Make applications scalable
Now that you understand the basics of preparing for growth, and are aware of factors to consider in capacity planning, you can take up the challenge of making your applications as scalable as possible.
Architectural reviews
A key point to remember is that you should perform regular architectural reviews of your systems.
You know that you can apply practices such as infrastructure as code to improve how you deploy your cloud resources. You update and improve your application code regularly, and you should do the same with your underlying platform resources.
Performing an architectural review helps you to identify the areas that need improvement.
The Azure Architecture Center has a wealth of resources to help you architect your applications in the cloud, and there are many scalability recommendations you can find in the application architecture guide at the following link:
Scenario: Tailwind Traders architecture
A first step is to do an evaluation of the architecture and application – not only to determine where its weaknesses lie, but also to recognize its strengths. What’s good about it?
Take another look at the scenario you saw in the previous unit. Here’s a diagram of the organization’s architecture again.
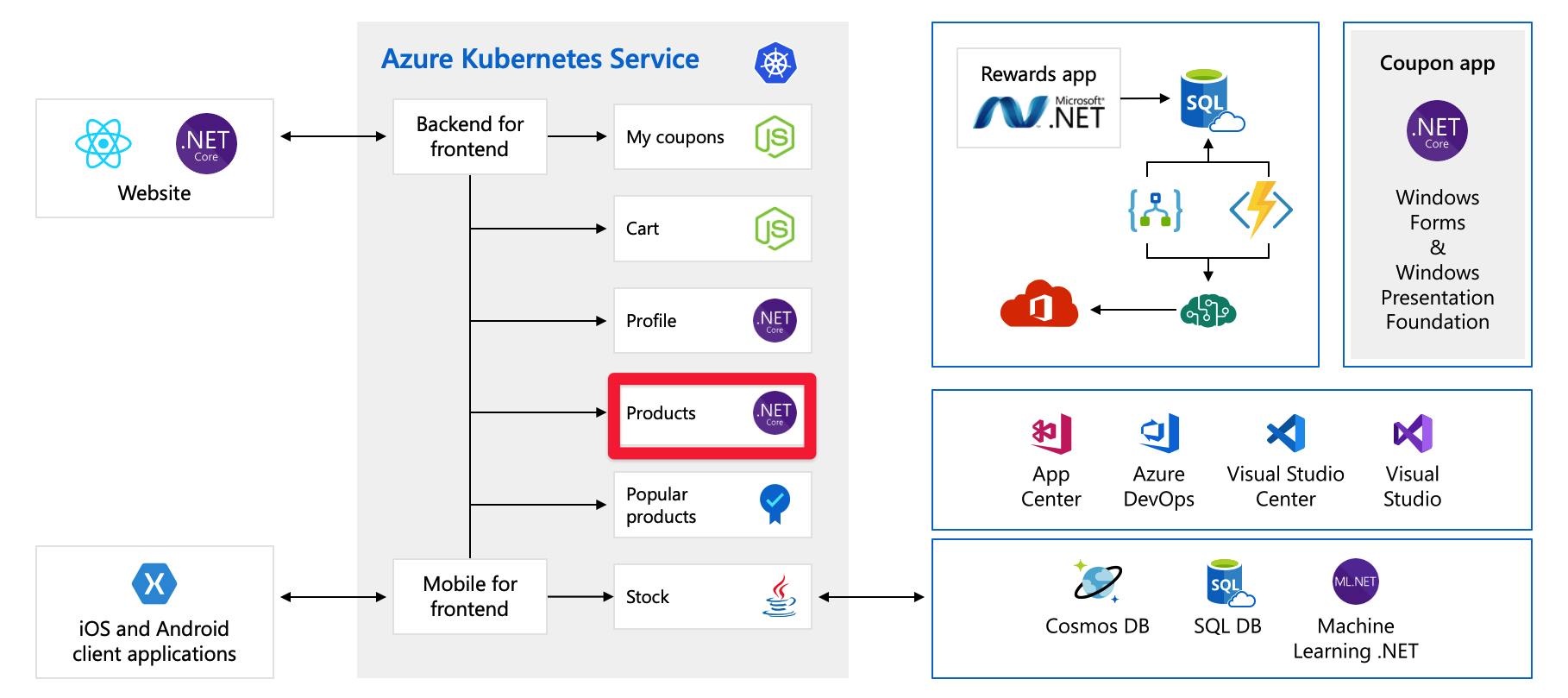
They've decomposed the application into smaller microservices, and some of these services are sitting as containers on Azure Kubernetes Service or they could be running on VMs or App Service. You’re using some inherently scalable services such as Functions and Logic Apps.
This change is good, but there are some improvements that would make the application more scalable. As an example, focus now on the Products service. In the diagram, the product service is running in Kubernetes, but we assume for this explanation that it's running on a VM in Azure. The scaling concepts, possibly with a slightly different implementation, can be applied to applications whether they're running on servers, App Service, or in containers.
The product currently runs on a single VM, connected to a single Azure SQL database. You need to enable this VM to scale out. You can do this using Azure virtual machine scale sets, which let you create and manage a group of identical, load balanced VMs. Because you now have more than one VM, you need to introduce a load balancer to distribute traffic across the VMs.
Virtual machine scale sets
By applying virtual machine scale sets over single VMs, you get a few benefits:
- You can autoscale based on host metrics, in-guest metrics, application insights, or by a schedule.
- You can use Availability Zones (AZ), which are independent standalone datacenters within an Azure region. With AZ support, you can spread your VMs across multiple AZs, which make your application more reliable and protect it from datacenter failures. New instances within a scale set are automatically evenly distributed across AZs.
- Adding a load balancer becomes easier. Virtual machine scale sets support the use of Azure Load Balancer for basic Layer 4 traffic distribution. They also support Azure Application Gateway for more advanced L7 traffic distribution and SSL termination.
There are some important factors you need to consider before implementing scale sets. Specifically:
- Avoid instance stickiness, so that no client is stuck to a specific back end.
- Remove persistent data from the VM, and store it somewhere else, such as in Azure Storage, or in a database.
- Design for scale-in. It’s also important that your application can easily scale back down. It has to gracefully handle not only having more instances added to the pool of servers handling the traffic, but also the abrupt termination of instances as the load drops. The scale down aspect of scaling is often overlooked.
Decoupling
You have added more VMs with scale sets. Scaling out is the typical answer to "we need to scale." But, you can only scale on a single metric, and this answer might not be relevant to all tasks performed by your product service.
In our scenario, the products service has a job. It takes a product image and after that image is uploaded. It transcodes that image, and stores it in several different sizes for thumbnails, pictures in the catalog, and so forth. The image-processing is CPU intensive, but the general usage is memory intensive.
Image-processing is an asynchronous task that can be broken into a background job. You can do that by decoupling your image-processing service using a queue. Decoupling allows you to scale both services independently – one on memory (the product service), and the other (the image-processing service) on CPU or even queue length, and have another scale set consume those messages and process the images.
Scale with queues
Azure has two types of queue offerings:
- Azure Service Bus queues A more advanced queueing offering, which is part of the broader Azure Service Bus product, offering pub/sub and more advanced integration patterns.
- Azure Storage Queues A simple REST-based queue interface built on top of Azure Storage. It offers reliable, persistent messaging.
Your requirements in this scenario are simple, so you can use Azure Storage Queues. Your product tier doesn’t have to scale at all because you’ve decoupled this background task.
In-memory caching
Another way to improve the performance of your application is to implement an in-memory cache.
Now you know that performance doesn't equal scalability exactly, but by improving the performance of your application, you can reduce the load on other resources. This improvement means you may not have to scale as soon.
Azure Cache for Redis is a managed Redis offering. Redis can be used for many patterns and use cases. For your product service in this scenario, you would likely implement the cache-aside pattern. In this pattern, you load items from the database into the cache as needed, making your application more performant, and reducing the load on the database.
Redis can also be used as a messaging queue for caching web content or for user session caching. This type of caching may be more suitable for other services in the system such as the shopping cart service, where you could store shopping cart data per session in Redis instead of using a cookie.
Scale the database
Now that you’ve made your compute resources more scalable, take a look at your database. In this scenario, you’re using Azure SQL database, which is a managed SQL server offering from Azure.
Relational databases are more difficult to scale out than nonrelational databases. The first thing you might do to scale your database is to scale up the size of the database. This resizing can be done easily with an average downtime of under four seconds. Either by using a simple API call in Azure SQL, or by using a slider in the portal.
If this sizing up doesn’t meet your requirements, depending on traffic characteristics, it may be suitable to scale out the reads to the database. Enabling you to route read traffic to your Read Replica.
Note
With Azure SQL, if you’re using the Premium or Business Critical tiers, Read Scale Out is enabled by default. It cannot be enabled on basic or standard tiers.
This change must be implemented in code. Here’s how to do that.
#Azure SQL Connection String
#Master Connection String
ApplicationIntent=ReadWrite
#Read Replica Connection String
ApplicationIntent=ReadOnly
#Full Example
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Update the ApplicationIntent attribute in your database connection string to specify to which server you want to connect. Use ReadOnly if you want to connect to the replica, or ReadWrite if you want to connect to the master.
Because this command must be implemented in code, it may not be a suitable solution for your situation. What if every single product service needs the ability to read and write?
In that case, you can look at scaling out SQL DB by using sharding.
Database sharding
If after scaling up or implementing Read Replicas, your database resources still don’t meet the needs of your system, the next option is sharding.
Sharding is a technique to distribute large amounts of identically structured data across many independent databases. Sharding may be required for many reasons. For example:
- The total amount of data is too large to fit within the constraints of an individual database.
- The transaction throughput of the overall workload exceeds the capabilities of an individual database.
- Separate tenants need to reside on different physical databases for compliance reasons (this requirement is less about scaling, but is another situation in which sharding is used).
Your application adds the relevant data to the relevant shard, and thus make your system scalable beyond the constraints of the individual database.
Azure SQL offers the Azure Elastic Database tools. These tools help you create, maintain, and query sharded SQL databases in Azure from your application logic.