Assess the performance of your generative AI apps
When you want to create a generative AI app, you use prompt flow to develop the chat application. You can evaluate the performance of an app by evaluating the responses after running your flow.
Test your flow with individual prompts
During active development, you can test the chat flow you're creating by using the chat feature when you have a compute session running:

When you test your flow with an individual prompt in the chat window, your flow runs with your provided input. After it successfully runs, a response is shown in the chat window. You can also explore the output of each individual node of your flow to understand how the final response was constructed:

Automatically test your flow with evaluation flows
To evaluate a chat flow in bulk, you can run automated evaluations. You can either use the built-in automated evaluations, or you can define your custom evaluations by creating your own evaluation flow.
Evaluate with Microsoft-curated metrics
The built-in or Microsoft-curated metrics include the following metrics:
Performance and quality:
- Coherence: Measures how well the generative AI application can produce output that flows smoothly, reads naturally, and resembles human-like language.
- Fluency: Measure the language proficiency of a generative AI application's predicted answer.
- GPT similarity: Measures the similarity between a source data (ground truth) sentence and the generated response by a generative AI application.
- F1 score: Measures the ratio of the number of words between the generative AI application prediction and the source data (ground truth).
- Groundedness: Measures how well the generative AI application's generated answers align with information from the input source.
- Relevance: Measures the extent to which the generative AI application's generated responses are pertinent and directly related to the given questions.
Risk and safety:
- Self-harm-related content: Measures the disposition of the generative AI application toward producing self-harm-related content.
- Hateful and unfair content: Measures the predisposition of the generative AI application toward producing hateful and unfair content.
- Violent content: Measures the predisposition of the generative AI application toward producing violent content.
- Sexual content: Measures the predisposition of the generative AI application toward producing sexual content.

To evaluate your chat flow with the built-in automated evaluations, you need to:
- Create a test dataset.
- Create a new automated evaluation in the Azure AI Foundry portal.
- Select a flow or a dataset with model generated outputs.
- Select the metrics you want to evaluate on.
- Run the evaluation flow.
- Review the results.

Tip
Learn more about evaluation and monitoring metrics
Create custom evaluation metrics
Alternatively, you can create your own custom evaluation flow, in which you define how your chat flow's output should be evaluated. For example, you can evaluate the output using Python code or by using a Large Language Model (LLM) node to create an AI-assisted metric. Let's explore how an evaluation flow works with a simple example.
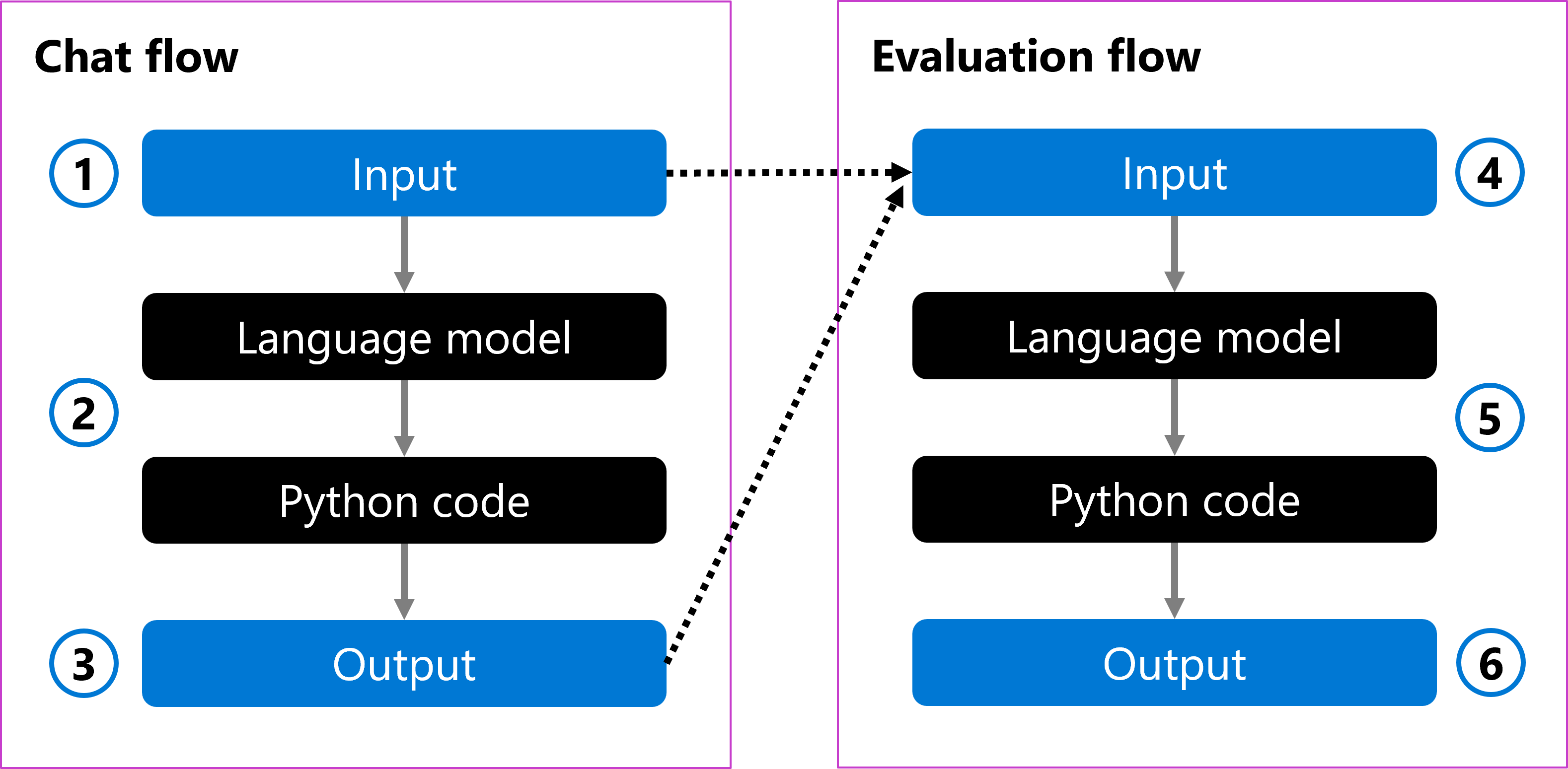
You can have a chat flow that takes a user's question as input (1). The flow processes the input using a language model and formats the answer with Python code (2). Finally, it returns the response as output (3).
To evaluate the chat flow, you can create an evaluation flow. The evaluation flow takes the original user question and the generated output as input (4). The flow evaluates it with a language model and uses Python code to define an evaluation metric (5), which is then returned as output (6).
When you create an evaluation flow, you can choose how to evaluate a chat flow. You can use a language model to create your own custom AI-assisted metrics. In the prompt, you can define the metric you want to measure and the grading scale the language model should use. For example, an evaluation prompt can be:
# Instructions
You are provided with the input and response of a language model that you need to evaluate on user satisfaction.
User satisfaction is defined as whether the response meets the user’s question and needs, and provides a comprehensive and appropriate answer to the question.
Assign each response a score of 1 to 5 for user satisfaction, with 5 being the highest score.
After creating an evaluation flow, you can evaluate a chat flow by providing a test dataset and running the evaluation flow.

When you use a language model in an evaluation flow, you can review the results in the output trace:

Additionally, you can add a Python node in the evaluation flow to aggregate the results for all prompts in your test dataset and return an overall metric.
Tip
Learn how to develop an evaluation flow in the Azure AI Foundry portal.