Getting started with LLM fine-tuning
Large Language Model (LLM) fine-tuning involves adapting the pre-trained model to specific tasks. This process takes place by updating parameters on a new dataset. Specifically, the LLM is partially retrained using <input, output> pairs of representative examples of the desired behavior. Hence, it involves updating the model weights.
Data requirements for fine-tuning
Before fine-tuning an LLM, it is essential to understand data requirements to support training and validation.
Here are some guidelines:
- Use a large dataset: The required size for a training and validation dataset depends on the complexity of the task and the model being fine-tuned. Generally, you want to have thousands or tens of thousands of examples. Larger models learn more with less data as illustrated in the examples in the figure below. They still need enough data to avoid over-fitting or forgetting what they learned from the pre-training phase.
- Use a high-quality dataset: The dataset should be consistently formatted and cleaned of incomplete or incorrect examples.
- Use a representative dataset: The contents and format of the fine-tuning dataset should be representative of the data on which the model will be used. For example, if you are fine-tuning a model for sentiment analysis, you want to have data from different sources, genres, and domains. This data should also reflect the diversity and nuances of human emotions. You also want to have a balanced distribution of positive, negative, and neutral examples, to avoid skewing the model’s predictions.
- Use a sufficiently specified dataset: The dataset should contain enough information in the input to generate what you want to see in the output. For example, if you are fine-tuning a model for email generation, you want to provide clear and specific prompts that guide the model’s creativity and relevance. You also want to define the expected length, style, and tone of the email.
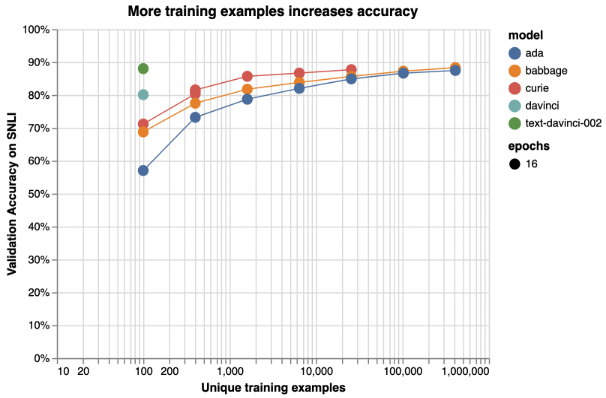
This diagram shows illustrative examples of text classification performance on the Stanford Natural Language Inference (SNLI) Corpus. Ordered pairs of sentences are classified by their logical relationship: either contradicted, entailed (implied), or neutral. Default fine-tuning parameters were used when not otherwise specified.
How to format data to fine-tune OpenAI
To fine-tune a model using Azure OpenAI (or OpenAI), you'll need a set of training examples that have certain formats. For more information, see Customize an Azure OpenAI model with fine-tuning.
Here are some additional guidelines:
- Use JSON: The training examples should be provided in JSON format, where each example consists of a <prompt, completion> pair. The prompt is a text fragment that you want the model to continue. The completion is a possible continuation that the model should learn to produce. For example, if you want to fine-tune an LLM for story generation, a prompt could be the beginning of a story, and a completion could be the next sentence or paragraph.
- Use a separator and stop sequence: To inform the model when the prompt ends and the completion begin and when the completion ends, use a fixed separator and a stop sequence. A separator is a special token or symbol that you insert at the end of the prompt. A stop sequence is a special token or symbol that you insert at the end of the completion. For example, you could use
\n##\nas the separator and\n###\nas the stop sequence, as shown below:
{"prompt": "Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do.\n##\n",
"completion": "She wondered if they should just go back home.\n###\n"}
- Don't confuse the model: Make sure the separator and stop sequence aren't included in prompt text or training data. The model should only ever see them as a separator and stop sequence.
- Use a consistent style and tone: You should also make sure that your prompts and completions are consistent in terms of style, tone, and length. They should match the task or domain for which you want to fine-tune the model.
- Keep training and inference prompts consistent: Make sure that the prompts you use when using the model for inference are formatted and worded in the same way that the model was trained, including using the same separator.
Fine-tuning hyperparameters
When fine-tuning an LLM such as GPT-3, it is important to adjust hyperparameters to optimize the performance of the model on a specific task or domain. Many hyperparameters are available for the user to adjust when fine-tuning a model. The table below lists some of these parameters and provides some recommendations for each. (Source: Best practices for fine-tuning GPT-3 to classify text)
| Parameter | Description | Recommendation |
|---|---|---|
| n_epochs | Controls the number of epochs to train the model for. An epoch refers to one full cycle through the training dataset. | • Start from 2-4 • Small datasets may need more epochs and large datasets may need fewer epochs. • If you see low training accuracy (under-fitting), try increasing n_epochs. If you see high training accuracy but low validation accuracy (over-fitting), try lowering n_epochs. |
| batch_size | Controls the batch size, which is the number of examples used in a single training pass. | • Recommendation is set the batch size in the range of 0.01% to 4% of training set size. • In general, larger batch sizes tend to work better for larger datasets. |
| learning_rate_multiplier | Controls learning rate at which the model weights are updated. The fine-tuning learning rate is the original learning rate used for pre-training, multiplied by this value. | • Recommendation is experiment with values in the range 0.02 to 0.2 to see what produces the best results. • Larger learning rates often perform better with larger batch sizes. • learning_rate_multiplier has minor effect compared to n_epochs and batch_size. |
| prompt_loss_weight | Controls how much the model learns from prompt tokens vs completion tokens. | • If prompts are long (relative to completions), try reducing this weight (default is 0.1) to avoid over-prioritizing learning the prompt. • prompt_loss_weight has minor effect compared to n_epochs and batch_size. |
Challenges and limitations of fine-tuning
Fine-tuning large language models scan be a powerful technique to adapt them to specific domains and tasks. However, fine-tuning also comes with some challenges and disadvantages that need to be considered before applying it to a real-world problem. Below are a few of these challenges and disadvantages.
- Fine-tuning requires high-quality, sufficiently large, and representative training data matching the target domain and task. Quality data is relevant, accurate, consistent, and diverse enough to cover the possible scenarios and variations the model will encounter in the real world. Poor-quality or unrepresentative data leads to over-fitting, under-fitting, or bias in the fine-tuned model, which harms its generalization and robustness.
- Fine-tuning large language models means extra costs associated with training and hosting the custom model.
- Formatting input/output pairs used to fine-tune a large language model can be crucial to its performance and usability.
- Fine-tuning may need to be repeated whenever the data is updated, or when an updated base model is released. This involves monitoring and updating regularly.
- Fine-tuning is a repetitive task (trial and error) so, the hyperparameters need to be carefully set. Fine-tuning requires much experimentation and testing to find the best combination of hyperparameters and settings to achieve desired performance and quality.