How a KQL query is built
Now that you're familiar with how query languages work and where KQL can be used, let's explore the way a KQL query is built.
KQL query structure
A KQL query is a read-only request to process data and return results. The request is stated in plain text, using a data-flow model that's easy to read, author, and automate.
Different query languages often have different structures. KQL is organized based on the way that data is processed. Each KQL query begins with the data source. The data is then processed by passing through conditions, ordered, and reduced further with a filter.
Data processing
Imagine that the data travels through a data processing funnel. The tabular input is the beginning of the data funnel. This data is piped into the next line, and filtered or manipulated using an operator. The surviving data is piped into the subsequent line, and so on until arriving at the final query output. This query output is returned in a tabular format.
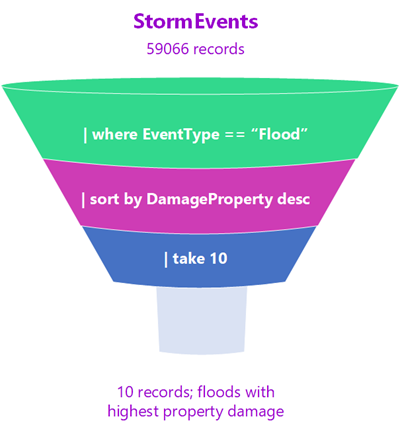
You can see by the shape of the filter that the data at the "top" of the funnel starts out larger than the size of the data at the end. Steps that remove the largest amounts of data are typically used at the beginning of the query. That way, the following operators have a smaller amount of data to process and the query result is returned quickly. In fact, one of the advantages of KQL is its ability to quickly process huge amounts of highly varied data.