What is Azure HDInsight?
Let's review the features and uses of HDInsight. This overview will help you evaluate whether HDInsight addresses your organization's requirements.
What is big data?
The term big data describes the vast volumes of structured and unstructured data that organizations collect. This data can be extremely useful for organizations. Specifically, if an organization can analyze the data for insights, it's better able to make decisions. The result is that these decisions can help an organization become more successful. For example, big-data analysis might enable a commercial organization to recognize customer habits, which could lead to increased sales.
Azure HDInsight definition
Azure HDInsight is a fully managed, cloud-based, open-source analytics service for enterprises. HDInsight enables you to control and manage your big data. HDInsight:
Is a cloud distribution of Hadoop components.
Makes it easier, faster, and more cost-effective to process huge volumes of data.
Supports the use of open-source frameworks, such as:
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Note
With these frameworks, you can enable a broad range of scenarios such as extract, transform, and load (ETL), data warehousing, machine learning, and IoT.
HDInsight provides several benefits for organizations that are working with big data. It's:
Open-source: Enables you to create optimized clusters for various open-source frameworks.
Reliable: Provides an end-to-end SLA for all production workloads.
Scalable: Enables you to scale workloads to respond to demand changes.
Tip
By creating clusters on demand, you can reduce your costs. You pay only for what you use.
Secure: Enables you to protect your enterprise data assets through integration with:
- Azure Virtual Network
- Azure encryption technologies
- Microsoft Entra ID
Compliant: Meets popular industry and government compliance standards.
Monitored: Integrates with Azure Monitor logs to provide a single interface. Monitor all clusters by using the single interface.
How HDInsight can help you work with big data
You can use HDInsight for many scenarios utilizing big-data processing. Your data can be:
- Historical data: This data is already collected and stored.
- Real-time data: This data is directly streamed from the source.
The following categories summarize the processing scenarios for this data:
- Batch processing
- Data warehousing
- IoT
- Data science
- Hybrid
Let's examine these categories more closely.
Batch processing
Organizations use batch-processing jobs to prepare big data for further analysis. Typically, this process involves three stages:
- Reading source data files from heterogeneous data sources.
- Processing the data.
- Writing the data to scalable storage.
Note
This process is often referred to as ETL.
You can use the transformed data for data warehousing or data science.
Tip
A significant requirement for ETL is compute scale-out. This enables processing of large data volumes.
Data warehousing
A data warehouse provides an organization with somewhere to store big data while waiting to analyze it. Data warehousing allows you to:
- Store your data.
- Prepare your data for analysis.
- Provide the prepared data in a structured format. You then can query the data by using analytical tools.
The following diagram depicts how Apache Hadoop on HDInsight gathers and stores data from several sources. Apache Spark and Apache Hive prepare and analyze the data. Finally, the data is modeled for use with business intelligence (BI) tools. Power BI is used for data visualization.
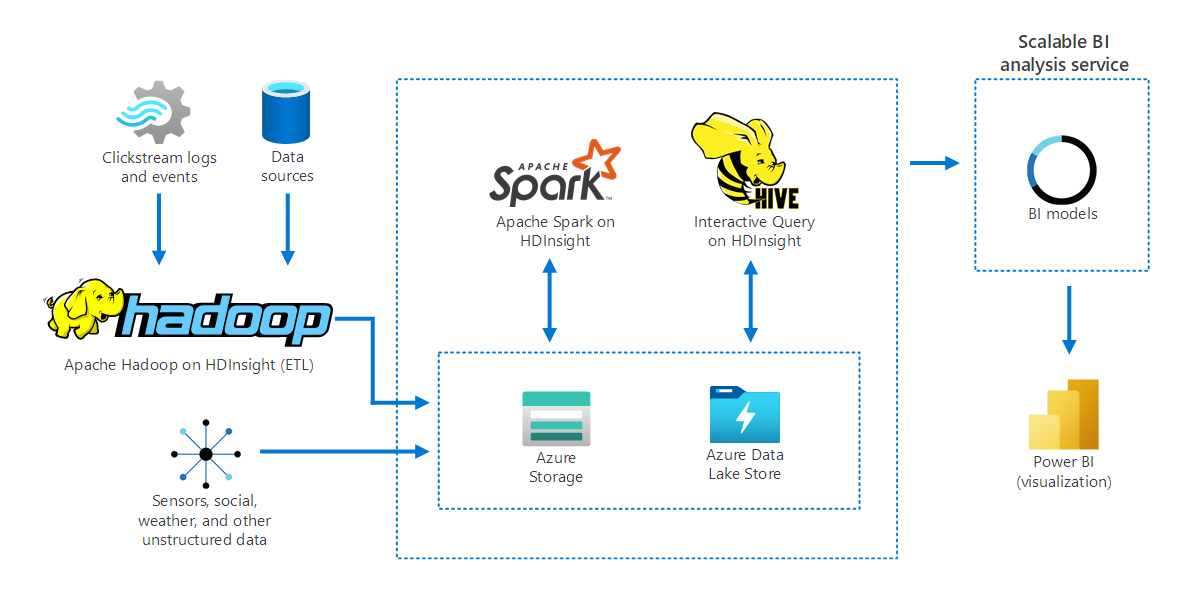
Components in this scenario include:
- Apache Spark is a parallel processing framework. It supports in-memory processing, which helps boost the performance of big-data analytic applications.
- Apache Hive in HDInsight is a data warehouse system for Apache Hadoop. Hive enables data summarization, querying, and analysis. You can use these components to perform queries at petabyte scales on structured and unstructured data, in any format.
Tip
Hive queries are written in HiveQL, a query language similar to SQL.
Internet of things
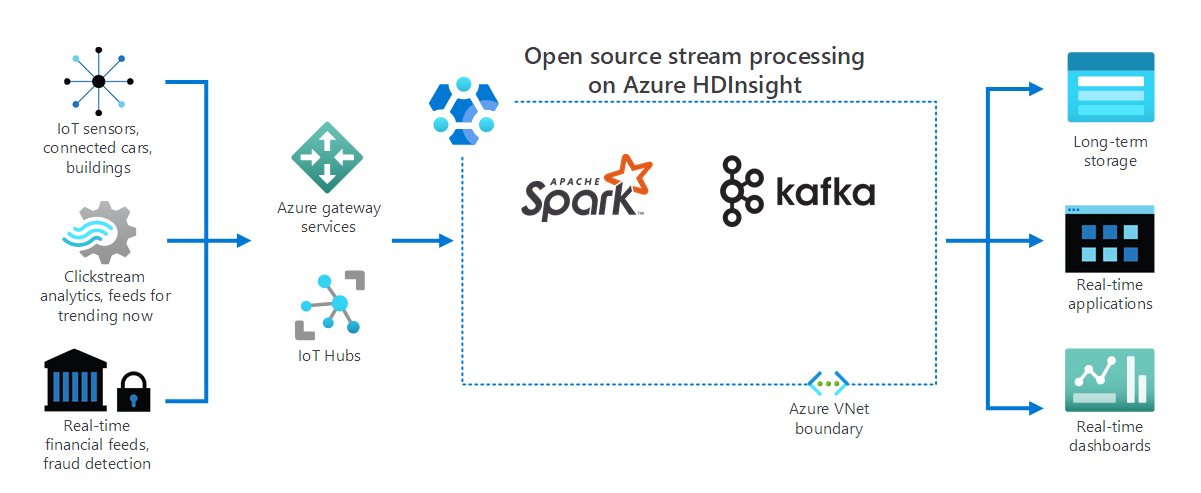
As the following diagram depicts, HDInsight processes streaming data received in real time from different devices and sensors. In this example, several open-source frameworks provide stream processing, including Apache Spark and Apache Kafka.
Azure gateway services and IoT hubs direct data from various sources to these frameworks. The frameworks then process the data, and it passes to:
- Long-term storage.
- Real-time apps.
- Real-time dashboards.
Data science
You can use HDInsight to complete common data-science tasks such as:
- Data ingestion.
- Feature engineering.
- Modeling.
- Model evaluation.
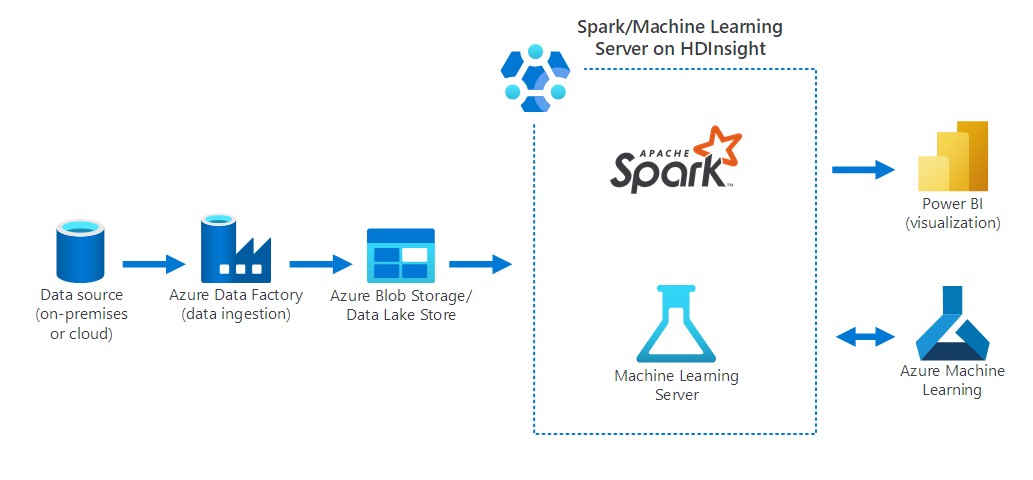
The following diagram depicts a data-science scenario, in which:
- Data is collected from an on-premises data source by using Azure Data Factory.
- The ingested data is then stored in Azure storage (either Azure Blob Storage or a Data Lake Store).
- Azure Spark on HDInsight processes and prepares the data for Azure Machine Learning. Data is also visualized by using Power BI.
Hybrid
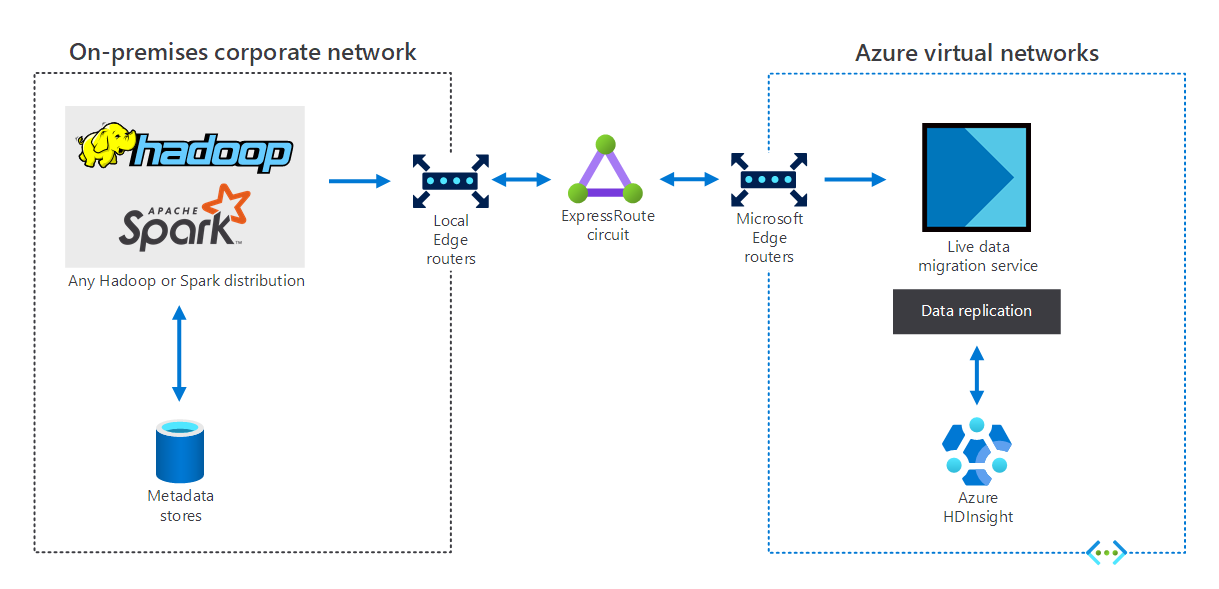
Organizations that have an on-premises, big-data infrastructure can use HDInsight to extend into Azure. This provides you with the benefits of the Azure cloud's advanced analytics capabilities. The following diagram depicts the hybrid scenario, in which:
- The on-premises big-data infrastructure consists of metadata stores and a Hadoop or Spark distribution on local VMs.
- An Azure ExpressRoute circuit connects the on-premises corporate network environment to Azure virtual networks.
- A live data migrator for Azure replicates the data received from on-premises to HDInsight.