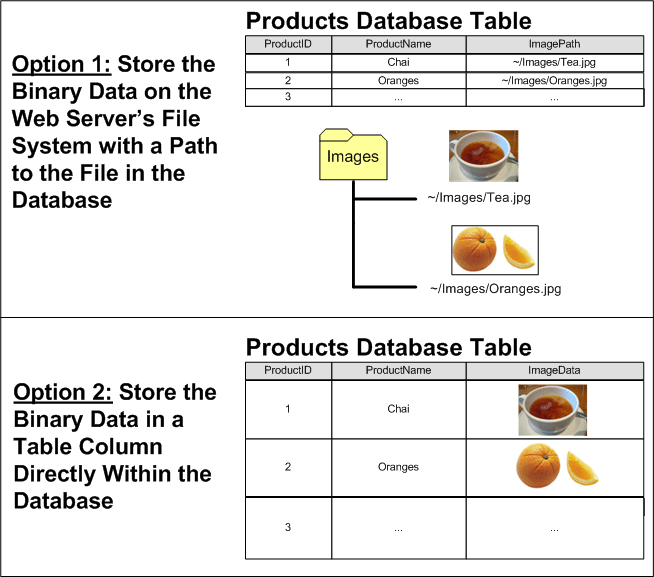
Figura 4: Los datos binarios se pueden almacenar en el sistema de archivos o directamente en la base de datos (haga clic para ver la imagen en tamaño completo)
{kind=link}
Imagine que queremos ampliar la base de datos Northwind para asociar una imagen a cada producto. Una opción sería almacenar estos archivos de imagen en el sistema de archivos del servidor web y registrar la ruta de acceso en la tabla Products. Con este enfoque, agregaríamos una columna ImagePath a la tabla Products de tipo varchar(200), quizá. Cuando un usuario carga una imagen para Chai, esa imagen podría almacenarse en el sistema de archivos del servidor web en ~/Images/Tea.jpg, donde ~ representa la ruta de acceso física de la aplicación. Es decir, si el sitio web se basa en la ruta de acceso física C:\Websites\Northwind\, ~/Images/Tea.jpg sería equivalente a C:\Websites\Northwind\Images\Tea.jpg. Después de cargar el archivo de imagen, actualizaríamos el registro de Chai en la tabla Products para que su columna ImagePath haga referencia a la ruta de acceso de la nueva imagen. Podríamos usar ~/Images/Tea.jpg o simplemente Tea.jpg si decidimos que todas las imágenes de producto se colocarían en la carpeta Images de la aplicación.
Las principales ventajas de almacenar los datos binarios en el sistema de archivos son:
- Facilidad de implementación como veremos en breve, almacenar y recuperar datos binarios almacenados directamente dentro de la base de datos implica un poco más de código que cuando se trabaja con datos a través del sistema de archivos. Además, para que un usuario vea o descargue datos binarios, debe presentar una dirección URL a esos datos. Si los datos residen en el sistema de archivos del servidor web, la dirección URL es un método directo. Sin embargo, si los datos se almacenan en la base de datos, es necesario crear una página web que recuperará y devolverá los datos de la base de datos.
- Acceso más amplio a los datos binarios es posible que los datos binarios necesiten ser más accesibles a otros servicios o aplicaciones, los cuales no pueden extraer los datos de la base de datos. Por ejemplo, es posible que las imágenes asociadas a cada producto también necesiten estar disponibles para los usuarios a través de FTP, en cuyo caso deberíamos almacenar los datos binarios en el sistema de archivos.
- Rendimiento si los datos binarios se almacenan en el sistema de archivos, la demanda y la congestión de red entre el servidor de base de datos y el servidor web serán menores que si los datos binarios se almacenan directamente dentro de la base de datos.
La principal desventaja de almacenar datos binarios en el sistema de archivos es que esto desacopla los datos de la base de datos. Si se elimina un registro de la tabla Products, el archivo asociado en el sistema de archivos del servidor web no se elimina automáticamente. Debemos escribir código adicional para eliminar el archivo o el sistema de archivos quedará desordenado con archivos huérfanos sin usar. Además, al realizar una copia de seguridad de la base de datos, también debemos asegurarnos de realizar copias de seguridad de los datos binarios asociados en el sistema de archivos. Mover la base de datos a otro sitio o servidor plantea desafíos similares.
Como alternativa, los datos binarios se pueden almacenar directamente en una base de datos de Microsoft SQL Server 2005 mediante la creación de una columna de tipo varbinary. Al igual que con otros tipos de datos de longitud variable, puede especificar una longitud máxima de los datos binarios que se pueden mantener en esta columna. Por ejemplo, para reservar como máximo 5000 bytes, use varbinary(5000); varbinary(MAX) permite el tamaño máximo de almacenamiento, aproximadamente 2 GB.
La principal ventaja de almacenar datos binarios directamente en la base de datos es el acoplamiento estricto entre los datos binarios y el registro de la base de datos. Esto simplifica considerablemente las tareas de administración de bases de datos, como las copias de seguridad o el traslado de la base de datos a otro sitio o servidor. Además, la eliminación de un registro elimina automáticamente los datos binarios correspondientes. También hay ventajas más sutiles al almacenar los datos binarios en la base de datos. Consulte Almacenar archivos binarios directamente en la base de datos mediante ASP.NET 2.0 para obtener una explicación más detallada.
Nota:
En Microsoft SQL Server 2000 y versiones anteriores, el tipo de datos varbinary tenía un límite máximo de 8000 bytes. Para almacenar hasta 2 GB de datos binarios, el tipo de datos image debe usarse en su lugar. Sin embargo, con la adición de MAX en SQL Server 2005, el tipo de datos image ha quedado en desuso. Todavía se admite para la compatibilidad con versiones anteriores, pero Microsoft ha anunciado que el tipo de datos image se quitará en una versión futura de SQL Server.
Si trabaja con un modelo de datos anterior, es posible que vea el tipo de datos image. La tabla Categories de la base de datos Northwind tiene una columna Picture que se puede usar para almacenar los datos binarios de un archivo de imagen para la categoría. Dado que la base de datos Northwind tiene sus raíces en Microsoft Access y versiones anteriores de SQL Server, esta columna es de tipo image.
Para este tutorial y los tres siguientes, usaremos ambos enfoques. La tabla Categories ya tiene una columna Picture para almacenar el contenido binario de una imagen para la categoría. Agregaremos una columna adicional, BrochurePath, para almacenar una ruta de acceso a un PDF en el sistema de archivos del servidor web, que se puede usar para proporcionar información general de calidad impresa y pulida de la categoría.
Paso 3: Agregar la columna BrochurePath a la tabla Categories
Actualmente, la tabla Categories tiene solo cuatro columnas: CategoryID, CategoryName, Description y Picture. Además de estos campos, es necesario agregar uno nuevo que apunte al folleto de la categoría (si existe). Para agregar esta columna, vaya al Explorador de servidores, explore en profundidad las tablas, haga clic con el botón derecho en la tabla Categories y elija Abrir definición de tabla (vea la figura 5). Si no ve el Explorador de servidores, seleccione la opción Explorador de servidores en el menú Ver o presione Ctrl+Alt+S.
Agregue una nueva columna varchar(200) a la tabla Categories denominada BrochurePath y permita NULL. Por último, haga clic en el icono Guardar (o presione Ctrl+S).
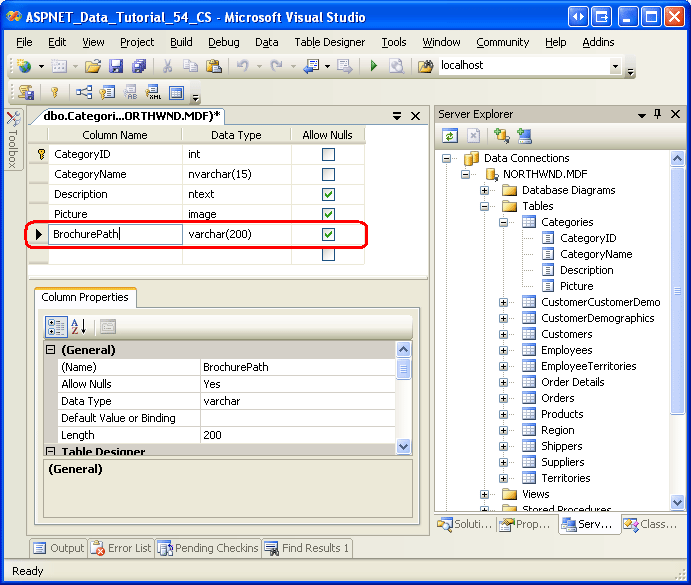
Figura 5: Agregar una nueva columna BrochurePath a la tabla Categories (haga clic aquí para ver la imagen en tamaño completo)
{kind=link}
Paso 4: Actualizar la arquitectura para usar las columnas Picture yBrochurePath
El elemento CategoriesDataTable de la capa de acceso a datos (DAL) tiene actualmente cuatro DataColumn definidas: CategoryID, CategoryName, Description y NumberOfProducts. Cuando originalmente diseñamos esta DataTable en el tutorial Creación de una capa de acceso a datos, la CategoriesDataTable solo tenía las tres primeras columnas; la columna NumberOfProducts se agregó en el tutorial Maestro y detalles mediante una lista con viñetas de registros maestros con un control DataList de detalles (C#).
Como se describe en Creación de una capa de acceso a datos, DataTables en el DataSet con tipo componen los objetos empresariales. TableAdapters es responsable de comunicarse con la base de datos y rellenar los objetos empresariales con los resultados de la consulta. CategoriesDataTable se rellena mediante CategoriesTableAdapter, que tiene tres métodos de recuperación de datos:
GetCategories()ejecuta la consulta principal de TableAdapter y devuelve los camposCategoryID,CategoryNameyDescriptionde todos los registros de la tablaCategories. La consulta principal la usan los métodos generados automáticamenteInsertyUpdate.GetCategoryByCategoryID(categoryID)devuelve los camposCategoryID,CategoryNameyDescriptionde la categoría cuyoCategoryIDes igual a categoryID.GetCategoriesAndNumberOfProducts(): devuelve los camposCategoryID,CategoryNameyDescriptionpara todos los registros de la tablaCategories. También usa una subconsulta para devolver el número de productos asociados a cada categoría.
Observe que ninguna de estas consultas devuelve la Picture o BrochurePath de la tabla Categories; ni las CategoriesDataTable proporciona DataColumn para estos campos. Para trabajar con las propiedades Picture y BrochurePath, primero es necesario agregarlas a CategoriesDataTable y, después, actualizar la clase CategoriesTableAdapter para devolver estas columnas.
Adición de los elementos Picture yBrochurePath``DataColumn
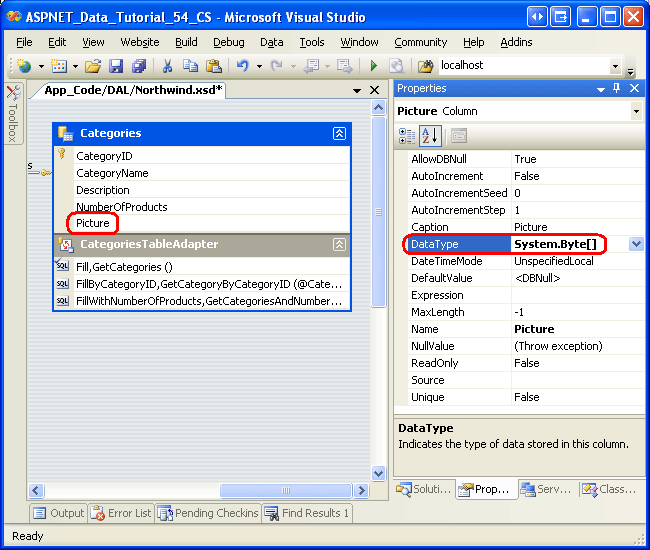
Empiece agregando estas dos columnas a CategoriesDataTable. Haga clic con el botón derecho en el encabezado de CategoriesDataTable, seleccione Agregar en el menú contextual y, a continuación, elija la opción Columna. Esto creará una nueva DataColumn en la DataTable denominada Column1. Cambie el nombre de esta columna a Picture. En la ventana Propiedades, establezca la propiedad DataType de DataColumn como System.Byte[] (esta opción no aparece en la lista desplegable; debe escribirla).
![Cree una imagen con nombre DataColumn cuyo DataType es System.Byte[]](uploading-files-cs/_static/image7.png)
Figura 6: Crear una DataColumn denominada Picture cuyo DataType es System.Byte[] (haga clic para ver la imagen en tamaño completo)
{kind=link}
Agregue otra DataColumn a DataTable y denomínela BrochurePath con el valor predeterminado DataType (System.String).
Devolver los valores Picture y BrochurePathde TableAdapter
Con estas dos DataColumn agregadas a CategoriesDataTable, estamos listos para actualizar CategoriesTableAdapter. Podríamos devolver ambos valores de columna en la consulta principal TableAdapter, pero esto devolvería los datos binarios cada vez que se invoca el método GetCategories(). En su lugar, vamos a actualizar la consulta TableAdapter principal para devolver BrochurePath y crear un método de recuperación de datos adicional que devuelva una columna de categoría Picture determinada.
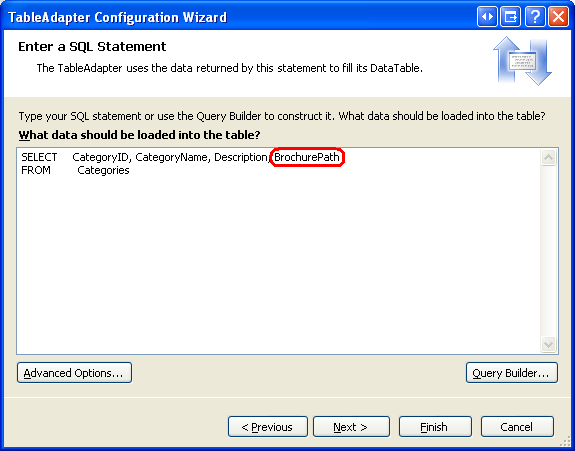
Para actualizar la consulta TableAdapter principal, haga clic con el botón derecho en el encabezado de CategoriesTableAdapter y elija la opción Configurar en el menú contextual. Esto abre el Asistente para la configuración de TableAdapter, que hemos visto en varios tutoriales anteriores. Actualice la consulta para devolver BrochurePath y haga clic en Finalizar.
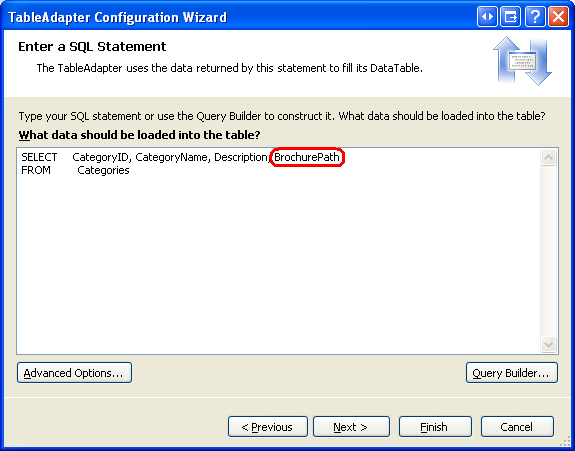
Figura 7: Actualizar la lista de columnas en la instrucción SELECT para devolver también BrochurePath (haga clic para ver la imagen en tamaño completo)
{kind=link}
Cuando se usan instrucciones SQL ad-hoc para TableAdapter, la actualización de la lista de columnas de la consulta principal actualiza la lista de columnas para todos los métodos de consulta SELECT de TableAdapter. Esto significa que el método GetCategoryByCategoryID(categoryID) se ha actualizado para devolver la columna BrochurePath, lo que podría ser lo que pretendemos. Sin embargo, también se ha actualizado la lista de columnas en el método GetCategoriesAndNumberOfProducts(), ¡y se ha quitado la subconsulta que devuelve el número de productos para cada categoría! Por tanto, es necesario actualizar la consulta SELECT de este método. Haga clic con el botón derecho en el método GetCategoriesAndNumberOfProducts(), elija Configurar y vuelva a revierta la consulta SELECT a su valor original:
SELECT CategoryID, CategoryName, Description,
(SELECT COUNT(*)
FROM Products p
WHERE p.CategoryID = c.CategoryID)
as NumberOfProducts
FROM Categories c
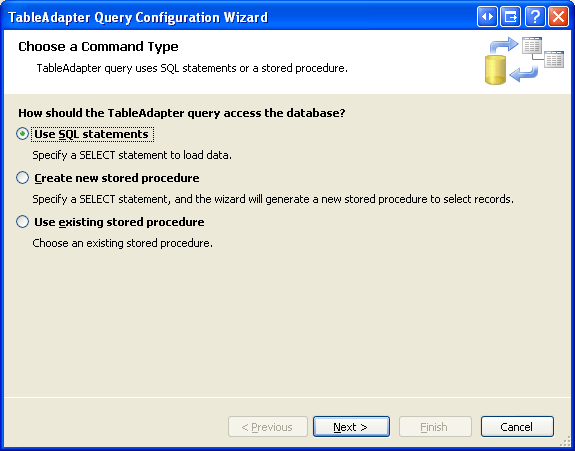
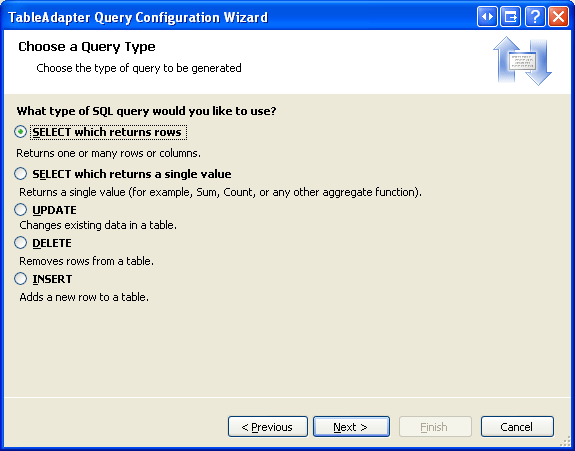
A continuación, cree un nuevo método TableAdapter que devuelva un valor de columna de categoría Picture determinada. Haga clic con el botón derecho en el encabezado de CategoriesTableAdapter y elija la opción Agregar consulta para iniciar el Asistente para la configuración de consultas de TableAdapter. El primer paso de este asistente nos pregunta si queremos consultar datos mediante una instrucción SQL ad-hoc, un nuevo procedimiento almacenado o uno existente. Seleccione Usar instrucciones SQL y haga clic en Siguiente. Puesto que se va a devolver una fila, elija la opción SELECT, que devuelve filas del segundo paso.
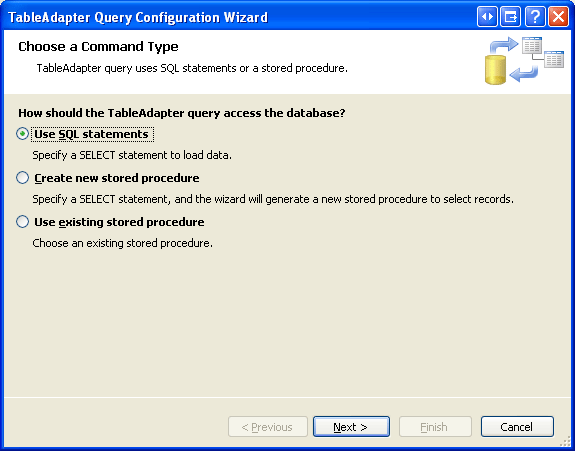
Figura 8: Seleccionar la opción Usar instrucciones SQL (haga clic para ver la imagen en tamaño completo)
{kind=link}
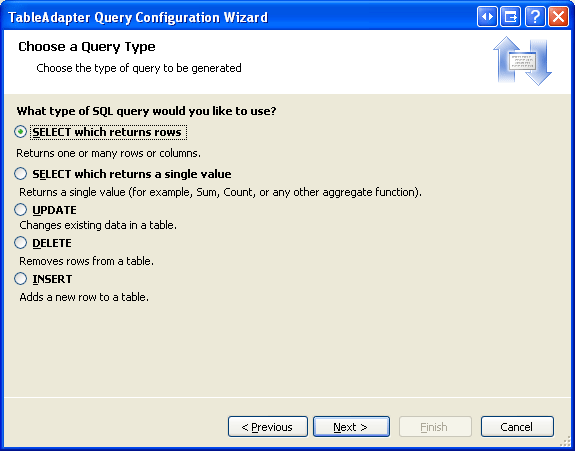
Figura 9: Dado que la consulta devolverá un registro de la tabla Categorías, elija SELECT, que devuelve filas (haga clic para ver la imagen en tamaño completo)
{kind=link}
En el tercer paso, escriba la siguiente consulta SQL y haga clic en Siguiente:
SELECT CategoryID, CategoryName, Description, BrochurePath, Picture
FROM Categories
WHERE CategoryID = @CategoryID
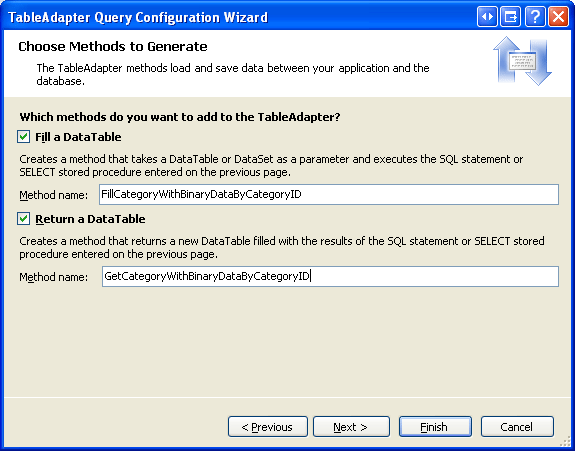
El último paso es elegir el nombre del nuevo método. Use FillCategoryWithBinaryDataByCategoryID y GetCategoryWithBinaryDataByCategoryID para los patrones Rellenar un DataTable y Devolver una DataTable, respectivamente. Haga clic en Finalizar para completar el asistente.
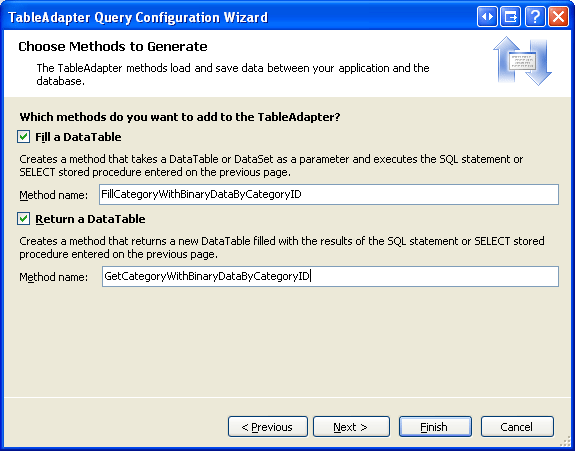
Figura 10: Elegir los nombres de los métodos TableAdapter (haga clic para ver la imagen en tamaño completo)
{kind=link}
Nota:
Después de completar el Asistente para la configuración de consultas de TableAdapter, puede ver un cuadro de diálogo que le informa de que el nuevo texto del comando devuelve datos con un esquema diferente del esquema de la consulta principal. En resumen, el asistente observa que la consulta principal GetCategories() de TableAdapter devuelve un esquema diferente al que acabamos de crear. Sin embargo, esto es lo que queremos, así que ignore este mensaje.
Además, tenga en cuenta que, si usa instrucciones SQL ad-hoc y usa el asistente para cambiar la consulta principal de TableAdapter en algún momento posterior, modificará la lista de columnas de la instrucción SELECT del método GetCategoryWithBinaryDataByCategoryID para incluir solo esas columnas de la consulta principal (es decir, quitará la columna Picture de la consulta). Tendrá que actualizar manualmente la lista de columnas para devolver la columna Picture, similar a lo que hicimos con el método GetCategoriesAndNumberOfProducts() anteriormente en este paso.
Después de agregar las dos DataColumn a la CategoriesDataTable y el método GetCategoryWithBinaryDataByCategoryID a CategoriesTableAdapter, estas clases del Diseñador de DataSet con tipo deben tener un aspecto similar a la captura de pantalla de la Figura 11.
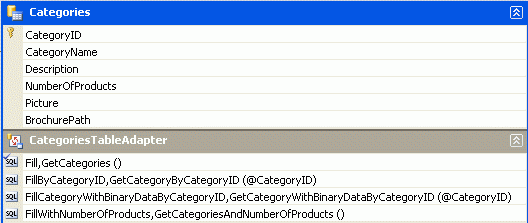
Figura 11: El Diseñador de DataSet incluye las nuevas columnas y el método
Actualizar la capa de lógica empresarial (BLL)
Con la DAL actualizada, todo lo que queda es aumentar la capa de lógica empresarial (BLL) para incluir un método para el nuevo método CategoriesTableAdapter. Agregue el siguiente método a la clase CategoriesBLL:
[System.ComponentModel.DataObjectMethodAttribute
(System.ComponentModel.DataObjectMethodType.Select, false)]
public Northwind.CategoriesDataTable
GetCategoryWithBinaryDataByCategoryID(int categoryID)
{
return Adapter.GetCategoryWithBinaryDataByCategoryID(categoryID);
}
Paso 5: Cargar un archivo desde el cliente al servidor web
Al recopilar datos binarios, suele ser un usuario final quien proporciona estos datos. Para capturar esta información, el usuario debe poder cargar un archivo desde su equipo al servidor web. A continuación, los datos cargados deben integrarse con el modelo de datos, lo que puede significar guardar el archivo en el sistema de archivos del servidor web y agregar una ruta de acceso al archivo de la base de datos o escribir el contenido binario directamente en la base de datos. En este paso, veremos cómo permitir que un usuario cargue archivos desde su equipo al servidor. En el siguiente tutorial, nos enfocaremos en integrar el archivo cargado con el modelo de datos.
El nuevo control web FileUpload de ASP.NET 2.0 proporciona un mecanismo para que los usuarios envíen un archivo desde su equipo al servidor web. El control FileUpload se representa como un elemento <input> cuyo atributo type está establecido como archivo, el cual los exploradores muestran como un cuadro de texto con un botón Examinar. Al hacer clic en el botón Examinar, se abre un cuadro de diálogo desde el que el usuario puede seleccionar un archivo. Cuando se devuelve el formulario, el contenido del archivo seleccionado se envía junto con el postback. En el lado servidor, se puede acceder a la información sobre el archivo cargado a través de las propiedades del control FileUpload.
Para mostrar la carga de archivos, abra la página FileUpload.aspx de la carpeta BinaryData, arrastre un control FileUpload desde el Cuadro de herramientas al Diseñador y establezca la propiedad ID del control como UploadTest. A continuación, agregue un control Button Web; para ello, establezca sus propiedades ID y Text en UploadButton y Cargar archivo seleccionado, respectivamente. Por último, coloque un control Etiqueta web debajo del botón, desactive su propiedad Text y establezca su propiedad ID como UploadDetails.
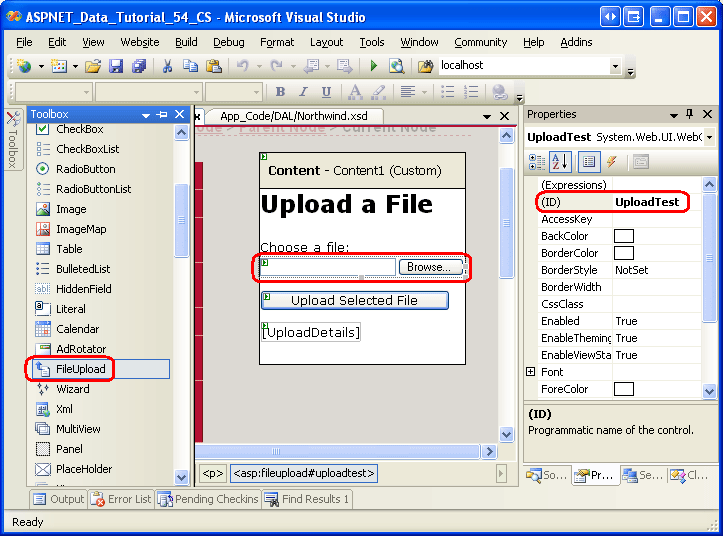
Figura 12: Agregar un control FileUpload a la página de ASP.NET (haga clic para ver la imagen a tamaño completo)
{kind=link}
En la Figura 13, se muestra esta página vista desde un explorador. Tenga en cuenta que, al hacer clic en el botón Examinar, se abre un cuadro de diálogo de selección de archivos, lo que permite al usuario seleccionar un archivo de su equipo. Una vez seleccionado un archivo, al hacer clic en el botón Cargar archivo seleccionado, se produce un postback que envía el contenido binario del archivo seleccionado al servidor web.
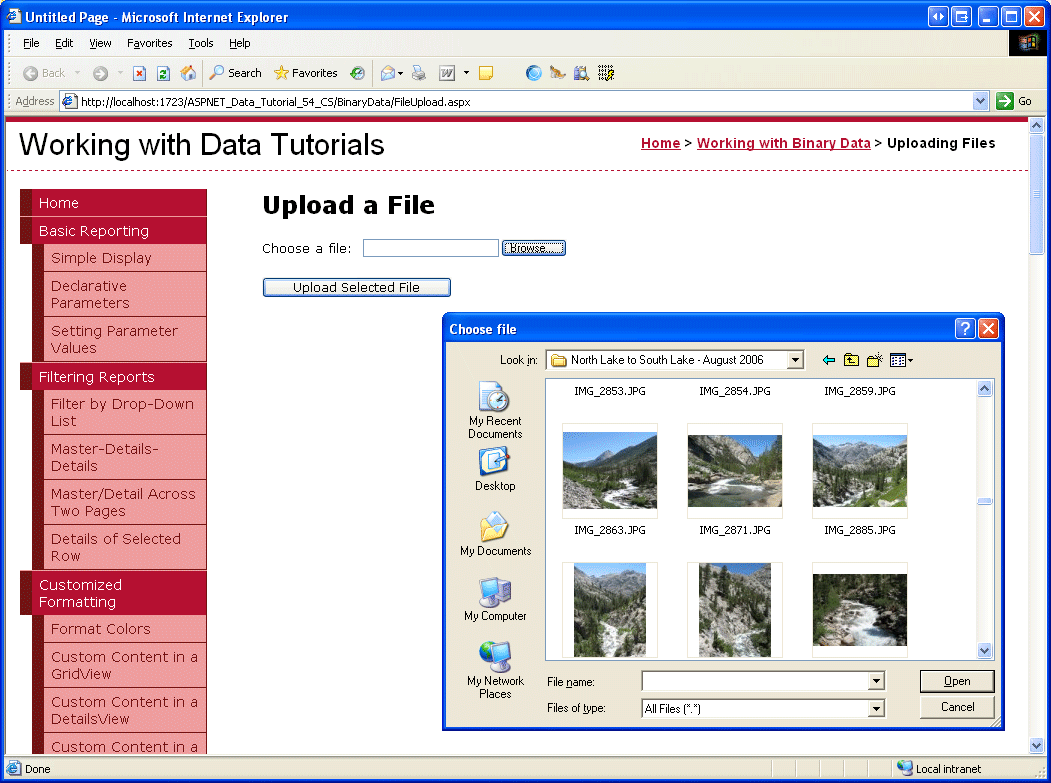
Figura 13: El usuario puede seleccionar un archivo para cargar desde su equipo al servidor (haga clic para ver la imagen en tamaño completo)
{kind=link}
Durante el postback, el archivo cargado se puede guardar en el sistema de archivos o se puede trabajar directamente con sus datos binarios a través de Stream. En este ejemplo, vamos a crear una carpeta ~/Brochures y guardar el archivo cargado allí. Para comenzar, agregue la carpeta Brochures al sitio como una subcarpeta del directorio raíz. A continuación, cree un controlador de eventos para el evento Click de UploadButton y agregue el código siguiente:
protected void UploadButton_Click(object sender, EventArgs e)
{
if (UploadTest.HasFile == false)
{
// No file uploaded!
UploadDetails.Text = "Please first select a file to upload...";
}
else
{
// Display the uploaded file's details
UploadDetails.Text = string.Format(
@"Uploaded file: {0}<br />
File size (in bytes): {1:N0}<br />
Content-type: {2}",
UploadTest.FileName,
UploadTest.FileBytes.Length,
UploadTest.PostedFile.ContentType);
// Save the file
string filePath =
Server.MapPath("~/Brochures/" + UploadTest.FileName);
UploadTest.SaveAs(filePath);
}
}
El control FileUpload proporciona una variedad de propiedades para trabajar con los datos cargados. Por ejemplo, la propiedad HasFile indica si el usuario ha cargado un archivo, mientras que la propiedad FileBytes proporciona acceso a los datos binarios cargados como una matriz de bytes. El controlador de eventos Click se inicia asegurándose de que se ha cargado un archivo. Si se ha cargado un archivo, la etiqueta muestra el nombre del archivo cargado, su tamaño en bytes y su tipo de contenido.
Nota:
Para asegurarse de que el usuario carga un archivo, puede comprobar la propiedad HasFile y mostrar una advertencia si es false, o puede usar el control RequiredFieldValidator en su lugar.
SaveAs(filePath) de FileUpload guarda el archivo cargado en la filePath especificada. filePath debe ser una ruta de acceso física (C:\Websites\Brochures\SomeFile.pdf) en lugar de una ruta de acceso virtual (/Brochures/SomeFile.pdf). El método Server.MapPath(virtPath) toma una ruta de acceso virtual y devuelve su ruta de acceso física correspondiente. Aquí, la ruta de acceso virtual es ~/Brochures/fileName, donde fileName es el nombre del archivo cargado. Consulte el Método Server.MapPath para obtener más información sobre las rutas de acceso virtuales y físicas, y el uso de Server.MapPath.
Después de completar el controlador de eventos Click, dedique un momento a probar la página en un explorador. Haga clic en el botón Examinar y seleccione un archivo de la unidad de disco duro y, a continuación, haga clic en el botón Cargar archivo seleccionado. El postback enviará el contenido del archivo seleccionado al servidor web, que mostrará información sobre el archivo antes de guardarlo en la carpeta ~/Brochures. Después de cargar el archivo, vuelva a Visual Studio y haga clic en el botón Actualizar en el Explorador de soluciones. Debería ver el archivo que acaba de cargar en la carpeta ~/Brochures.
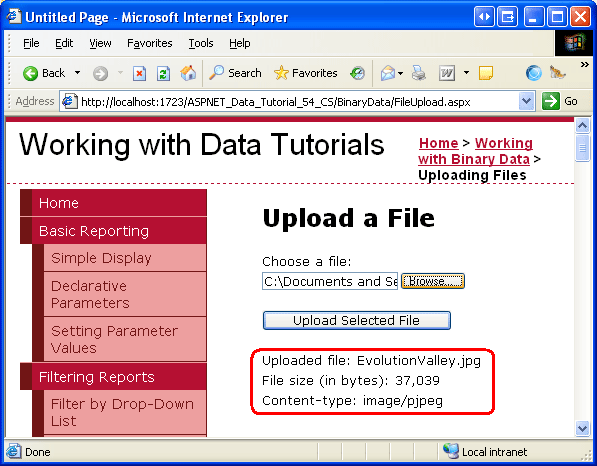
Figura 14: El archivo EvolutionValley.jpg se ha cargado en el servidor web (haga clic para ver la imagen en tamaño completo)
{kind=link}
Figura 15: EvolutionValley.jpg se guardó en la carpeta ~/Brochures
Sutilezas al guardar archivos cargados en el sistema de archivos
Hay varias sutilezas que deben solucionarse al guardar archivos de carga en el sistema de archivos del servidor web. En primer lugar, está el problema de la seguridad. Para guardar un archivo en el sistema de archivos, el contexto de seguridad en el que se ejecuta la página ASP.NET debe tener permisos de escritura. El servidor web de desarrollo de ASP.NET se ejecuta en el contexto de la cuenta de usuario actual. Si usa Internet Information Services (IIS) de Microsoft como servidor web, el contexto de seguridad depende de la versión de IIS y su configuración.
Otro desafío al guardar archivos en el sistema de archivos gira en torno a la nomenclatura de los archivos. Actualmente, nuestra página guarda todos los archivos cargados en el directorio ~/Brochures con el mismo nombre del archivo en el equipo del cliente. Si el usuario A carga un folleto con el nombre Brochure.pdf, el archivo se guardará como ~/Brochure/Brochure.pdf. Sin embargo, ¿qué ocurre si algún tiempo más tarde el usuario B carga un archivo de folleto diferente que tiene el mismo nombre de archivo (Brochure.pdf)? Con el código que tenemos ahora, el archivo del usuario A se sobrescribirá con la carga del usuario B.
Hay varias técnicas para resolver conflictos de nombres de archivo. Una opción es prohibir la carga de un archivo si ya existe uno con el mismo nombre. Con este enfoque, cuando el usuario B intente cargar un archivo denominado Brochure.pdf, el sistema no guardaría su archivo y, en su lugar, mostraría un mensaje que informa al usuario B que debe cambiar el nombre del archivo e intentarlo de nuevo. Otro enfoque consiste en guardar el archivo mediante un nombre de archivo único, que podría ser un identificador único global (GUID) o el valor de las columnas de clave principal del registro de base de datos correspondiente (suponiendo que la carga esté asociada a una fila determinada en el modelo de datos). En el siguiente tutorial, exploraremos estas opciones con más detalle.
Desafíos implicados en cantidades muy grandes de datos binarios
En estos tutoriales, se asume que los datos binarios capturados son de un tamaño considerable. Trabajar con grandes cantidades de archivos de datos binarios que pesan varios megabytes o son más grandes presenta nuevos desafíos que están fuera del ámbito de estos tutoriales. Por ejemplo, de forma predeterminada, ASP.NET rechazará las cargas de más de 4 MB, aunque esto se puede configurar a través del elemento <httpRuntime> en Web.config. IIS impone también sus propias limitaciones de tamaño de carga de archivos. Además, el tiempo necesario para cargar archivos grandes puede superar los 110 segundos predeterminados que ASP.NET espera por una solicitud. Asimismo, existen problemas de memoria y rendimiento que surgen al trabajar con archivos grandes.
El control FileUpload no es práctico para cargas de archivos grandes. A medida que el contenido del archivo se publica en el servidor, el usuario final debe esperar pacientemente sin tener confirmación del progreso de su carga. Esto no es tanto un problema al tratar con archivos más pequeños que se pueden cargar en unos segundos, pero puede ser un problema al tratar con archivos más grandes que pueden tardar minutos en cargarse. Existe una variedad de controles de carga de archivos de terceros que son más adecuados para controlar cargas grandes y muchos de estos proveedores proporcionan indicadores de progreso y administradores de carga ActiveX que presentan una experiencia de usuario mucho más pulida.
Si la aplicación necesita controlar archivos grandes, deberá investigar cuidadosamente los desafíos relacionados y encontrar soluciones adecuadas para sus necesidades concretas.
Resumen
La creación de una aplicación que necesita capturar datos binarios presenta una serie de desafíos. En este tutorial, hemos explorado los dos primeros: decidir dónde almacenar los datos binarios y permitir que un usuario cargue contenido binario a través de una página web. En los tres tutoriales siguientes, veremos cómo asociar los datos cargados a un registro de la base de datos, así como cómo mostrar los datos binarios junto con sus campos de datos de texto.
¡Feliz programación!
Lecturas adicionales
Para obtener más información sobre los temas tratados en este tutorial, consulte los siguientes recursos:
- Usar tipos de datos de valores grandes
- Inicios rápidos del control FileUpload
- El control de servidor FileUpload de ASP.NET 2.0
- El lado oscuro de las cargas de archivos
Acerca del autor
Scott Mitchell, autor de siete libros de ASP/ASP.NET y fundador de 4GuysFromRolla.com, ha trabajado con tecnologías web de Microsoft desde 1998. Scott trabaja como consultor independiente, entrenador y escritor. Su último libro es Sams Teach Yourself ASP.NET 2.0 in 24 Hours. Puede ponerse en contacto con él a través de mitchell@4GuysFromRolla.com. o de su blog, que se puede encontrar en http://ScottOnWriting.NET.
Agradecimientos especiales a
Esta serie de tutoriales contó con la revisión de muchos revisores que fueron de gran ayuda. Los revisores principales de este tutorial fueron Teresa Murphy y Bernadette Leigh. ¿Le interesaría revisar mis próximos artículos de MSDN? Si es así, escríbame a mitchell@4GuysFromRolla.com.