Explain PaaS options for deploying SQL Server in Azure
Platform as a Service (PaaS) provides a complete development and deployment environment in the cloud, which can be used for simple cloud-based applications as well as for advanced enterprise applications.
Azure SQL Database and Azure SQL Managed Instance are part of PaaS offering for Azure SQL.
Azure SQL Database – Part of a family of products built upon the SQL Server engine, in the cloud. It gives developers a great deal of flexibility in building new application services, and granular deployment options at scale. SQL Database offers a low maintenance solution that can be a great option for certain workloads.
Azure SQL Managed Instance– It is best for most migration scenarios to the cloud as it provides fully managed services and capabilities.
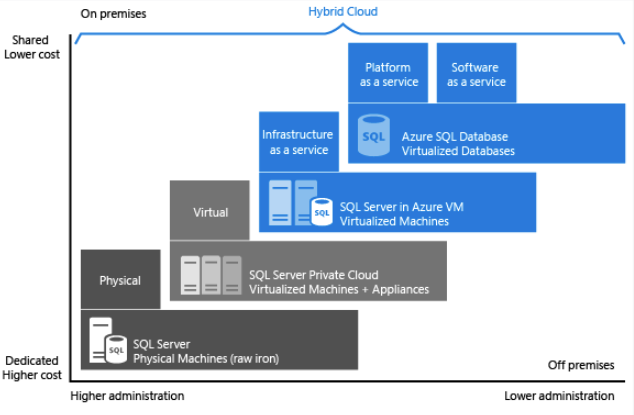
As seen in the image above, each offering provides a certain level of administration you have over the infrastructure, by the degree of cost efficiency.
Deployment models
Azure SQL Database is available in two different deployment models:
Single database – a single database that is billed and managed on a per database level. You manage each of your databases individually from scale and data size perspectives. Each database deployed in this model has its own dedicated resources, even if deployed to the same logical server.
Elastic Pools – a group of databases that are managed together and share a common set of resources. Elastic pools provide a cost-effective solution for software as a service application model, since resources are shared between all databases. You can configure resources based either on the DTU-based purchasing model or the vCore-based purchasing model.
Purchasing model
In Azure, all services are backed by physical hardware, and you can choose from two different purchasing models:
Database Transaction Unit (DTU)
DTUs are calculated based on a formula combining compute, storage, and I/O resources. It is a good choice for customers who want simple, preconfigured resource options.
The DTU purchasing model comes in several different service tiers, such as Basic, Standard and Premium. Each tier has varying capabilities, which provide a wide range of options when choosing this platform.
In terms of performance, the Basic tier is used for less demanding workloads, while Premium is used for intensive workload requirements.
Compute and storage resources are dependent on the DTU level, and they provide a range of performance capabilities at a fixed storage limit, backup retention, and cost.
Note
DTU purchasing model is only supported by Azure SQL Database.
For more information about DTU purchasing model, see DTU-based purchasing model overview.
vCore
The vCore model allows you to purchase a specified number of vCores based on your given workloads. vCore is the default purchasing model when purchasing Azure SQL Database resources. vCore databases have a specific relationship between the number of cores and the amount of memory and storage provided to the database. vCore purchasing model is supported by either Azure SQL Database and Azure SQL Managed Instance.
You can purchase vCore databases in three different service tiers as well:
General Purpose – This tier is for general purpose workloads. It is backed by Azure premium storage. It will have higher latency than Business Critical. It also provides the following compute tiers:
- Provisioned – Compute resources are pre-allocated. Billed per hour based on vCores configured.
- Serverless – Compute resources are auto-scaled. Billed per second based on vCores used.
Business Critical – This tier is for high performing workloads offering the lowest latency of either service tier. This tier is backed by local SSDs instead of Azure blob storage. It also offers the highest resilience to failure as well as providing a built-in read-only database replica that can be used to off-load reporting workloads.
Hyperscale – Hyperscale databases can scale far beyond the 4 TB limit the other Azure SQL Database offerings and have a unique architecture that supports databases of up to 100 TB.
Serverless
The name “Serverless” can be a bit confusing as you still deploy your Azure SQL Database to a logical server, to which you connect. Azure SQL Database serverless is a compute tier that will automatically scale up or down the resources for a given database based on workload demand. If the workload no longer requires compute resources, the database will become “paused” and only storage is billed during the period the database is inactive. When a connection attempt is made, the database will “resume” and become available.
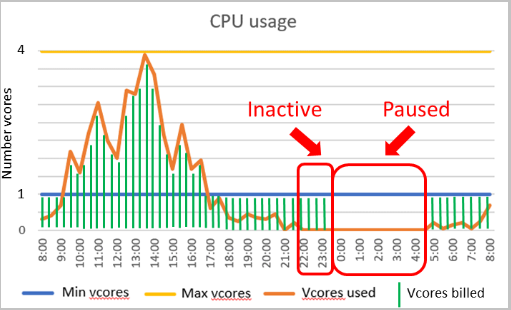
The setting to control pausing is referred to as the autopause delay and has a minimum value of 60 minutes and a maximum value of seven days. If the database has been idle for that period of time, it will then pause.
Once the database has been inactive for the specified amount of time, it will be paused until a subsequent connection is attempted. Configuring a compute autoscaling range and an auto-pause delay affect database performance and compute costs.
Any applications using serverless should be configured to handle connection errors and include retry logic, as connecting to a paused database will generate a connection error.
Another difference between serverless and the normal vCore model of Azure SQL Database is that with serverless you can specify a minimum and maximum number of vCores. Memory and I/O limits are proportional to the range that is specified.
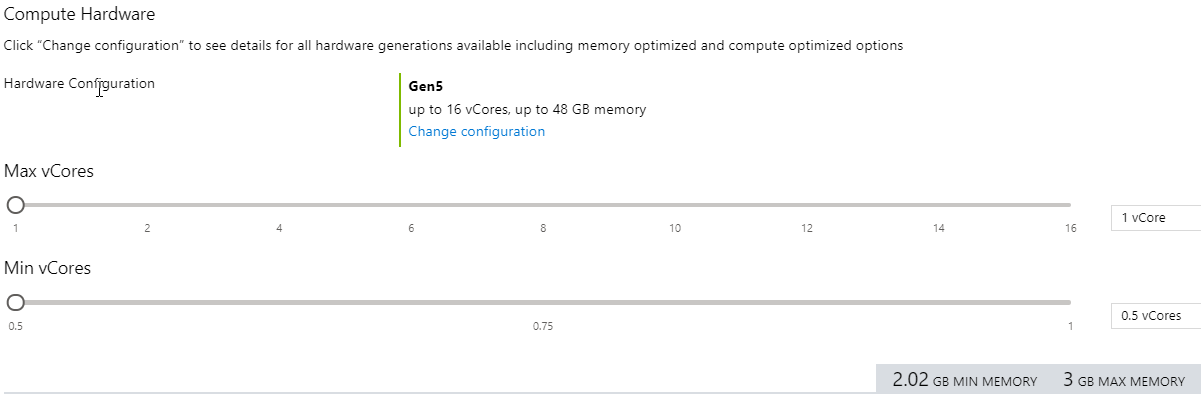
The image above shows the configuration screen for a serverless database in the Azure portal. You have the option to select a minimum as low as half of a vCore and a maximum as high as 16 vCores.
Serverless is not fully compatible with all the features in Azure SQL Database since some of them require background processes to run at all times, such as:
- Geo-replication
- Long-term backup retention
- A job database in elastic jobs
- The sync database in SQL Data Sync (Data Sync is a service that replicates data between a group of databases)
Note
SQL Database serverless is currently only supported in the General Purpose tier in the vCore purchasing model.
Backups
One of the most important features of the Platform as a Service offering is backups. In this case, backups are performed automatically without any intervention from you. Backups are stored in Azure blob geo-redundant storage and by default are retained for between 7 and 35 days, based on the service tier of the database. Basic and vCore databases default to seven days of retention, and on the vCore databases this value can be adjusted by the administrator. The retention time can be extended by configuring long-term retention (LTR), which would allow you to retain backups for up to 10 years.
In order to provide redundancy, you are also able to use read-accessible geo-redundant blob storage. This storage would replicate your database backups to a secondary region of your preference. It would also allow you to read from that secondary region if needed. Manual backups of databases are not supported, and the platform will deny any request to do so.
Database Backups are taken on a given schedule:
- Full – Once a week
- Differential – Every 12 hours
- Log – Every 5-10 minutes depending on transaction log activity
This backup schedule should meet the needs of most recovery point/time objectives (RPO/RTO), however, each customer should evaluate whether they meet your business requirements.
There are several options available for restoring a database. Due to the nature of Platform as a Service, you cannot manually restore a database using conventional methods, such as issuing the T-SQL command RESTORE DATABASE.
Regardless of which restore method is implemented, it is not possible to restore over an existing database. If a database needs to be restored, the existing database must be dropped or renamed prior to initiating the restore process. Furthermore, keep in mind that depending on the platform service tier, restore times are not guaranteed and could fluctuate. It is recommended that you test the restore process to obtain a baseline metric on how long a restore could potentially take.
The available restore options are:
Restore using the Azure portal – Using the Azure portal you have the option of restoring a database to the same Azure SQL Database server, or you can use the restore to create a new database on a new server in any Azure region.
Restore using scripting Languages – Both PowerShell and Azure CLI can be utilized in order to restore a database.
Note
Copy-only backup to Azure blob storage is available for SQL Managed Instance. SQL Database does not support this feature.
For more information about automated backups, see Automated backups - Azure SQL Database & Azure SQL Managed Instance.
Active geo-replication
Geo-replication is a business continuity feature that asynchronously replicates a database to up to four secondary replicas. As transactions are committed to the primary (and its replicas within the same region), the transactions are sent to the secondaries to be replayed. Because this communication is done asynchronously, the calling application does not have to wait for the secondary replica to commit the transaction prior to SQL Server returning control to the caller.
The secondary databases are readable and can be used to offload read-only workloads, thus freeing up resources for transactional workloads on the primary or placing data closer to your end users. Furthermore, the secondary databases can be in the same region as the primary or in another Azure region.
With geo-replication you can initiate a failover either manually by the user or from the application. If a failover occurs, you potentially will need to update the application connection strings to reflect the new endpoint of what is now the primary database.
Failover groups
Failover groups are built on top of the technology used in geo-replication, but provide a single endpoint for connection. The major reason for using failover groups is that the technology provides endpoints, which can be utilized to route traffic to the appropriate replica. Your application can then connect after a failover without connection string changes.