Data Science Toolkit - Linear-log bucketing
Linear-log bucketing is a feature of the Logistic Regression Custom Model Service.
Data binning is a way of pre-processing data that reduces the effects of minor observation errors. Instead of examining all the individual data values in a set, you divide the set into intervals, or buckets, and substitute the value of the bucket for the individual values that fall within it. This is typically used for data where the values are not normally distributed. Data that reflects human activities or human characteristics often have a heavy-tail distribution. There are a lot of smaller value inputs, with values that can get very large but are increasingly rare. There may not be a cap on how large the values can get. Because this data is so spread out, it is difficult to build a strong statistical model from it. If you group like data instead, you can get more data over fewer instances and thus build a stronger model.
For example, we want to build a custom model which uses the cookie age feature. Cookie age is stored in minutes, so it could be a value anywhere from 1 minute to several months (100,000 minutes). Though we might see a significant difference in user actions for users with cookies between 1 minute and 60 minutes old, we probably won't see a significant difference between users with cookies that are 99,000 minutes old and users with cookies that are 99,060 old. We need some way to create smaller, more tightly spaced buckets for the smaller values and larger, more spread-out buckets for the bigger values.
To do this, Xandr uses a technique called linear-log bucketing.
Linear-log bucketing process overview
Linear-log bucketing combines the approaches taken by linear bucketing and log bucketing.
Linear bucketing increases the size of each bucket by the same amount for each interval. For example, if you created buckets that increased by 2 each time, you would have buckets at 2, 4, 6, 8, 10, 12, 14, and so on. This works well for grouping the smaller values into evenly-spaced buckets, but it doesn't solve the problem of grouping the larger, more widely spaced values together. Even if you only have data points between 100,000 and 100,050 you still have buckets at 100,002 ... 100,048.
Log bucketing increases bucket size by a power of two for each interval. This results in buckets at 2, 4, 8, 16, 32, 64, 128, and so on. This works well for grouping large, widely spread values, but has less evenness for intervals between smaller numbers.
Linear-log bucketing uses linear bucketing for a specified initial range and then does logarithmic bucketing for the rest of the values.
This graph plots the increase in bucket sizes. The x-axis is the feature value and the y-axis is the bucket number.
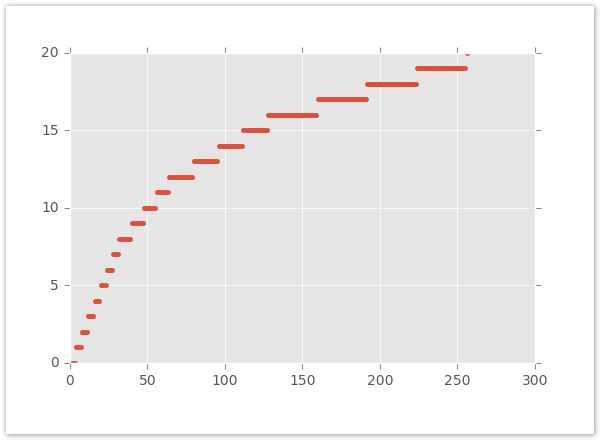
Xandr also supports sub-bucketing to reduce the margin of error and give you more control over how bucketing works. You can create sub-buckets to subdivide each bucket into a few smaller buckets. This is especially helpful at the larger end of your logarithmic range.