Combine and optimize data
Organizations often collate different types of information from many sources. The information is stored in a large number of tables. Occasionally, you might need to join tables based on logical relationships between them, for deeper analysis or reporting. In the retail company scenario, you use tables for customers, products, and sales information.
In this module, you learn about various ways to combine data in Kusto queries to give your team members the information they need to increase product awareness and grow sales.
Understand your data
Before you start writing queries that combine information from your tables, you need to understand your data. When you work with Kusto queries, you want to think of tables as broadly belonging to one of two categories:
- Fact tables: Tables whose records are immutable facts, such as the SalesFact table in the retail company scenario. In these tables, records are progressively appended in a streaming fashion or in large chunks. The records stay in the table until they're removed and they're never updated.
- Dimension tables: Tables whose records are mutable dimensions, such as the Customers and Products tables in the retail company scenario. These tables hold reference data, such as lookup tables from an entity identifier to its properties. Dimension tables aren't regularly updated with new data.
In our retail company scenario, you use dimension tables to enrich the SalesFact table with additional information or to provide more options for filtering the data for queries.
You also want to understand the volumes of data you're working with and its structure, or schema (column names and types). You can run the following queries to get that information by replacing TABLE_NAME with the name of the table you're examining:
To get the number of records in a table, use the
countoperator:TABLE_NAME | countTo get the schema of a table, use the
getschemaoperator:TABLE_NAME | getschema
Running these queries on the fact and dimension tables in the retail company scenario gives you information like the following example:
| Table | Records | Schema |
|---|---|---|
| SalesFact | 2,832,193 | - SalesAmount (real) - TotalCost (real) - DateKey (datetime) - ProductKey (long) - CustomerKey (long) |
| Customers | 18,484 | - CityName (string) - CompanyName (string) - ContinentName (string) - CustomerKey (long) - Education (string) - FirstName (string) - Gender (string) - LastName (string) - MaritalStatus (string) - Occupation (string) - RegionCountryName (string) - StateProvinceName (string) |
| Products | 2,517 | - ProductName (string) - Manufacturer (string) - ColorName (string) - ClassName (string) - ProductCategoryName (string) - ProductSubcategoryName (string) - ProductKey (long) |
In the table, we highlighted the unique identifiers CustomerKey and ProductKey that are used to combine records between tables.
Understand multi-table queries
After analyzing your data, you need to understand how to combine tables to provide the information you need. Kusto queries provide several operators that you can use to combine data from multiple tables, including the lookup, join, and union operators.
The join operator merges the rows of two tables by matching values of the specified columns from each table. The resulting table depends on the kind of join you use. For example, if you use an inner join, the table has the same columns as the left table (sometimes called the outer table), plus the columns from the right table (sometimes called the inner table). You learn more about join kinds in the next section. For best performance, if one table is always smaller than the other, use it as the left side of the join operator.
The lookup operator is a special implementation of a join operator that optimizes the performance of queries where a fact table is enriched with data from a dimension table. It extends the fact table with values that are looked up in a dimension table. For best performance, the system by default assumes that the left table is the larger (fact) table, and the right table is the smaller (dimension) table. This assumption is exactly the opposite of the assumption used by the join operator.
The union operator returns all the rows from two or more tables. It's useful when you want to combine data from multiple tables.
The materialize() function caches results within a query execution for subsequent reuse in the query. It's like taking a snapshot of the results of a subquery and using it multiple times within the query. This function is useful in optimizing queries for scenarios where the results:
- Are expensive to compute
- Are nondeterministic
Shortly, you learn more about the various table merging operators and the materialize() function, and how to use them.
Kinds of join
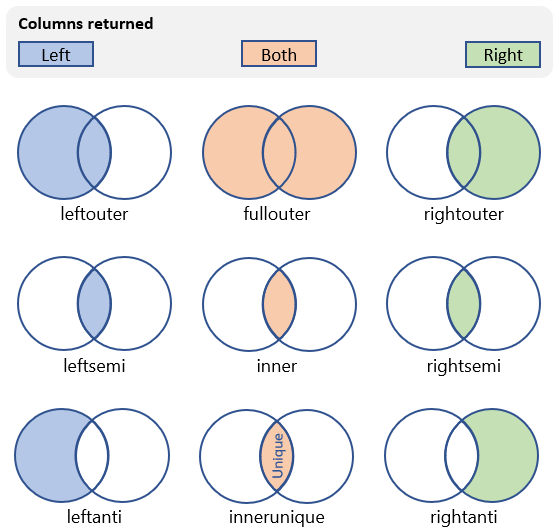
There are many different kinds of joins that can be performed that affect the schema and rows in the resultant table. The following table shows the kinds of joins supported by the Kusto Query Language and schema and rows they return:
| Join kind | Description | Illustration |
|---|---|---|
innerunique (default) |
Inner join with left side deduplication Schema: All columns from both tables, including the matching keys Rows: All deduplicated rows from the left table that match rows from the right table |
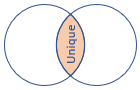
|
inner |
Standard inner join Schema: All columns from both tables, including the matching keys Rows: Only matching rows from both tables |
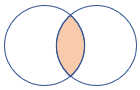
|
leftouter |
Left outer join Schema: All columns from both tables, including the matching keys Rows: All records from the left table and only matching rows from the right table |
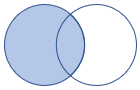
|
rightouter |
Right outer join Schema: All columns from both tables, including the matching keys Rows: All records from the right table and only matching rows from the left table |
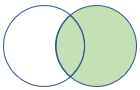
|
fullouter |
Full outer join Schema: All columns from both tables, including the matching keys Rows: All records from both tables with unmatched cells populated with null |
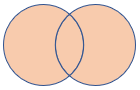
|
leftsemi |
Left semi join Schema: All columns from the left table Rows: All records from the left table that match records from the right table |
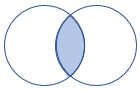
|
leftanti, anti, leftantisemi |
Left anti join and semi variant Schema: All columns from the left table Rows: All records from the left table that don't match records from the right table |
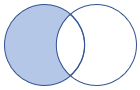
|
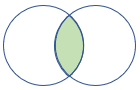
rightsemi |
Right semi join Schema: All columns from the right table Rows: All records from the right table that match records from the left table |
|
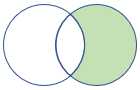
rightanti, rightantisemi |
Right anti join and semi variant Schema: All columns from the right table Rows: All records from the right table that don't match records from the left table |
|
Notice that the default join kind is innerunique, and it doesn't need to be specified. Nevertheless, it's a best practice to always explicitly specify the join kind for clarity.
As you progress through this module, you also learn about the arg_min() and arg_max() aggregation functions, the as operator as an alternative to the let statement, and the startofmonth() function to assist with grouping data by month.