Get and prepare data
Data is the foundation of machine learning. Both data quantity and data quality affect the model’s accuracy.
To train a machine learning model, you need to:
- Identify data source and format.
- Choose how to serve data.
- Design a data ingestion solution.
To get and prepare the data you use to train the machine learning model, you need to extract data from a source and make it available to the Azure service you want to use to train models or make predictions.
Identify data source and format
First, you need to identify your data source and its current data format.
| Identify the | Examples |
|---|---|
| Data source | For example, the data can be stored in a Customer Relationship Management (CRM) system, in a transactional database like an SQL database, or be generated by an Internet of Things (IoT) device. |
| Data format | You need to understand the current format of the data, which can be tabular or structured data, semi-structured data or unstructured data. |
Then, you need to decide what data you need to train your model, and in what format you want that data to be served to the model.
Choose how to serve data
To access data when training machine learning models, you want to serve the data by storing it in a cloud data service. By storing data separately from your compute, you minimize costs and are more flexible. It’s a best practice to store your data in one tool, which is separate from another tool you use to train your models.
Which tool or service is best to store your data depends on the data you have and the service you use for model training. Some commonly used options on Azure are:
- Azure Blob Storage: Cheapest option for storing data as unstructured data. Ideal for storing files like images, text, and JSON. Often also used to store data as CSV files, as data scientists prefer working with CSV files.
- Azure Data Lake Storage (Gen 2): A more advanced version of the Azure Blob Storage. Also stores files like CSV files and images as unstructured data. A data lake also implements a hierarchical namespace, which means it’s easier to give someone access to a specific file or folder. Storage capacity is virtually limitless so ideal for storing large data.
- Azure SQL Database: Stores data as structured data. Data is read as a table and schema is defined when a table in the database is created. Ideal for data that doesn’t change over time.
Design a data ingestion solution
In general, it’s a best practice to extract data from its source before analyzing it. Whether you’re using the data for data engineering, data analysis, or data science, you want to extract the data from its source, transform it, and load it into a serving layer. Such a process is also referred to as Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT). The serving layer makes your data available for the service you use for further data processing like training machine learning models.
To move and transform data, you can use a data ingestion pipeline. A data ingestion pipeline is a sequence of tasks that move and transform the data. By creating a pipeline, you can choose to trigger the tasks manually or schedule the pipeline when you want the tasks to be automated. Such pipelines can be created with Azure services like Azure Synapse Analytics, Azure Databricks, and also Azure Machine Learning.
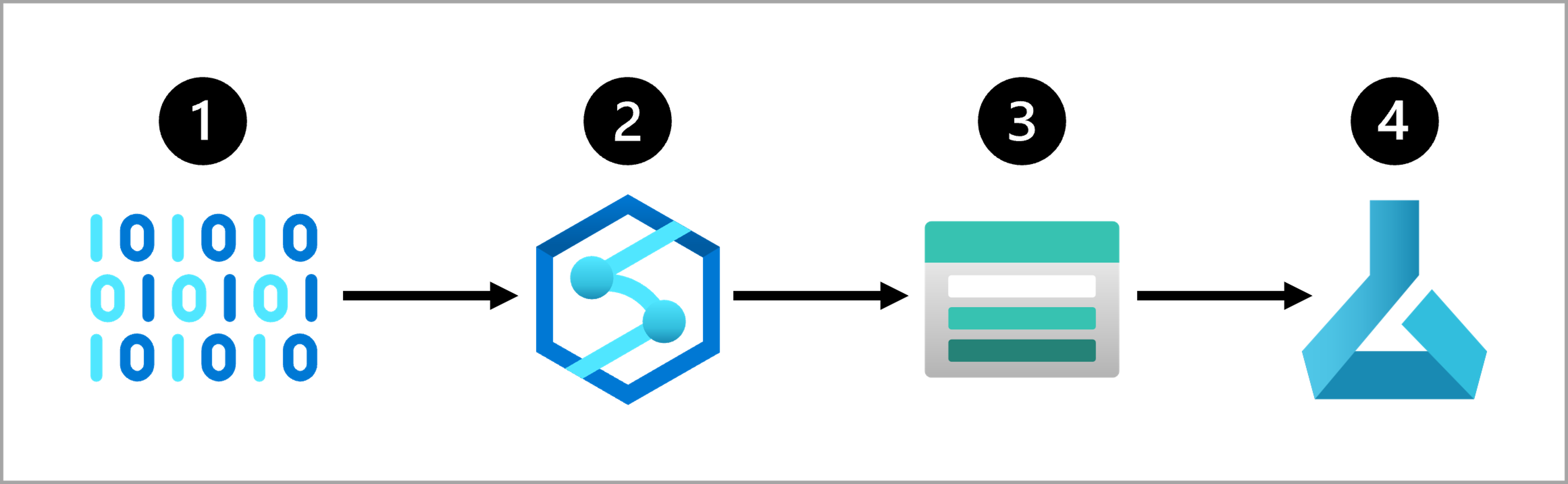
A common approach for a data ingestion solution is to:
- Extract raw data from its source (like a CRM system or IoT device).
- Copy and transform the data with Azure Synapse Analytics.
- Store the prepared data in an Azure Blob Storage.
- Train the model with Azure Machine Learning.
Explore an example
Imagine you want to train a weather forecasting model. You prefer one table in which all temperature measurements of each minute are combined. You want to create aggregates of the data and have a table of the average temperature per hour. To create the table, you want to transform the semi-structured data ingested from the IoT device that measures temperature at intervals, to tabular data.
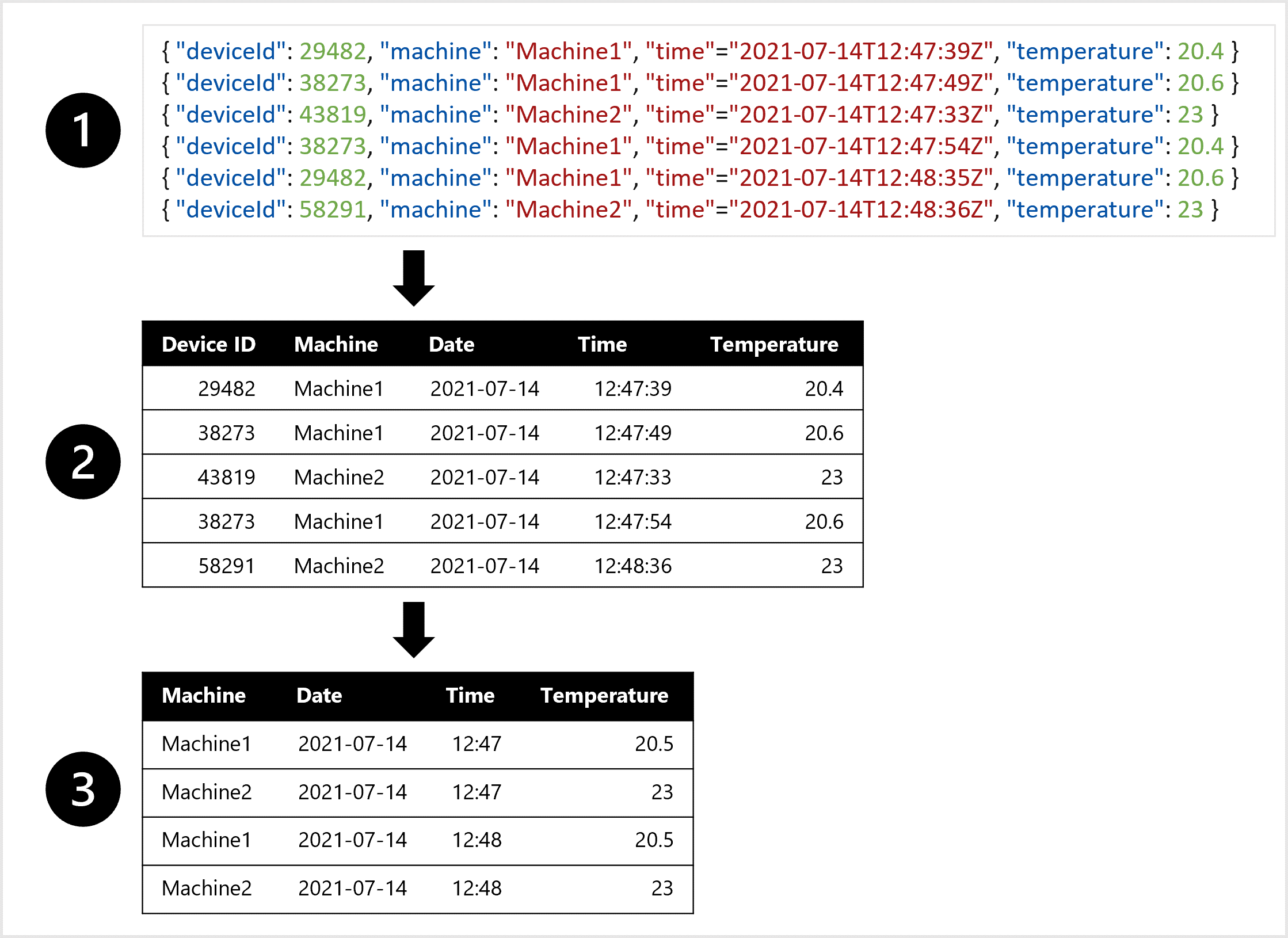
For example, to create a dataset you can use to train the forecasting model, you can:
- Extract data measurements as JSON objects from the IoT devices.
- Convert the JSON objects to a table.
- Transform the data to get the temperature per machine per minute.