Escalado de una instancia de Azure Managed Redis (versión preliminar)
Azure Managed Redis (versión preliminar) tiene diferentes ofertas de SKU y niveles que proporcionan flexibilidad en la elección del tamaño y el rendimiento de la caché. Puede escalar verticalmente a un tamaño de memoria mayor o cambiar a un nivel con más rendimiento de proceso. En este artículo se muestra cómo escalar la caché en Azure Portal y herramientas tales como Azure PowerShell y la CLI de Azure.
Nota:
Dado que cada nivel de Azure Managed Redis tiene prácticamente las mismas características, el escalado se usa normalmente solo para cambiar las características de memoria y rendimiento.
Importante
Actualmente, solo se admite el escalado vertical hasta tamaños de memoria mayores o un nivel de rendimiento superior. Todavía no se admite el escalado vertical de tamaños de memoria o a un nivel menos eficaz.
Tipos de escalado
Azure Managed Redis admite el escalado en dos dimensiones:
Memoria Aumentar la memoria aumenta el tamaño de la instancia de Redis, lo que le permite almacenar más datos.
vCPU Azure Managed Redis ofrece tres niveles (optimizada para memoria, equilibrado y optimizado para proceso) que tienen un número creciente de vCPU para cada nivel de memoria. El escalado a un nivel con más vCPU aumenta el rendimiento de la instancia sin necesidad de aumentar la memoria. A diferencia de la edición de la comunidad de Redis, que solo puede usar una sola vCPU, Azure Managed Redis usa la pila de Redis Enterprise, que puede usar varias vCPU. Esto significa que el número de vCPU que usa la instancia de Redis se correlaciona directamente con el rendimiento y el rendimiento de la latencia.
Niveles de rendimiento
Hay cuatro niveles de Azure Managed Redis disponibles, cada uno con diferentes características de rendimiento y niveles de precio.
Tres niveles son para los datos en memoria:
- Optimizada para memoria. Ideal para casos de uso intensivos de memoria que requieren una relación elevada de memoria a vCPU (8:1), pero no necesita el rendimiento más alto. Proporciona un punto de precio más bajo para escenarios en los que se necesita menos potencia de procesamiento o rendimiento, lo que lo convierte en una excelente opción para entornos de desarrollo y pruebas.
- Equilibrado (memoria y proceso). Ofrece una relación de memoria equilibrada a vCPU (4:1), lo que lo convierte en ideal para cargas de trabajo estándar. Proporciona un equilibrio correcto de memoria y recursos de proceso.
- Optimizado para proceso. Diseñado para cargas de trabajo con un uso intensivo del rendimiento que requieren un rendimiento máximo, con una relación baja de memoria a vCPU (2:1). Es ideal para las aplicaciones que exigen el máximo rendimiento.
Un nivel almacena datos tanto en memoria como en disco:
- Optimizado para Flash. Permite que los clústeres de Redis muevan automáticamente los datos a los que se accede con menos frecuencia desde la memoria (RAM) al almacenamiento NVMe. Esto reduce el rendimiento, pero permite el escalado rentable de cachés con grandes conjuntos de datos.
Niveles y SKU de un vistazo
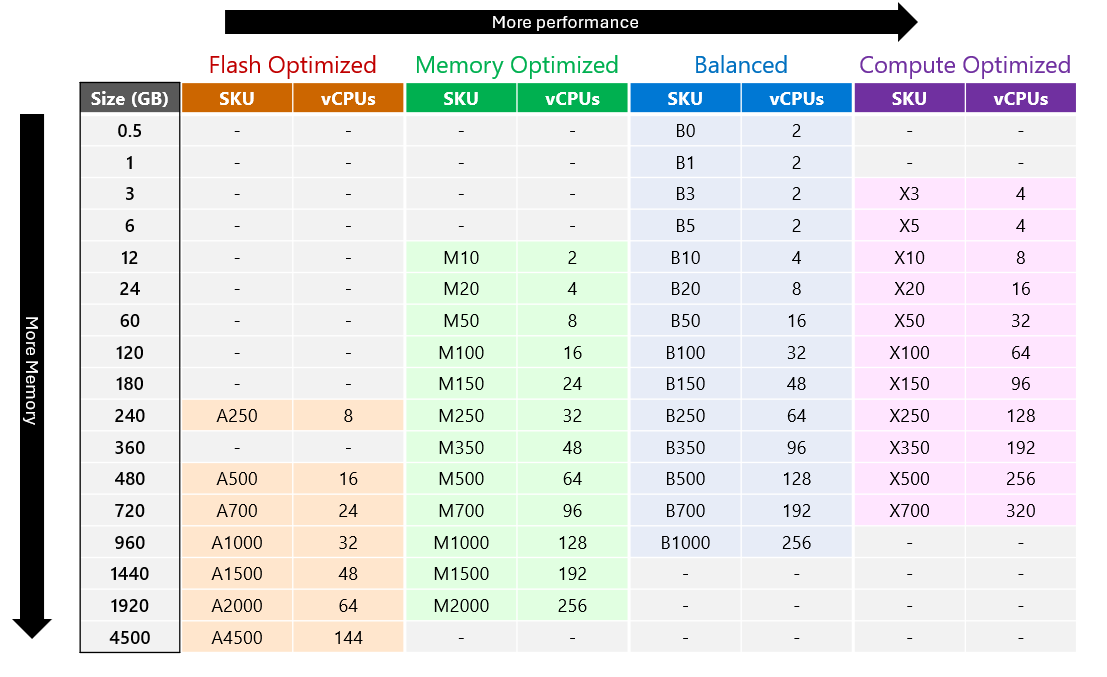
Rendimiento (rendimiento y latencia)
Para obtener pruebas comparativas de rendimiento y más información sobre cómo medir el rendimiento de cada SKU y nivel, consulte Pruebas de rendimiento con Azure Managed Redis
Cuándo se debe escalar
Puede utilizar las características de supervisión de Azure Managed Redis para supervisar el estado y el rendimiento de la memoria caché. Use esa información para determinar cuándo escalar la caché.
Puede supervisar las métricas siguientes para determinar si necesita escalar.
- CPU
- Un uso elevado de CPU significa que el servidor de Redis no puede seguir el ritmo de las solicitudes de todos los clientes. El escalado vertical a más vCPU ayuda a distribuir las solicitudes entre varios procesos de Redis. El escalado también ayuda a distribuir el cifrado/descifrado TLS y la conexión/desconexión, lo que acelera las instancias de caché mediante TLS.
- Uso de memoria
- Un uso elevado de memoria indica que el tamaño de los datos es demasiado grande para el tamaño de caché actual. Considere la posibilidad de escalar a un tamaño de caché con más memoria.
- Conexiones de cliente
- Cada tamaño de caché tiene un límite en el número de conexiones de cliente que puede admitir. Si las conexiones de cliente están cerca del límite del tamaño de caché, considere la posibilidad de escalar a un tamaño de memoria mayor o a un nivel de rendimiento superior.
- Para más información sobre los límites de conexión por tamaño de caché, consulte Pruebas de rendimiento con Azure Managed Redis.
- Ancho de banda de red
- Si el servidor de Redis supera el ancho de banda disponible, las solicitudes de los clientes podrían agotar el tiempo de espera debido a la incapacidad del servidor para insertar datos en el cliente lo suficientemente rápido. Consulta las métricas de "Lectura de caché" y "Escritura de caché" para ver el ancho de banda del lado servidor que se está usando. Si el servidor de Redis supera el ancho de banda de red disponible, considere la posibilidad de escalar a un nivel de rendimiento mayor o a un tamaño de caché mayor.
- La elección de la directiva de clúster afecta al ancho de banda de red disponible. Por lo general, la directiva de clúster de OSS tiene mayor ancho de banda de red que la directiva de clúster de Enterprise. Para obtener más información, consulte Directiva del clúster
- Para más información sobre el ancho de banda disponible de red por tamaño de caché, consulte Pruebas de rendimiento de con Azure Managed Redis.
Para obtener más información sobre cómo determinar el plan de tarifa de caché que se va a usar, consulte Elección del nivel correcto.
Nota:
Para obtener más información sobre cómo optimizar el proceso de escalado, consulte la guía de procedimientos recomendados para el escalado
Requisitos previos y limitaciones del escalado de Azure Managed Redis
- No se puede escalar desde el nivel optimizado para memoria, equilibrado u optimizado para proceso al nivel de optimizado para flash o viceversa.
- No se puede reducir verticalmente de a una SKU con menos vCPU. (Entre niveles o dentro de un nivel).
- No se puede reducir verticalmente a un tamaño de memoria menor, incluso si tiene las mismas o más vCPU.
- En algunos casos al escalar, la dirección IP subyacente de la instancia de Redis puede cambiar. El registro DNS de la instancia cambia y es transparente para la mayoría de las aplicaciones. Sin embargo, si usa una dirección IP para configurar la conexión a la caché o para configurar los grupos de seguridad de red o los firewalls que permiten el tráfico a la caché, puede que la aplicación tenga problemas para conectarse en algún momento después de que el registro DNS se actualice.
- El escalado de una instancia en un grupo de replicación geográfica tiene algunas limitaciones más. Consulte ¿Existen limitaciones de escalado con la replicación geográfica? para obtener más información.
Escalar
Sugerencia
Puede cambiar el tamaño de memoria y el nivel de rendimiento en una sola operación.
Escalar usando Azure Portal
Para escalar la caché, vaya a la caché en Azure Portal y seleccione Escalar en el menú Recursos.
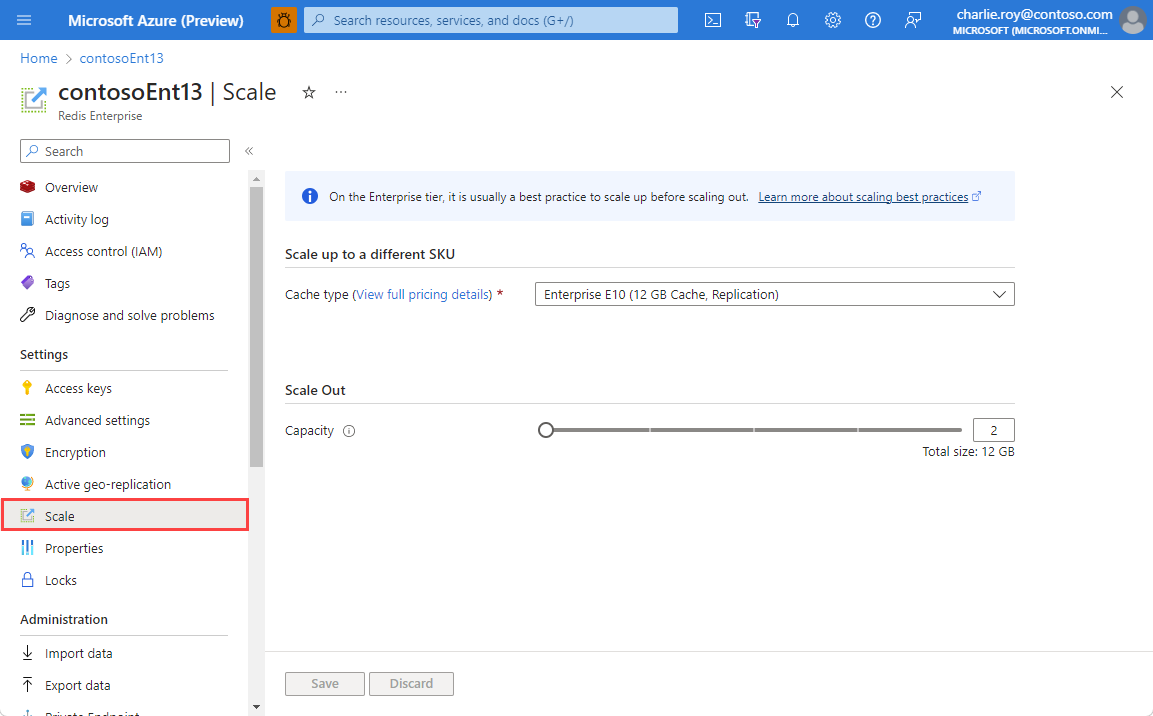
Para escalar verticalmente, elija un tipo de caché diferente y, a continuación, elija Guardar.
Importante
Si selecciona una SKU a la que no se puede escalar, la opción Guardar está deshabilitada. Revise la sección Requisitos previos y limitaciones del escalado de Azure Managed Redis para más información sobre qué opciones de escalado se permiten.
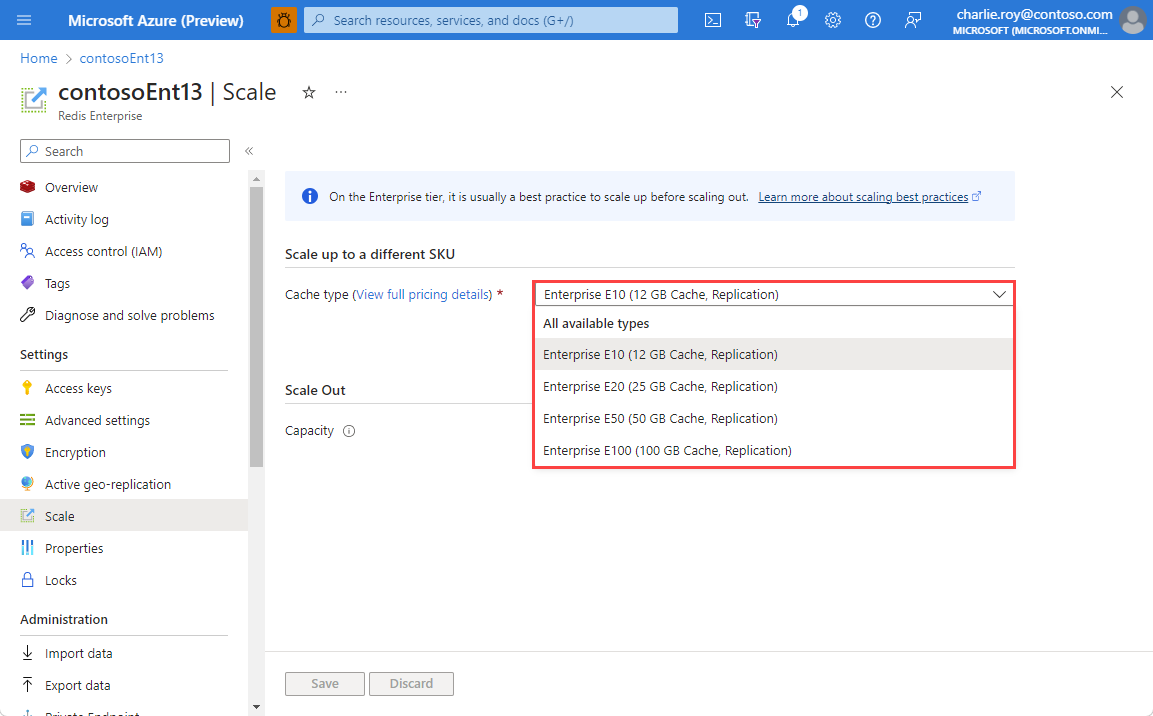
Durante la operación de escalado de la memoria caché al nuevo plan de tarifa, se muestra la notificación Escalando Redis Cache.
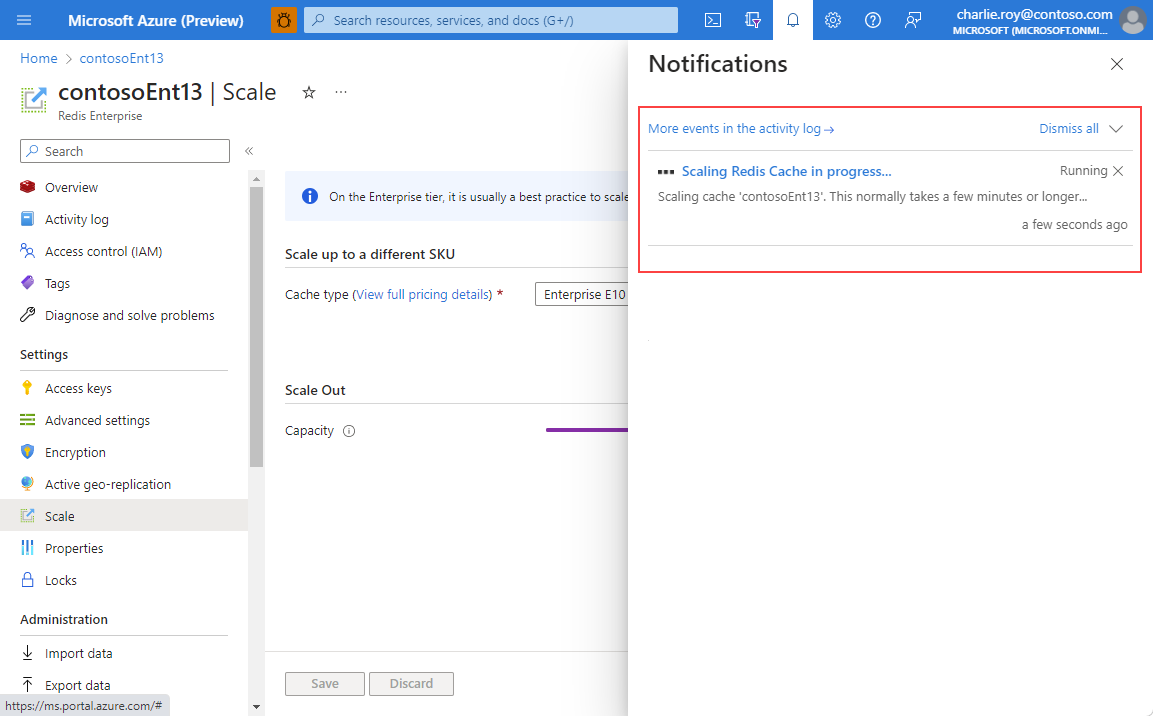
Cuando se completa el escalado, el estado cambia de Escalado a En ejecución.
Escalado mediante PowerShell
Puede escalar las instancias de Azure Managed Redis con PowerShell con el cmdlet Update-AzRedisEnterpriseCache. Puede modificar la propiedad Sku para seleccionar el nivel y la SKU que necesita. En el ejemplo siguiente se muestra cómo escalar una caché denominada myCache a una instancia X20 optimizada para proceso (24 GB).
Update-AzRedisEnterpriseCache -ResourceGroupName myGroup -Name myCache -Sku ComputeOptimized_X20
Escalado con la CLI de Azure
Para escalar las instancias de Azure Managed Redis mediante la CLI de Azure, llame al comando az redisenterprise update. Puede modificar la propiedad sku para seleccionar el nivel y la SKU que necesita. En el ejemplo siguiente se muestra cómo escalar una caché denominada myCache a una instancia X20 optimizada para proceso (24 GB).
az redisenterprise update --cluster-name "myCache" --resource-group "myGroup" --sku "ComputeOptimized_X20"
Preguntas frecuentes de escalado
La lista siguiente contiene las respuestas a las preguntas más frecuentes sobre el escalado de Azure Managed Redis.
- ¿Puedo escalar dentro o entre niveles?
- Después de escalar, ¿tengo que cambiar el nombre de la memoria caché o las teclas de acceso?
- ¿Cómo funciona el escalado?
- ¿Se pierden los datos de mi caché durante el escalado?
- ¿La caché estará disponible durante el escalado?
- ¿Qué limitaciones de escalado se aplican a la replicación geográfica?
- ¿Cuánto tarda el escalado?
- ¿Cómo puedo saber si el escalado ha terminado?
- ¿Azure Managed Redis usa la agrupación en clústeres?¿Cuántas particiones usa cada SKU de Azure Managed Redis?
- ¿Cómo se distribuyen las claves en un clúster?
- ¿Cuál es el mayor tamaño de caché que puedo crear?
- ¿Cuál es la diferencia entre las directivas de clúster de OSS y enterprise?
¿Puedo escalar dentro o entre niveles?
Siempre puede escalar a un nivel de rendimiento superior con el mismo tamaño de memoria o un tamaño de memoria mayor dentro del mismo nivel de rendimiento. Para escalar a un nivel de rendimiento menor o un tamaño de memoria menor, consulte los requisitos previos y las limitaciones de escalado de Azure Managed Redis.
Después de escalar, ¿tengo que cambiar el nombre de la memoria caché o las teclas de acceso?
No, el nombre de la memoria caché y las claves no se cambian durante una operación de escalado.
¿Cómo funciona el escalado?
- Al escalar una instancia de Redis, uno de los nodos del clúster de Redis se apaga y se vuelve a aprovisionar al nuevo tamaño. A continuación, los datos transferidos y, a continuación, el otro nodo realiza una conmutación por error similar antes de que se vuelva a aprovisionar. Esto es similar al proceso que se produce durante la aplicación de revisiones o un error de uno de los nodos de caché.
- Al escalar a una instancia con más vCPU, se aprovisionan y agregan nuevas particiones al clúster del servidor de Redis. A continuación, los datos se vuelven a particionar en todas las particiones.
Para más información sobre cómo Azure Managed Redis controla el particionamiento, consulte configuración de particionamiento.
¿Se pierden los datos de mi caché durante el escalado?
- Si el modo de alta disponibilidad está habilitado, todos los datos deben conservarse durante las operaciones de escalado.
- Si va a reducir verticalmente a un nivel de memoria más pequeño, los datos se pueden perder si el tamaño de los datos supera el nuevo tamaño más pequeño cuando se reduce verticalmente la memoria caché. Si se pierden datos al reducir, las claves se expulsan mediante el directiva de expulsión allkeys-lru .
- Si el modo de alta disponibilidad está deshabilitado, se pierden todos los datos y la memoria caché no está disponible durante la operación de escalado.
¿La caché estará disponible durante el escalado?
- Las instancias de Azure Managed Redis con el modo de alta disponibilidad habilitado siguen estando disponibles durante la operación de escalado. Sin embargo, los puntos de conexión se pueden producir al escalar estas memorias caché. Estas interrupciones momentáneas de conexión son normalmente cortas y los clientes de Redis, por lo general, deberían poder volver a establecer su conexión al instante.
- Si el modo de alta disponibilidad está deshabilitado, la instancia de Azure Managed Redis está sin conexión durante las operaciones de escalado.
¿Qué limitaciones de escalado se aplican a la replicación geográfica?
Con la replicación geográfica activa configurada, no se pueden combinar y coincidir tamaños de caché en un grupo de replicación geográfica. Como resultado, el escalado de las memorias caché en un grupo de replicación geográfica requiere algunos pasos más. Consulte Escalado de instancias en un grupo de replicación geográfica para obtener instrucciones.
¿Cuánto tarda el escalado?
El tiempo de escalado depende de algunos factores. Estos son algunos factores que pueden afectar al tiempo que tarda el escalado.
- Cantidad de datos: las grandes cantidades de datos tardan más tiempo en replicarse.
- Solicitudes de escritura elevadas: un mayor número de escrituras significa más replicaciones de datos entre nodos o particiones.
- Uso elevado de LA CPU: un mayor uso de CPU significa que el servidor de Redis está ocupado y hay ciclos de CPU limitados disponibles para completar la redistribución de datos
Por lo general, al escalar una instancia sin datos, tarda aproximadamente 10 minutos.
¿Cómo puedo saber si el escalado ha terminado?
En Azure Portal puede ver la operación de escalado en curso. Cuando se completa el escalado, el estado de la memoria caché cambia de En ejecución.
¿Azure Managed Redis usa la agrupación en clústeres?
A diferencia de Azure Cache for Redis, Azure Managed Redis usa la agrupación en clústeres en todos los niveles y SKU. La agrupación en clústeres permite optimizaciones de rendimiento significativas. Cada SKU de Azure Managed Redis está configurada para un número optimizado de particiones para el número de vCPU disponibles. El número de particiones no es configurable por el usuario.
¿Cuántas particiones usa cada SKU de Azure Managed Redis?
Dado que Azure Managed Redis se ejecuta en el software de Redis Enterprise, las particiones se pueden usar en una configuración más densa que en Redis de la comunidad. Para obtener información sobre el número específico de particiones usadas en cada SKU, consulte configuración de particionamiento.
¿Cómo se distribuyen las claves en un clúster?
Según la documentación de Redis sobre el modelo de distribución de claves: el espacio de clave se divide en 16 384 ranuras. Cada clave tiene un hash y se asigna a una de estas ranuras, que se distribuyen por todos los nodos del clúster. Puede configurar qué parte de la clave está con hash para asegurarse de que varias claves se encuentran en la misma partición con etiquetas hash.
- Claves con una etiqueta hash: si cualquier parte de la clave está encerrada entre
{y}, se aplica un algoritmo hash únicamente a esa parte de la clave para determinar la ranura hash de una clave. Por ejemplo, las siguientes tres claves se encontrarían en la misma partición:{key}1,{key}2y{key}3, ya que solo se aplica el hash a la partekeydel nombre. Para obtener una lista completa de especificaciones de etiquetas hash de claves, consulte Etiquetas hash de claves. - Claves sin una etiqueta hash: se usa todo el nombre de la clave para aplicar el hash, lo que produce una distribución estadísticamente uniforme entre las particiones de la memoria caché.
Para optimizar el rendimiento, se recomienda distribuir las claves de manera uniforme. Si usa claves con una etiqueta hash, es responsabilidad de la aplicación asegurarse de que las claves se distribuyan de manera uniforme.
Para obtener más información, consulte Modelo de distribución de claves, Particionamiento de datos de clúster Redis y Etiquetas hash de claves.
¿Cuál es el mayor tamaño de caché que puedo crear?
El tamaño de caché más grande que puede tener es de 4,5 TB, denominado instancia de A4500 optimizada para Flash. Precios de Azure Cache for Redis.
¿Cuál es la diferencia entre las directivas de clúster de OSS y enterprise?
La directiva de clúster de OSS es la misma que el enfoque de agrupación en clústeres que se usa en Redis de la edición de la comunidad. Normalmente, la directiva de OSS es más eficaz. La directiva de clúster de empresa implementa la agrupación en clústeres para que parezca un cliente como una instancia de Redis no agrupada. Este enfoque puede ser menos eficaz, pero puede evitar problemas de compatibilidad de cliente. Actualmente no es posible cambiar entre directivas de clúster en una instancia en ejecución. Para obtener más información, consulte Directiva del clúster.