Behavior of Dynamic Witness on Windows Server 2012 R2 Failover Clustering
With Failover Clustering on Windows Server 2012 R2, we introduced the concept of Dynamic Witness and enhanced how we handle a tie breaker when the nodes are in a 50% split:
See:
Today, I would like to explain how we handle the scenario where you are left with one node and the witness as the only votes on your Windows Server 2012 R2 Cluster.
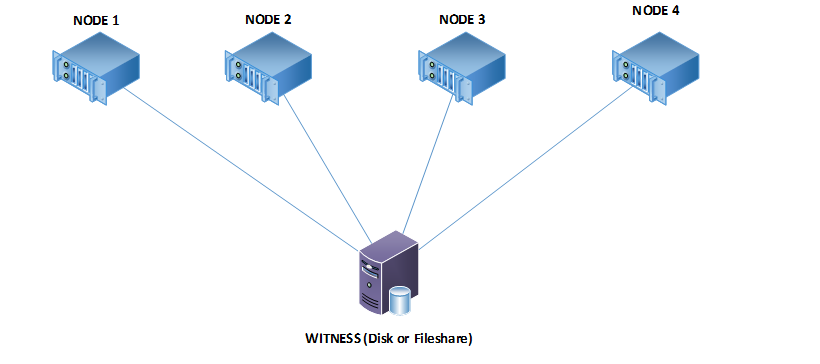
Let’s assume that we have a 4 Node cluster with dynamic quorum enabled.
To see the status of dynamic quorum and the witness’ dynamic weight, you can use this PowerShell command:

Now, let’s use PowerShell to look at the weights of the nodes:

Now, let’s take down the nodes one by one until we have just one of the nodes and the witness standing. I turned off Node 4, followed by Node 3, and finally Node 2:
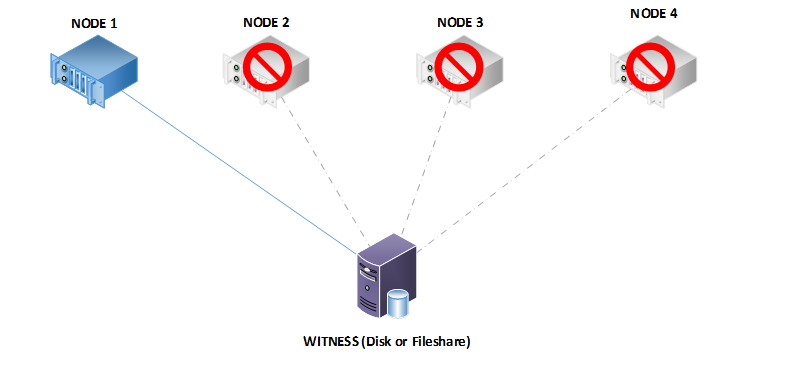
The cluster will continue to remain functional thanks to dynamic quorum, assuming that all of the resources can run on the single node.
Let’s look at the node weights and dynamic witness weight now:

Let’s take this further and assume that for some reason, the witness also sees a failure and you see the event ID 1069 for the failure of the witness:
Log Name: System
Source: Microsoft-Windows-FailoverCluster
Date: Date
Event ID: 1069
Level: Error
User: AUTHORITY\SYSTEM
Computer: servername
Description:
Cluster resource 'Cluster Disk x' in clustered service or application 'Cluster Group' failed.
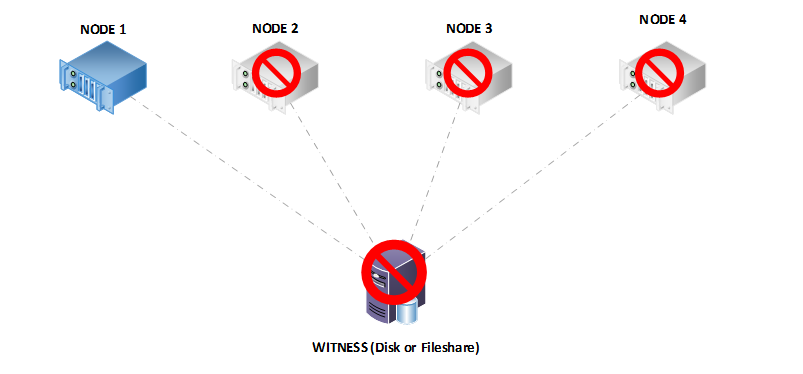
We really do not expect that this would happen on a production cluster where nodes go offline until there is one left and the witness also suffers a failure. Unfortunately, in this scenario, the cluster will not continue running and the cluster service will terminate because we can no longer achieve quorum. We will not dynamically adjust the votes below three in a multi-node cluster with a witness, so that means we need two votes active to continue functioning.
When you configure a cluster with a witness, we want to ensure that the cluster is able to recover from a partitioned scenario. The philosophy is that two replicas of the cluster configuration are better than one. If we adjusted the quorum weight after we suffered the loss of Node 2 in our scenario above (when we had two nodes and the witness), then your data would be subject to loss with a single failure. This is intentional, we are keeping two copies of the cluster configuration and now either copy can start the cluster back up. You have a much better chance of surviving and recovering from a loss.
That’s about the little secret to keep your cluster fully functional.
Until next time!
Ram Malkani
Technical Advisor
Windows Core Team
Comments
- Anonymous
March 21, 2016
#This was good if we have disk witness configured as that will prevent the partitioning in time, as it has CLUSDB copy on it, however in case of File_Share_Witness its not helping with last man standing and will force the partitioning in time as it needs to be started with ForceQuorum.#However if we are considering only Nodes to be "Man" in this scenario then cluster is already running on last Man.#VoteShouldTurnToZero for file witness :).Shashank AggarwalDeciphering Cluster....!- Anonymous
March 21, 2016
#This was good if we have disk witness configured as that will prevent the partitioning in time, as it has CLUSDB copy on it, however in case of File_Share_Witness its not helping with last man standing and will force the partitioning in time as it needs to be started with ForceQuorum.#However if we are considering only Nodes to be “Man” in this scenario then cluster is already running on last Man.#VoteShouldTurnToZero for File Share Witness, which doesn't in the end :)Shashank AggarwalDeciphering Cluster….!- Anonymous
March 22, 2016
We want to keep the behavior identical and not have confusing scenarios with different witness. Thus the behavior holds true for both Disk witness and File Share Witness. - Anonymous
November 08, 2016
I agree with this comment, especially with S2D where there is NEVER a shared disk quorum. It would be more resilient to remove the vote from the File Share Witness or Cloud Witness in the last man standing scenario. Especially now that Cloud Witness seems to be the preferred witness type. - Anonymous
November 08, 2016
To continue on my last comment. In a 2-node S2D configuration, typical for a ROBO, if you lose one node and then you lose internet connectivity (bringing down the Cloud Witness), your remaining node will go offline. Considering the internet access in a ROBO is commonly "commodity service" it is not uncommon for internet access to have blips and outages.
- Anonymous
- Anonymous
- Anonymous
March 22, 2016
The comment has been removed- Anonymous
March 22, 2016
#In cluster we have 3 states of nodes. =Online =Offline =Paused#Online and Paused state will contribute in cluster Quorum formation. In your case you are keeping 2 nodes , so in this case "Current Vote" of one of the node will be "Zero", so if this node goes down cluster will survive. On the other hand if other node which is holding a "Current Vote" as one crashes cluster will go down , however if it is grace full shutdown or restart then in that case cluster dynamic quorum will pass the vote to another node to have the cluster running on last man standing.#Getting back to your question , above statement will remain true for node in "Paused State" and it will not transfer a vote to another node untill you do it manually. I would suggest, for patching drain the node first , patch and doa grace full reboot and cluster will do the rest for you.Shashank Aggarwal
- Anonymous
- Anonymous
June 03, 2016
Nice article..is this something going to change in windows 2016?iam ok with this behaviour if our witness on San..but if witness is a share on say nas filler and 3 nodes does down along with witness my cluster should be online as along as the disk on online on San..If this is not true can i force the quorum in thiscase to being online on single node?Thx - Anonymous
June 03, 2016
Nice article..is this something going to change in windows 2016?iam ok with this behaviour if our witness on San..but if witness is a share on say nas filler and 3 nodes does down along with witness my cluster should be online as along as the disk on online on San..If this is not true can i force the quorum in thiscase to being online on single node?Thx - Anonymous
July 25, 2016
Undeniably believe that which you said. Your favorite justification seemed to be on the net the simplest thing to be aware of. I say to you, I definitely get irked while people consider worries that they just don't know about. You managed to hit the nail upon the top and also defined out the whole thing without having side effect , people can take a signal. Will likely be back to get more. Thanks - Anonymous
December 08, 2016
Hi Ram. In your article you reduce the cluster down to 1 node and 1 FSW ... so how come the PoerShell output for Get-ClusterNode shows N2 still has a current vote (DynamicWeight=1)?? I'm seeing the same behaviour and vote status in the FCM and GUI and via PS cmdlets for my cluster. It's very confusing to see a node still has a current (Dynamic) vote when the node is clearly down. Please help me understand why. With thanks, Mark.- Anonymous
June 12, 2017
Hello Mark,This is the expected behavior (by design) to avoid partition in time. so in case you node 1(last node) turns out to be down the cluster can have one mode node with which the cluster could be up and running. So as to avoid the portioning in time the second last node in the cluster always hold the vote irrespective if its DOWN or UP.Nikhil Matere.
- Anonymous