Creating and Supporting OpenType Fonts for Sinhala Script
This document presents information that will help font developers in creating OpenType fonts for Sinhala script as covered by the Unicode Standard 6.0. The Sinhala script is used to write the Sinhala language. It is also used to write Pali and Sanskrit.
NOTE: Starting in Windows 10, Sinhala will be supported by the Universal Shaping Engine rather than a stand-alone shaping engine. Moving forward, developers should refer to this new specification.
Introduction
This document targets developers implementing shaping behavior compatible with the Microsoft OpenType specification for the Sinhala script. It contains information about terminology, font features and behavior of the Sinhala shaping engine. While it does not contain instructions for creating Sinhala fonts, it will help font developers understand how the Sinhala shaping engine processes Sinhala text.
Terms
The following terms are useful for understanding the layout features and script rules discussed in this document.
Akhand ligature – A required consonant ligature that may appear anywhere in the syllable and may or may not involve the base glyph. Akhand ligatures have the highest priority and are formed first; some languages include them in their alphabets
Al-lakuna (halant/virama) – The character used after a consonant to suppress its inherent vowel
Base glyph – Any glyph that can have a diacritic mark attached to it. Layout operations are defined in terms of a base glyph, not a base character, as a ligature may act as a base
Character – Each character represents a Unicode character code point. For example the Sinhala letter Ayanna (අ) is U+0D85. A character may have multiple forms of glyphs
Cluster – A group of characters that form an integral unit in Indic scripts, oftentimes this corresponds to a syllable
Consonant – Sinhala consonants have an inherent vowel (the short vowel /a/ called ayanna). For example, “Ka” and “Ta”, rather than just “K” or “T”
Consonant conjunct (aka ‘conjunct’) – A ligature of two or more consonants
Format controls – special formatting characters used in the shaping process of Sinhala scripts (U+200c and U+200D). These characters have no visual appearance, except when an application chooses to display zero width glyphs
Glyph – A glyph represents a form of one or more characters
Halant – See Al-lakuna.
Ligature – A combination of glyphs that join to form a single glyph. For example the touching-letter sequence of alpapraana kayanna and vayanna (U+0D9A, U+0DCA, U+200D, U+0DC0)
Matra (dependent vowel) – Used to represent a vowel sound that is not inherent to the consonant. Dependent vowels are referred to as “matras” in Sanskrit. They are always depicted in combination with a single consonant, or with a consonant cluster. The greatest variation among different Indian scripts is found in the rules for attaching dependent vowels to base characters
OpenType layout engine – The library responsible for executing OpenType layout features in a font. In the Microsoft text formatting stack, it is named OTLS (OpenType layout services)
OpenType tag – A 4-byte identifier for script, language system or feature in the font
Rakaaraansaya (rakar) – The below-base form of “Ra” which forms a ligature with most preceding consonant(s)
Repaya (reph) – The above-base form of the letter “Ra” that is used if “Ra” is the first consonant in the syllable and is not the base consonant
Shaping engine - Code responsible for shaping input, classified to a particular script
Split matra – A matra that is decomposed into pieces for rendering. Usually the different pieces appear in different positions relative to the base. For instance, part of the matra may be placed at the beginning of the cluster and another part at the end of the cluster
Touching letters – A pure consonant written touching a following letter instead of using al-lakuna. Used in classical and Buddhist texts.
Yansaya – The post-base form of “Ya” which goes with a preceding consonant(s)
Shaping Engine
- Analyzing the characters
- Processing split matras
- Reordering characters
- Apply OpenType GSUB features
- Apply OpenType GPOS features
The Uniscribe Sinhala shaping engine processes text in stages. The stages are:
- Analyzing the characters
- Processing split matras
- Reordering characters
- Applying OpenType GSUB features to get the correct glyph shape
- Applying OpenType GPOS features to position glyphs or marks
The descriptions which follow will help font developers understand the rationale for the Sinhala feature encoding model, and help application developers better understand how layout clients can divide responsibilities with operating system functions.
Analyzing the characters
The run of text that the shaping engine receives for the purpose of shaping is a sequence of Unicode characters. The shaping engine divides the text into syllable clusters and identifies character properties. Character properties are used in parsing syllables and identifying their parts as well as determining whether any contextual reordering is required.
Additionally, the engine verifies that the run consists of valid clusters and inserts a placeholder glyph (U+25CC) wherever combining marks occur without a valid base.
In the Sinhala engine, OpenType features are applied to the entire run after any reordering has been completed.
In the diagrams below, the rules for forming clusters are given in terms of the types of characters in the character stream. The meanings of the symbols are:
| C | Consonant (U+0D9A–U+0DB1, U+0DB3–U+0DBB, U+0DBD, U+0DC0–U+0DC6) |
| IV | Independent vowel (U+0D85–U+0D96) |
| H | Halant/Al-lakuna (U+0DCA) |
| VM | Vowel modifier (U+0D82, U+0D83) |
| DV | Dependent vowel (U+0DCF–U+0DD1, U+0DD4, U+0DD6, U+0DD8, U+0DDF, U+0DF2–U+0DF3, U+0DD9, U+0DDB, U+0DD2–U+0DD3, U+0DDA, U+0DDC–U+0DDE) |
| ZWJ | Zero width joiner (U+200D) |
| { } | Zero to many occurrences. Because this could theoretically go on forever, an arbitrary limit of eight occurrences has been set. |
| [ ] | Optional occurrence |
| < x | y > | Choice of x or y |
There are two types of clusters:
| Consonant Cluster | |
| {C + H + ZWJ } + C + [< H | DV >] + [VM] | Used for semivowel and ligature clusters |
| {C + ZWJ + H} + C + [< H | DV >] + [VM] | Used for clusters of touching letters |
| Independent Vowel Cluster | |
| IV + [VM] | |
Processing split matras
The shaping engine inserts the prebase component of the split matras into the glyph sequence. The following split matras are defined for Sinhala:
| Code point | Glyph | Description |
|---|---|---|
|
U+0DDA |
 |
Sinhala vowel sign diga kombuva |
|
U+0DDC |
 |
Sinhala vowel sign kombuva haa aela-pilla |
|
U+0DDD |
 |
Sinhala vowel sign kombuva haa diga aela-pilla |
|
U+0DDE |
 |
Sinhala vowel sign kombuva haa gayanukitta |
The shaping engine will insert the glyph for U+0DD9 into the glyph sequence to serve as the prebase component for subsequent reordering. The second component of the split matras should be substituted appropriately by the font using the pstf feature, see Basic shaping forms.
Reordering characters
Once the Sinhala shaping engine has analyzed the run as described above, it creates a buffer of appropriately reordered elements (glyphs) representing the cluster according to the following rules:
- Prebase vowels and prebase vowel-components of split matras reorder to start of a cluster
- Yansaya fuses with a preceding base glyph
- Repaya reorders after the base glyph or after yansaya if also present
The OpenType lookups in a Sinhala font must be written to match glyph sequences after re-ordering has occurred. OpenType fonts should not have substitutions that attempt to perform the re-ordering. If a font developer attempted to encode such reordering information in an OpenType font, they would need to add a huge number of many-to-many glyph mappings to cover the general algorithms that a shaping engine will use.
Apply OpenType GSUB features
Uniscribe calls OTLS to apply the features. All OTL processing is divided into a set of predefined features (described and illustrated in the Feature section of this document). Each feature is applied to the entire run and OTLS processes them. Uniscribe makes as many calls to the OTL Services as there are features. This ensures that the features are executed in the desired order.
The steps of the shaping process are outlined below. Not all of the features listed must be used by all languages using the Sinhala script.
Shaping features:
- Localized forms
- Apply feature ‘locl’ to preprocess any localized forms for the current language
- Basic shaping forms
- Apply feature ‘ccmp’ to preprocess any glyphs that require composition or decomposition
- Apply feature ‘akhn’ to get akhand ligature forms
- Apply feature ‘rphf’ to get repaya glyph forms
- Apply feature ‘vatu’ to get rakaaraansaya and yansaya glyph forms
- Apply feature ‘pstf’ to get post-base forms of split-matra glyphs
- Presentation forms
- Apply feature ‘pres’ to substitute prebase glyph forms
- Apply feature ‘abvs’ to substitute above-base glyph forms
- Apply feature ‘blws’ to substitute below-base glyph forms
- Apply feature ‘psts’ to substitute postbase glyph forms
Note: since the presentation form features are applied simultaneously over the entire cluster, several features are operationally equivalent to a single feature. Multiple features are provided as an aid for font developers to organize the lookups they implement.
Apply OpenType GPOS features
The shaping engine next processes the GPOS (glyph positioning) table, applying features concerned with positioning. All features are applied simultaneously to the entire cluster.
The font developer must consider the effects of re-ordering when creating the GPOS feature and lookup tables (i.e., the glyphs will be in the order they were in after the GSUB presentation forms features were applied).
- Kerning
- Apply feature ‘kern’ to provide pair kerning between glyphs for better typographic quality. Note this feature may be disabled by some applications
- Apply feature ‘dist’ to make any required distance adjustments
- Mark placement
- Apply feature ‘abvm’ to position diacritic glyphs above the base glyph
- Apply feature ‘blwm’ to position diacritic glyphs below the base glyph
Features
The features listed below have been defined to create the basic forms for the scripts and languages that are supported on Sinhala systems. Regardless of the model an application chooses for supporting layout of complex scripts, Uniscribe requires a fixed order for executing features within a run of text to consistently obtain the proper basic form. This is achieved by calling features one-by-one in the standard order listed below.
The order of the lookups within each feature is also very important. For more information on lookups and defining features in OpenType fonts, see Encoding feature information in the OpenType font development section.
The standard order for applying Sinhala features encoded in OpenType fonts:
| Feature | Feature function | Layout operation | Required |
|---|---|---|---|
| Localized forms | |||
|
locl |
GSUB |
||
| Basic shaping forms | |||
|
ccmp |
Character composition/decomposition substitution |
GSUB |
|
|
akhn |
Akhand ligature substitution |
GSUB |
X |
|
rphf |
Repaya substitution |
GSUB |
X |
|
vatu |
Rakaaraansaya and yansaya substitution |
GSUB |
X |
|
pstf |
Post-base form substitution |
GSUB |
X |
| Presentation forms | |||
|
pres |
Pre-base substitution |
GSUB |
|
|
abvs |
Above-base substitution |
GSUB |
|
|
blws |
Below-base substitution |
GSUB |
|
|
psts |
Post-base substitution |
GSUB |
|
| Kerning: | |||
|
kern |
Pair kerning |
GPOS |
|
|
dist |
Distance adjustments |
GPOS |
|
| Mark placement | |||
|
abvm |
Above-base mark positioning |
GPOS |
|
|
blwm |
Below-base mark positioning |
GPOS |
|
| [GSUB = glyph substitution, GPOS = glyph positioning] | |||
Feature examples
The registered features described and illustrated in this document are based on the Microsoft OpenType font Iskoola Pota (iskpota.ttf). Iskoola Pota contains layout information and glyphs to support all of the required features for the Sinhala script.
The illustrations in the following examples show the result of that particular feature being applied. Features must be written to match glyph sequences after re-ordering has occurred. Note that the input context for a feature may be the result of a previous feature having already been applied.
Localized forms
Feature Tag: 'locl'
This feature is used in association with OpenType language system tags to trigger lookups that will select alternate glyphs needed for language-specific typographic conventions. The ‘locl’ should not be used in association with the default language system, but only used with other language system tags. See the Appendix of this document for language system tags associated with the Sinhala script. The Iskoola Pota font does not use this feature.
Basic shaping forms
Feature Tag: 'ccmp'
The composition/decomposition feature may be used to trigger lookups to form particular composed or decomposed forms. It should not be used to create decompositions of the split matras as this is done by the shaping engine before any features are applied. The Iskoola Pota font does not use this feature.
Feature Tag: 'akhn'
The akhand ligature feature is used to create all required ligatures including touching consonants used in Pali and Sanskrit.
Ligatures that are used in Sinhala text are encoded using the sequence Halant ZWJ (U+0DCA U+200D) between the two components that are to be joined.
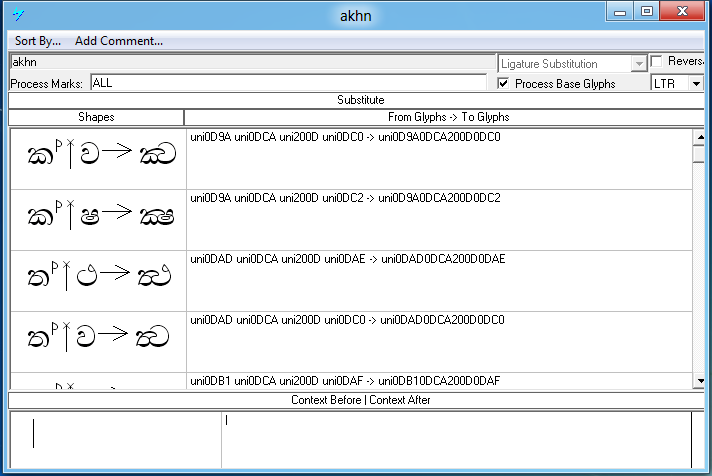
Lookup example:
| Sequence | Result | |
|---|---|---|
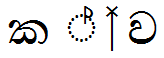 |
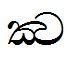 |
ක්ව |
|
U+0D9A U+0DCA U+200D U+0DC0 |
Image |
Text |
Touching consonants that are used in Pali and Sanskrit are encoded with the sequence ZWJ Halant (U+200D U+0DCA) between the two components that are to be joined.

Lookup example:
| Sequence | Result | |
|---|---|---|
 |
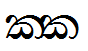 |
ක්ක |
|
U+0D9A U+200D U+0DCA U+0D9A |
Image |
Text |
Feature Tag: 'rphf'
This feature is used to substitute the repaya form.
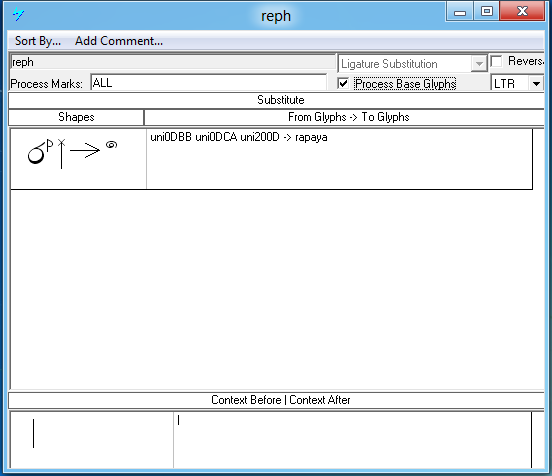
Example:
| Sequence | Result | |
|---|---|---|
 |
 |
ර්ක |
|
U+0DBB U+0DCA U+200D U+0D9A |
Image | Text |
Feature Tag: 'vatu'
This feature is used to substitute the rakaaraansaya and yansaya forms.
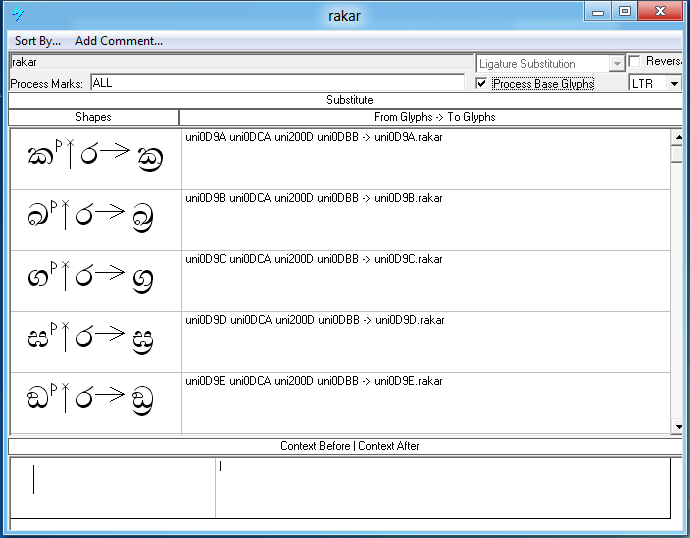
Rakaaraansaya example:
| Sequence | Result | |
|---|---|---|
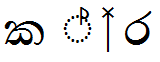 |
 |
ක්ර |
|
U+0D9A U+0DCA U+200D U+0DBB |
Image |
Text |
Yansaya example:
| Sequence | Result | |
|---|---|---|
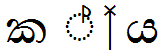 |
 |
ක්ය |
|
U+0D9A U+0DCA U+200D U+0DBA |
Image |
Text |
Feature Tag: 'pstf'
This feature is used to convert a split matra into the corresponding second half of the split matra.

Lookup example:
| Sequence | Result | |
|---|---|---|
 |
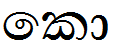 |
කො |
|
U+0D9A U+0DDC |
Image |
Text |
Presentation forms
Feature Tag: 'pres'
This feature may be used to substitute presentation forms involving pre-base elements. The Iskoola Pota font does not use this feature.
Feature Tag: 'abvs'
This feature is used to substitute ligatures involving a base glyph and an above mark.
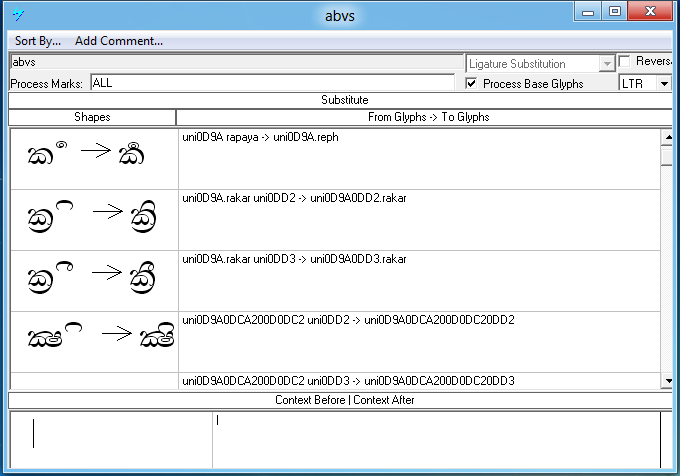
Lookup example:
| Sequence | Result | |
|---|---|---|
 |
 |
කි |
|
U+0D9A U+0DD2 |
Image |
Text |
This should also include marks that are the outcome of previous lookups and reordering such as rakaaraansaya and yansaya.
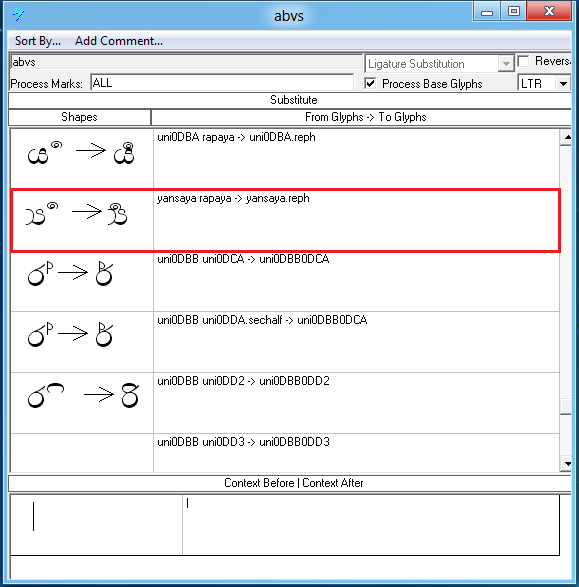
Rakaaraansaya + yansaya example:
| Sequence | Result | |
|---|---|---|
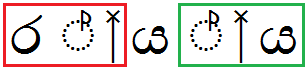 |
 |
ර්ය්ය |
|
U+0DBB (rakaaraansaya) U+0DCA U+200D U+0DBA U+0DCA (yansaya) U+200D U+0DBA |
Image |
Text |
Feature Tag: 'blws'
This feature is used to substitute ligatures involving a base glyph and a below mark.
Lookup example:
| Sequence | Result | |
|---|---|---|
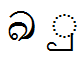 |
 |
ඛු |
|
U+0D9B U+0DD4 |
Image |
Text |
Feature Tag: 'psts'
This feature is used to substitute ligatures involving a base glyph and a post-base element.

Lookup example:
| Sequence | Result | |
|---|---|---|
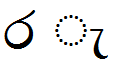 |
 |
රැ |
|
U+0DBB U+0DD0 |
Image |
Text |
Kerning
Feature Tag: 'kern'
This feature may be used to adjust the positioning of glyph pairs. The Iskoola Pota font does not use this feature.
Feature Tag: 'dist'
This feature may be used to adjust distances. The Iskoola Pota font does not use this feature.
Mark placement
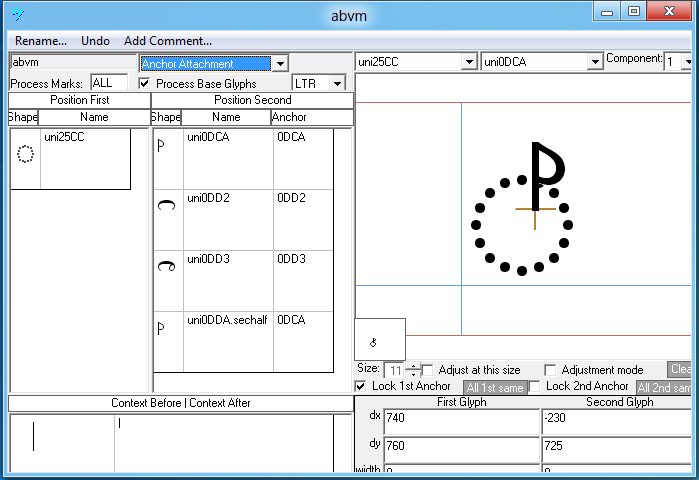
Feature Tag: 'abvm'
This feature is used to position marks above base glyphs. The Iskoola Pota font uses this feature to position marks relative to the dotted circle placeholder glyph.
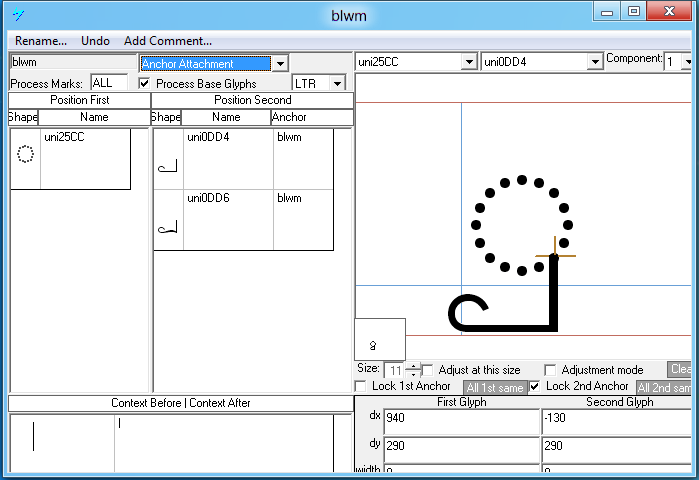
Feature Tag: 'blwm'
This feature is used to position marks below base glyphs. The Iskoola Pota font uses this feature to position marks relative to the dotted circle placeholder glyph.
Handling invalid combining marks
Combining marks and signs that do not occur in conjunction with a valid base are considered invalid. Shaping engine implementations may adopt different strategies for how invalid marks are handled. For example, a shaping engine implementation might treat an invalid mark as a separate cluster and display the stand-alone mark positioned on some default base glyph, such as a dotted circle (U+25CC). (See Fallback Rendering in section 5.13 of the Unicode Standard 4.0.) Shaping engine implementations may vary somewhat with regard to what sequences are or are not considered valid. For instance, some implementations may impose a limit of at most one above-base vowel mark while others may not.
To allow for shaping engine implementations that expect to position an invalid mark on a dotted circle, it is recommended that a Sinhala OT font contain a glyph for the dotted circle character, U+25CC. If this character is not supported in the font, such implementations will display invalid signs on the missing glyph shape (white box).
Recommended Glyphs
Unicode code points that are strongly recommended for inclusion in any Sinhala font are:
| Code point | Description |
|---|---|
|
U+200B |
Zero Width Space |
|
U+200C |
Zero Width Non-Joiner |
|
U+200D |
Zero Width Joiner |
|
U+25CC |
Dotted Circle |
Appendix
Appendix: Writing system and language tags
Features are encoded according to both a designated script and language system. The language system tag specifies a typographic convention associated with a language or linguistic subgroup. For example, there are different language systems defined for the Sinhala script; Sinhala, Pali, and Sanskrit.
Currently, the Uniscribe engine only supports the “default” language for each script. However, font developers may want to build language specific features which are supported in other applications and will be supported in future Microsoft OpenType implementations.
- NOTE: It is strongly recommended to include the “dflt” language tag in all OpenType fonts because it defines the basic script handling for a font. The “dflt” language system is used as the default if no other language specific features are defined or if the application does not support that particular language. If the “dflt” tag is not present for the script being used, the font may not work in some applications.
The following tables list the registered tag names for scripts and language systems.
| Registered tags for the Sinhala script | Registered tags for Sinhala language systems | ||
|---|---|---|---|
| Script tag | Script | Language system tag | Language |
|
'sinh' |
Sinhala |
'dflt' |
*default script handling |
|
'SNH ' |
Sinhala |
||
|
'PAL ' |
Pali |
||
|
“SAN” |
Sanskrit |
||
Note: both the script and language tags are case sensitive (script tags should be lowercase, language tags are all caps) and must contain four characters (ie. you must add a space to the three character language tags).
Script development specifications