Identify your data source and format
Data is the most important input for your machine learning models. You’ll need access to data when training machine learning models, and the trained model needs data as input to generate predictions.
Imagine you're a data scientist and have been asked to train a machine learning model.
You aim to go through the following six steps to plan, train, deploy, and monitor the model:

- Define the problem: Decide on what the model should predict and when it's successful.
- Get the data: Find data sources and get access.
- Prepare the data: Explore the data. Clean and transform the data based on the model's requirements.
- Train the model: Choose an algorithm and hyperparameter values based on trial and error.
- Integrate the model: Deploy the model to an endpoint to generate predictions.
- Monitor the model: Track the model's performance.
Note
The diagram is a simplified representation of the machine learning process. Typically, the process is iterative and continuous. For example, when monitoring the model you may decide to go back and retrain the model.
To get and prepare the data you'll use to train the machine learning model, you'll need to extract data from a source and make it available to the Azure service you want to use to train models or make predictions.
In general, it’s a best practice to extract data from its source before analyzing it. Whether you’re using the data for data engineering, data analysis, or data science, you’ll want to extract the data from its source, transform it, and load it into a serving layer. Such a process is also referred to as Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT). The serving layer makes your data available for the service you’ll use for further data processing like training machine learning models.
Before being able to design the ETL or ELT process, you’ll need to identify your data source and data format.
Identify the data source
When you start with a new machine learning project, first identify where the data you want to use is stored.
The necessary data for your machine learning model may already be stored in a database or be generated by an application. For example, the data may be stored in a Customer Relationship Management (CRM) system, in a transactional database like an SQL database, or be generated by an Internet of Things (IoT) device.
In other words, your organization may already have business processes in place, which generate and store the data. If you don’t have access to the data you need, there are alternative methods. You can collect new data by implementing a new process, acquire new data by using publicly available datasets, or buy curated datasets.
Identify the data format
Based on the source of your data, your data may be stored in a specific format. You need to understand the current format of the data and determine the format required for your machine learning workloads.
Commonly, we refer to three different formats:
Tabular or structured data: All data has the same fields or properties, which are defined in a schema. Tabular data is often represented in one or more tables where columns represent features and rows represent data points. For example, an Excel or CSV file can be interpreted as tabular data:
Patient ID Pregnancies Diastolic Blood Pressure BMI Diabetes Pedigree Age Diabetic 1354778 0 80 43.50973 1.213191 21 0 1147438 8 93 21.24058 0.158365 23 1 Semi-structured data: Not all data has the same fields or properties. Instead, each data point is represented by a collection of key-value pairs. The keys represent the features, and the values represent the properties for the individual data point. For example, real-time applications like Internet of Things (IoT) devices generate a JSON object:
{ "deviceId": 29482, "location": "Office1", "time":"2021-07-14T12:47:39Z", "temperature": 23 }Unstructured data: Files that don't adhere to any rules when it comes to structure. For example, documents, images, audio, and video files are considered unstructured data. Storing them as unstructured files ensures you don’t have to define any schema or structure, but also means you can't query the data in the database. You'll need to specify how to read such a file when consuming the data.
Tip
Learn more about core data concepts on Learn
Identify the desired data format
When extracting the data from a source, you may want to transform the data to change the data format and make it more suitable for model training.
For example, you may want to train a forecasting model to perform predictive maintenance on a machine. You want to use features such as the machine's temperature to predict a problem with the machine. If you get an alert that a problem is arising, before the machine breaks down, you can save costs by fixing the problem early on.
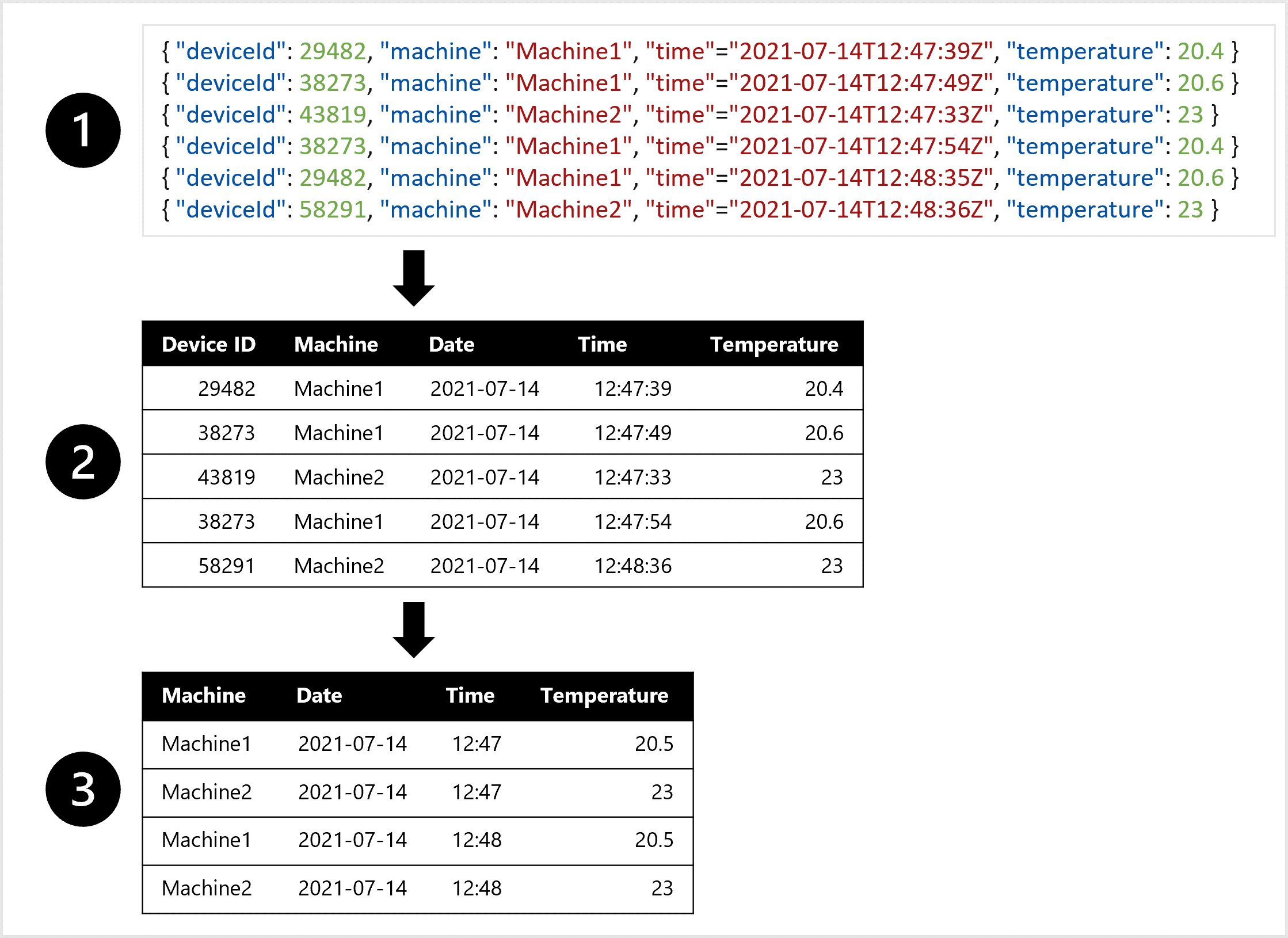
Imagine the machine has a sensor that measures the temperature every minute. Each minute, every measurement or entry can be stored as a JSON object or file.
To train the forecasting model, you may prefer one table in which all temperature measurements of each minute are combined. You may want to create aggregates of the data and have a table of the average temperature per hour. To create the table, you'll want to transform the semi-structured data ingested from the IoT device to tabular data.
To create a dataset you can use to train the forecasting model, you may:
- Extract data measurements as JSON objects from the IoT devices.
- Convert the JSON objects to a table.
- Transform the data to get the temperature per machine per minute.
Once you’ve identified the data source, the original data format, and the desired data format, you can think about how you want to serve the data. Then, you can design a data ingestion pipeline to automatically extract and transform the data you need.