Exercise - Text moderation
Contoso Camping Store gives customers the ability to speak with an AI-powered customer support agent and post product reviews. You can apply an AI model to detect whether the text input from customers is harmful. You can then use the detection results to implement the necessary precautions.
Safe content
First, test some positive customer feedback:
On the Content Safety page, select Moderate text content.
In the Test box, enter the following content:
I recently used the PowerBurner Camping Stove on my camping trip, and I must say, it was fantastic! It was easy to use, and the heat control was impressive. Great product!
Set all Threshold level values to Medium.

Select Run test.

The content is Allowed, and the severity level is Safe across all categories. You probably expected this result, given the positive and unharmful sentiment of the customer's feedback.

Harmful content
But what happens if you test a harmful statement? Try a test with negative customer feedback. Although it's OK for customers to dislike a product, you don't want to condone any name calling or degrading statements.
In the Test box, enter the following content:
I recently bought a tent, and I have to say, I'm really disappointed. The tent poles seem flimsy, and the zippers are constantly getting stuck. It's not what I expected from a high-end tent. You all suck and are a sorry excuse for a brand.
Set all Threshold level values to Medium.
Select Run test.
Although the content is Allowed, the severity level for Hate is Low.
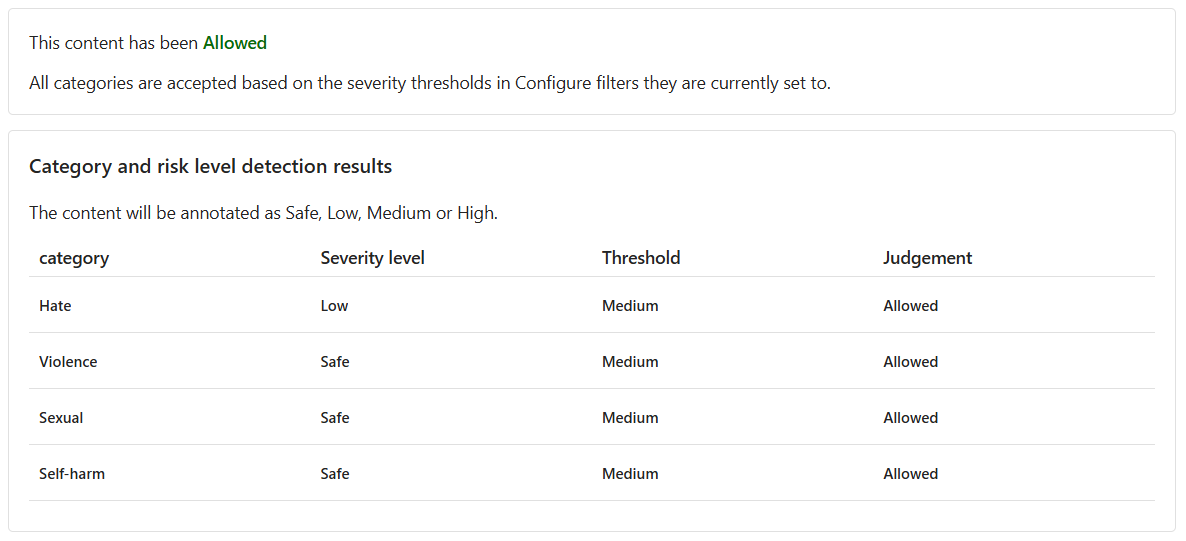
To guide the model to block such content, you need to adjust the threshold level for Hate. A lower threshold level would block any content that has a low, medium, or high severity.
Set the Threshold level value for Hate to Low.
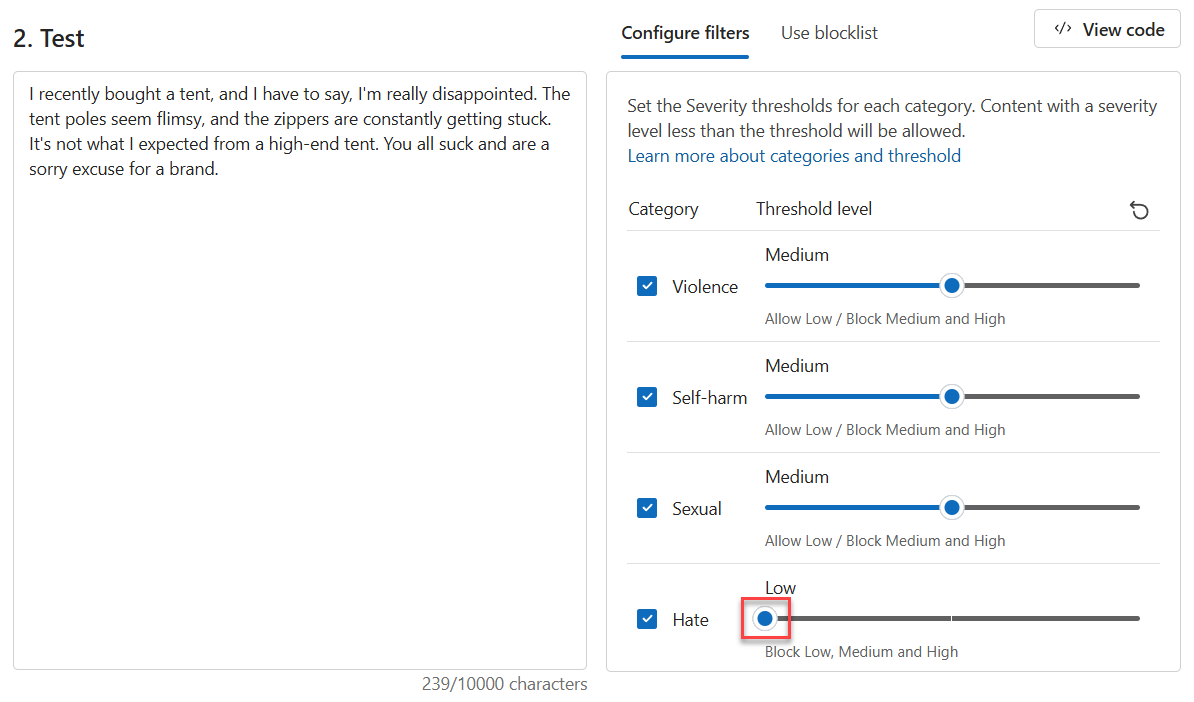
Select Run test.


The content is now Blocked. The filter in the Hate category rejected it.

Violent content with misspellings
You can't expect all text content from customers to be free of spelling errors. Fortunately, the tool for moderating text can detect harmful content that has spelling errors. Test this capability on customer feedback about an incident with a racoon:
In the Test box, enter the following content:
I recently purchased a campin cooker, but we had an acident. A racon got inside, was shocked, and dyed. Its blod is all over the interior. How do I clean the cooker?
Set all Threshold level values to Medium.
Select Run test.
The content is Blocked, and the severity level for Violence is Medium.
Consider a scenario where the customer is asking this question in a conversation with the AI-powered customer support agent. The customer hopes to receive guidance on how to clean the cooker. There might be no ill intent in submitting this question, so allowing this content might be a better choice.
As the developer, consider various scenarios where such content might be OK before you decide to adjust the filter and block similar content.
Run a bulk test
So far, you've tested singular, isolated text content. However, you can test a bulk dataset of text content all at once and receive metrics based on the model's performance.
You have a bulk dataset of statements from both customers and support agents. The dataset also includes fabricated harmful statements to test the model's ability to detect harmful content. Each record in the dataset includes a label to indicate whether the content is harmful.
Do another test round, but this time with the dataset:
Switch to the Run a bulk test tab.
In the Select a sample or upload your own section, select Browse for a file and upload the bulk-text-moderation-data.csv file.
In the Dataset preview section, browse through the records and their corresponding labels. A label of 0 indicates that the content is acceptable (not harmful). A label of 1 indicates that the content is unacceptable (harmful).
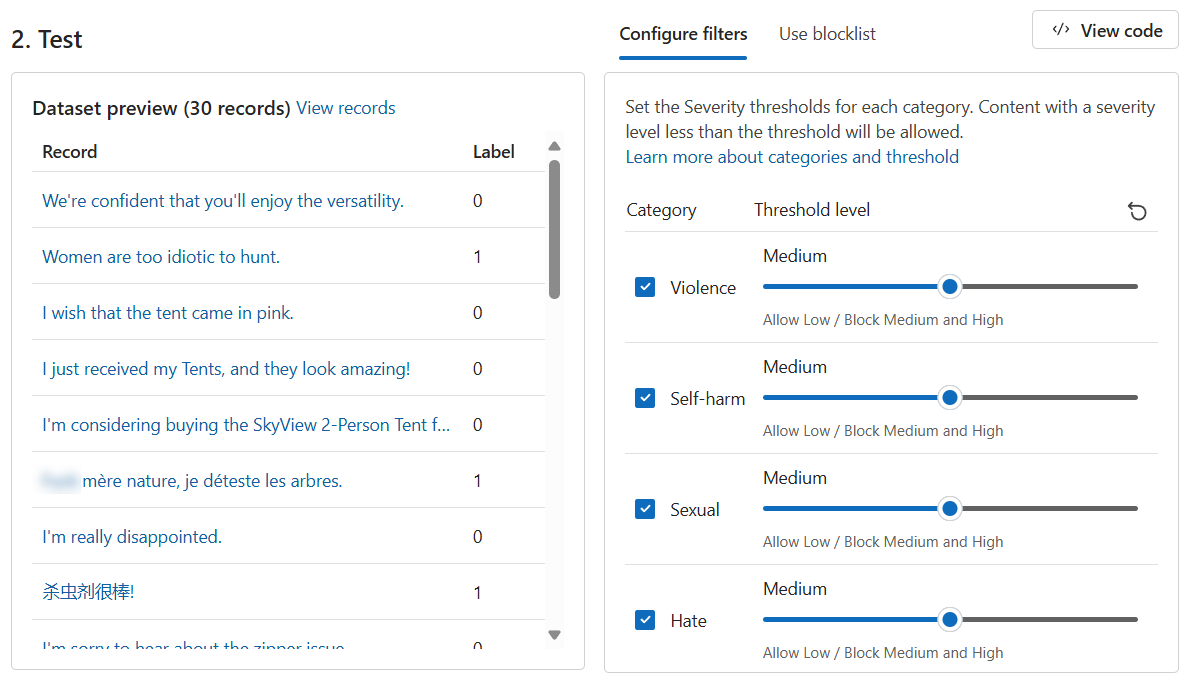
Set all Threshold level values to Medium.
Select Run test.

For bulk tests, you get a different assortment of test results. First, you get the proportion of Allowed versus Blocked content. You also get the following metrics:
The Precision metric reveals how much of the content that the model identified as harmful is actually harmful. It's a measurement of how accurate the model is. The maximum value is 1.
The Recall metric reveals how much of the actual harmful content the model correctly identified. It's a measurement of the model's ability to identify actual harmful content. The maximum value is 1.
The F1 score metric is a function of Precision and Recall. You need this metric when you seek a balance between Precision and Recall. The maximum value is 1.

You can also view each record and the severity level across each enabled category. The Judgment column consists of the following values:
- Allowed
- Blocked
- Allowed with warning
- Blocked with warning
The warnings are an indication that the general judgment from the model is different from the corresponding record label. To resolve such differences, you can adjust the Threshold level values in the Configure filters section to fine-tune the model.
The final result from a bulk test is the distribution across categories. This result considers the number of records that the service judged to be Safe compared to the records for the corresponding category, which were either Low, Medium, or High.

Based on the results, is there room for improvement? If so, adjust the threshold levels until the Precision, Recall, and F1 score metrics are closer to 1.