Load data for exploration
Loading and exploring data are the first steps in any data science project. They involve understanding the data’s structure, content, and source, which are crucial for subsequent analysis.
After connecting to a data source, you can save the data into a Microsoft Fabric lakehouse. You can use the lakehouse as a central location to store any structured, semi-structured, and unstructured files. You can then easily connect to the lakehouse whenever you want to access your data for exploration or transformation.
Load data using notebooks
Notebooks in Microsoft Fabric facilitate the process of handling your data assets. Once your data assets are located in the lakehouse, you can easily generate code within the notebook to ingest these assets.
Consider a scenario where a data engineer has already transformed customer data and stored it in the lakehouse. A data scientist can easily load the data using notebooks for further exploration to build a machine learning model. This enables work to start immediately, whether that involves additional data manipulations, exploratory data analysis, or model development.
Let's create a sample parquet file to illustrate the load operation. The following PySpark code creates a dataframe of customer data and writes it to a Parquet file in the lakehouse.
Apache Parquet is an open-source, column-oriented data storage format. It’s designed for efficient data storage and retrieval, and is known for its high performance and compatibility with many data processing frameworks.
from pyspark.sql import Row
Customer = Row("firstName", "lastName", "email", "loyaltyPoints")
customer_1 = Customer('John', 'Smith', 'john.smith@contoso.com', 15)
customer_2 = Customer('Anna', 'Miller', 'anna.miller@contoso.com', 65)
customer_3 = Customer('Sam', 'Walters', 'sam@contoso.com', 6)
customer_4 = Customer('Mark', 'Duffy', 'mark@contoso.com', 78)
customers = [customer_1, customer_2, customer_3, customer_4]
df = spark.createDataFrame(customers)
df.write.parquet("<path>/customers")
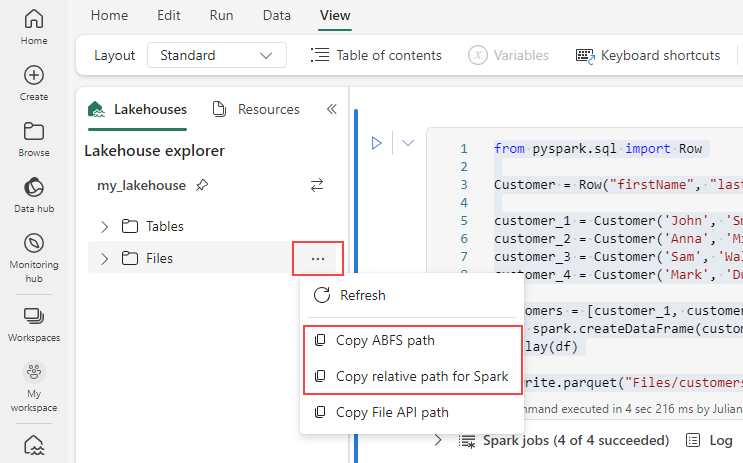
To generate the path for your Parquet file, select the ellipsis in the lakehouse explorer, and then choose either Copy ABFS path or Copy relative path for Spark. If writing Python code, you can use either the Copy File API or Copy ABFS path option.
The following code loads the parquet file into a DataFrame.
df = spark.read.parquet("<path>/customers")
display(df)
Alternatively, you can also generate the code to load the data in the notebook automatically. Choose the data file, then select Load data. After that, you’ll need to choose the API you wish to use.
While the parquet file in the previous example is stored in the lakehouse, it's also possible to load data from external sources like Azure Blob Storage.
account_name = "<account_name>"
container_name = "<container_name>"
relative_path = "<relative_path>"
sas_token = "<sas_token>"
wasbs = f'wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}?{blob_sas_token}'
df = spark.read.parquet(wasbs)
df.show()
You can follow similar steps to load other file types like .csv, .json, and .txt files. Just replace the .parquet method with the appropriate method for your file type, for example:
# For CSV files
df_csv = spark.read.csv('<path>')
# For JSON files
df_json = spark.read.json('<path>')
# For text files
df_text = spark.read.text('<path>')
Tip
Learn more about how to ingest and orchestrate data from various sources with Microsoft Fabric.