Usar el modelo precompilado de reconocimiento de texto en Power Automate
El modelo precompilado de reconocimiento de texto extrae AI Builder texto impreso y manuscrito de imágenes y documentos. Al usar este modelo Power Automate, puede crear flujos de trabajo que procesan automáticamente el texto de documentos escaneados, fotos y archivos PDF, lo que permite un manejo eficiente de los datos y la integración con otras aplicaciones.
Este documento proporciona una guía sobre el uso del modelo precompilado de reconocimiento de texto en Power Automate.
Inicializar el flujo de Power Automate
Inicializar el flujo de Power Automate es el primer paso para configurar su proceso automatizado. Este paso le permite definir el desencadenador y los parámetros de entrada iniciales para su flujo. Al inicializar, puede asegurarse de que el flujo se inicia correctamente y tiene la información necesaria para procesar las tareas de reconocimiento de texto de manera eficiente.
Para inicializar su flujo, siga estos pasos:
Inicie sesión en Power Automate.
En el menú de navegación izquierdo, seleccione Mis flujos y luego seleccione Nuevo flujo>Flujo de nube instantáneo.
Asigne un nombre al flujo, seleccione Desencadenar un flujo manualmente en Elija cómo desencadenar este flujo y, luego, seleccione Crear.
Expanda Desencadenar un flujo manualmente, seleccione +Agregar una entrada>Archivo como tipo de entrada.
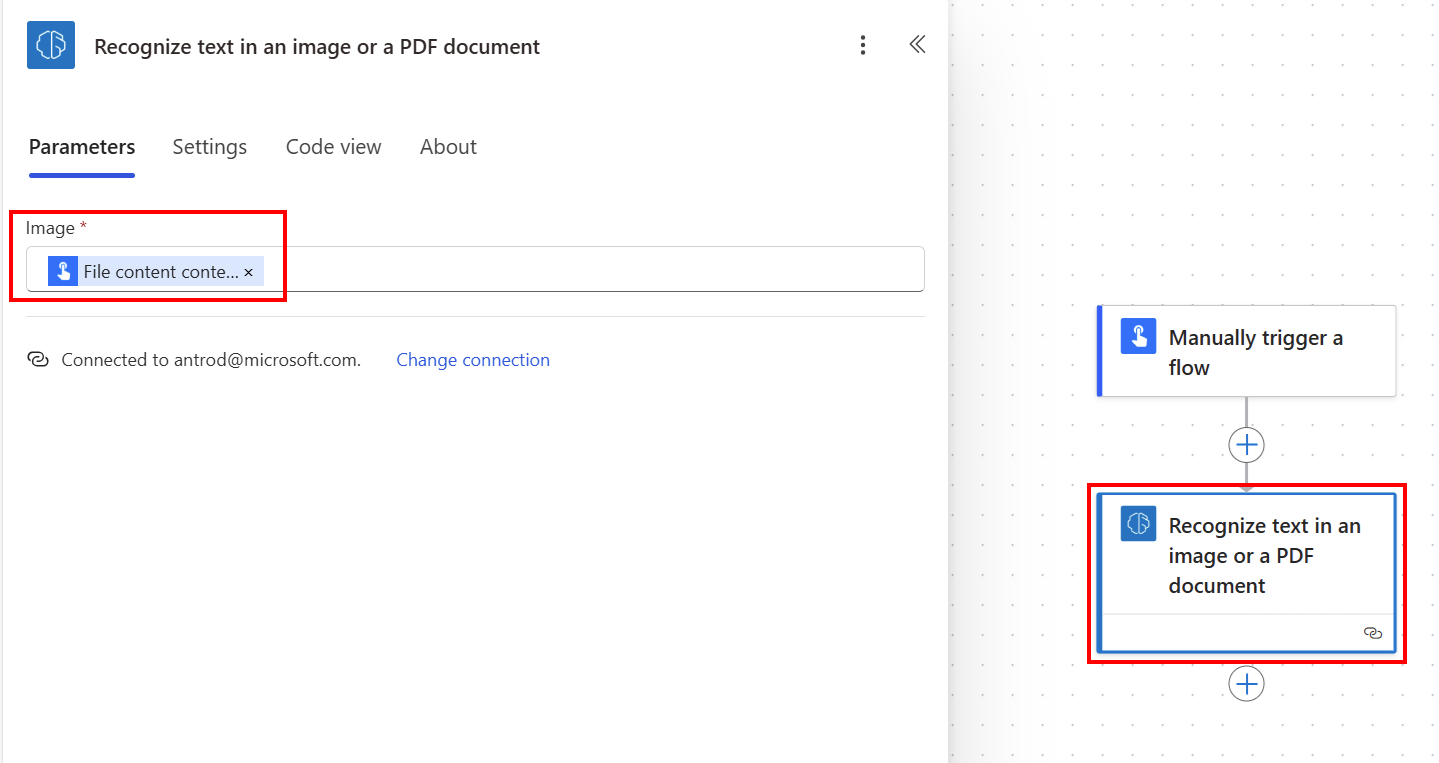
Seleccione +Nuevo paso>AI Builder y luego seleccione Reconocer texto en una imagen o un documento PDF en la lista de acciones.
Seleccione la entrada Imagen y, a continuación, Contenido del archivo en la lista Contenido dinámico:
Para procesar los resultados, puede utilizar el texto completo del documento, un texto de página o el texto del documento línea por línea.
Obtener el texto completo del documento o un texto de página completa
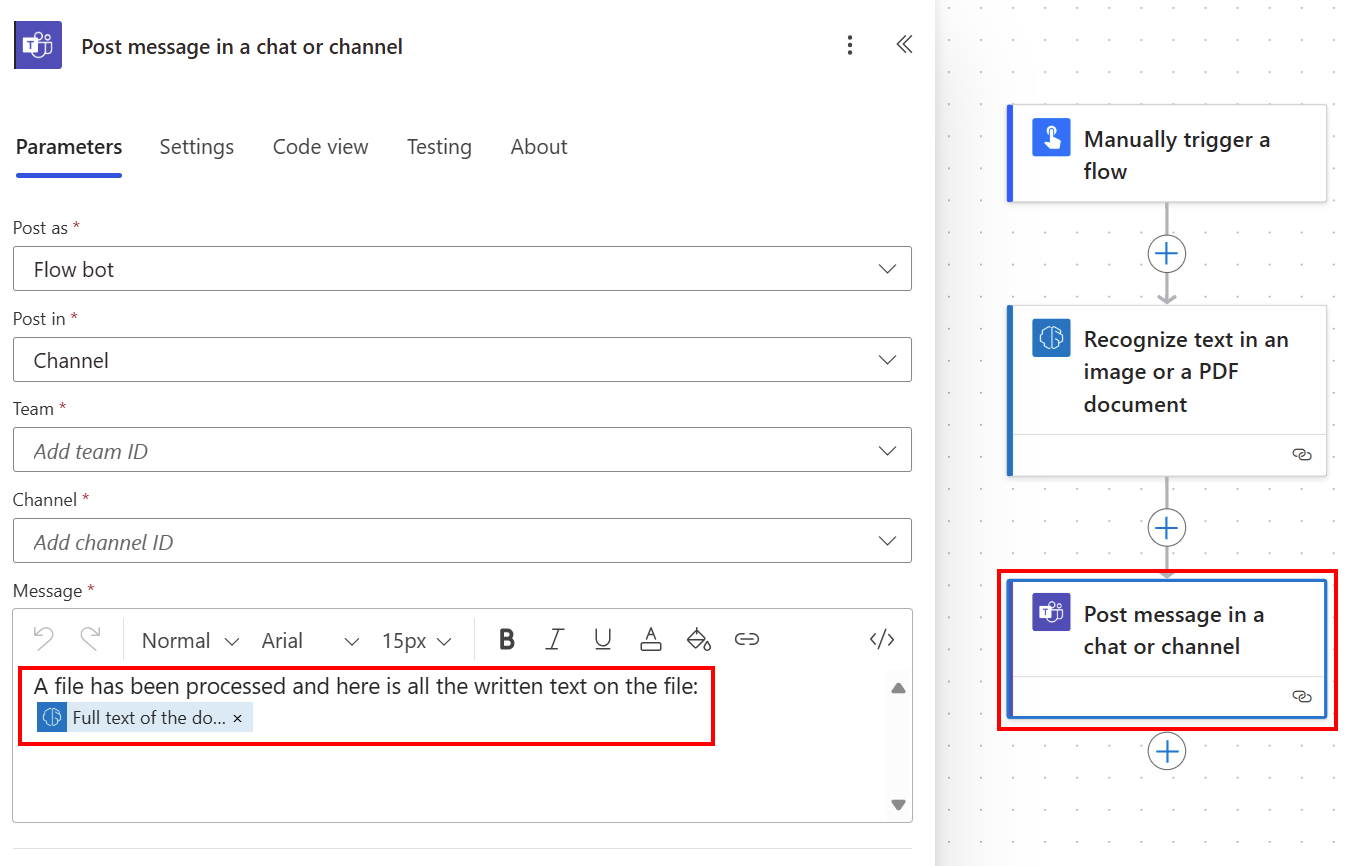
Si necesita realizar una acción en el texto completo del documento o en el texto de una página específica, esta opción es útil. Un ejemplo del uso del texto de página es cuando se quiere buscar una subcadena o pasarla a una acción posterior.
Puede publicar todo el texto extraído en un canal de Teams utilizando el texto completo del documento de la lista de contenido dinámico.
Obtener el texto del documento línea por línea
Obtener el texto del documento línea por línea puede ser útil si necesita aislar una línea de texto específica o cambiar el formato del texto a su conveniencia.
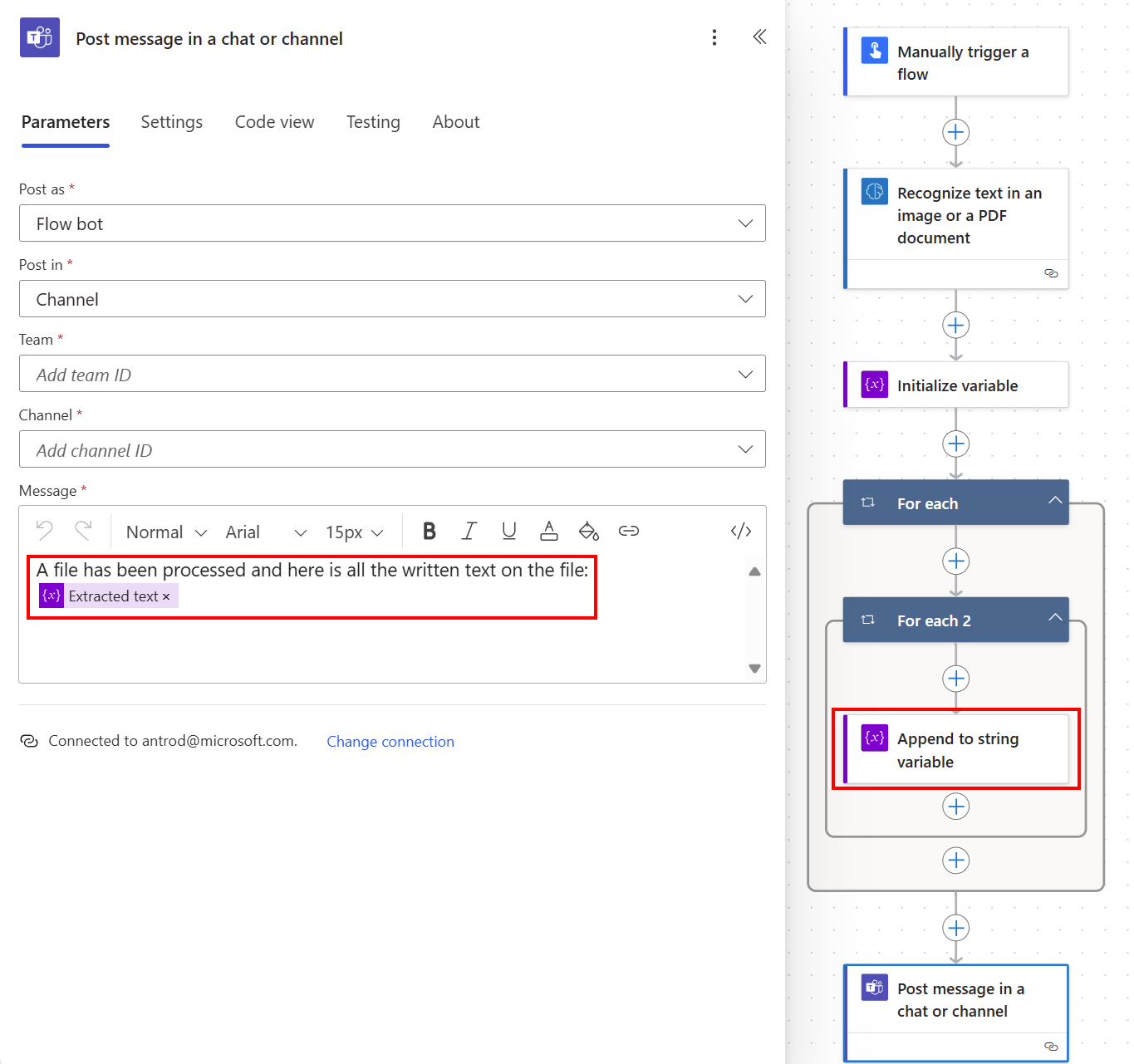
Para crear una variable de cadena, seleccione +Nuevo paso>Control y, a continuación, seleccione Inicializar variable.
Nómbrelo Texto extraído, por ejemplo.
Seleccione +Nuevo paso>Control y, a continuación, seleccione Anexar a variable cadena.
En el campo valor, seleccione Texto en la lista de contenido dinámica.
Genera automáticamente dos acciones Aplicar a cada uno mientras lee una lista de líneas de texto en una lista de páginas. A continuación, puede publicar todo el texto extraído en un canal de Teams.
Enhorabuena. Ha creado un flujo que usa un modelo de reconocimiento de texto. Puede continuar con la compilación de este flujo hasta que se ajuste a sus necesidades. Seleccione Guardar en la parte superior derecha y seleccione Prueba para probar su flujo.
Parámetros
El modelo precompilado de reconocimiento de texto en AI Builder contiene los siguientes parámetros de entrada y salida.
Entrada
| Nombre. | Obligatorio | Type | Description |
|---|---|---|---|
| Imagen | Sí | Archivo | Imagen para analizar |
Salida
El texto detectado se incrusta en la sublista líneas de la lista resultados. Primero debe seleccionar la columna líneas de una acción Aplicar a cada uno para ver todas las columnas siguientes.
| Nombre | Tipo | Descripción |
|---|---|---|
| Texto | cadena | Cadenas que contienen la línea de texto detectada |
| Número de página | string | Número de página del texto detectado |
| Coordenadas | flotante | Coordenadas del texto detectado |
| Texto completo del documento | string | Texto completo detectado |
| Texto completo de la página | string | Texto de página completa detectado |