Invoke and troubleshoot batch endpoints
When you invoke a batch endpoint, you trigger an Azure Machine Learning pipeline job. The job will expect an input parameter pointing to the data set you want to score.
Trigger the batch scoring job
To prepare data for batch predictions, you can register a folder as a data asset in the Azure Machine Learning workspace.
You can then use the registered data asset as input when invoking the batch endpoint with the Python SDK:
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes
input = Input(type=AssetTypes.URI_FOLDER, path="azureml:new-data:1")
job = ml_client.batch_endpoints.invoke(
endpoint_name=endpoint.name,
input=input)
You can monitor the run of the pipeline job in the Azure Machine Learning studio. All jobs that are triggered by invoking the batch endpoint will show in the Jobs tab of the batch endpoint.
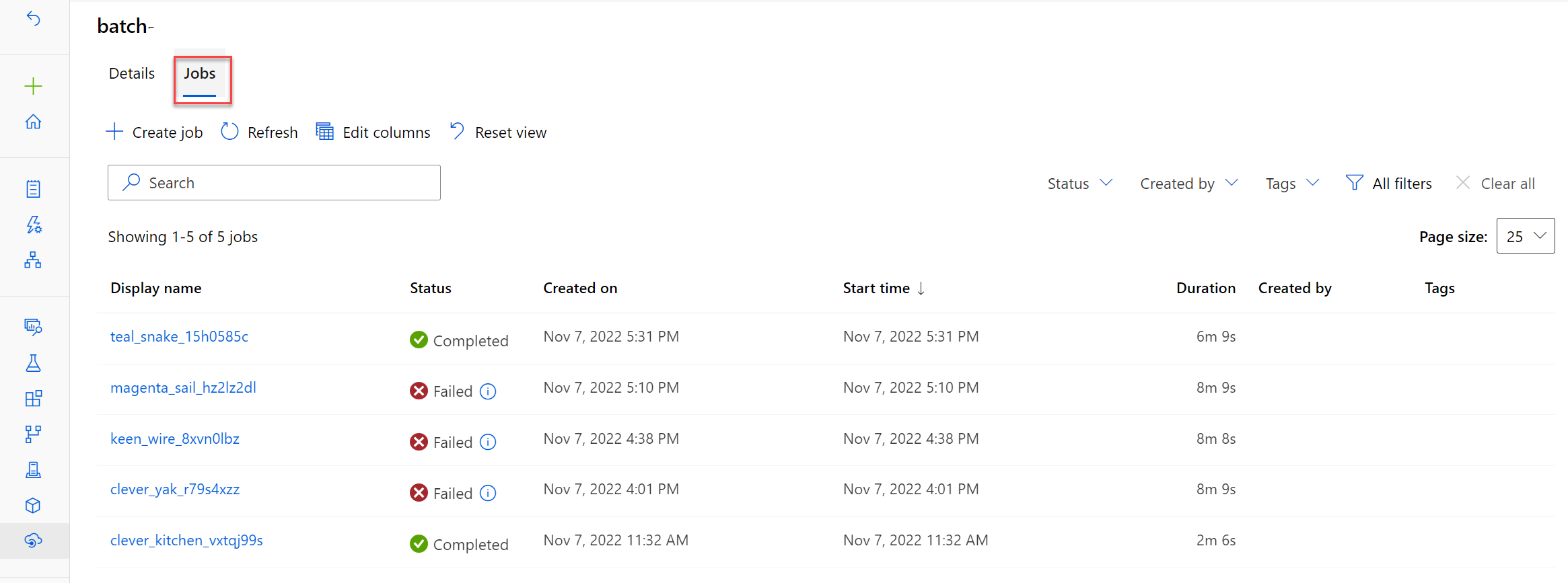
The predictions will be stored in the default datastore.
Troubleshoot a batch scoring job
The batch scoring job runs as a pipeline job. If you want to troubleshoot the pipeline job, you can review its details and the outputs and logs of the pipeline job itself.
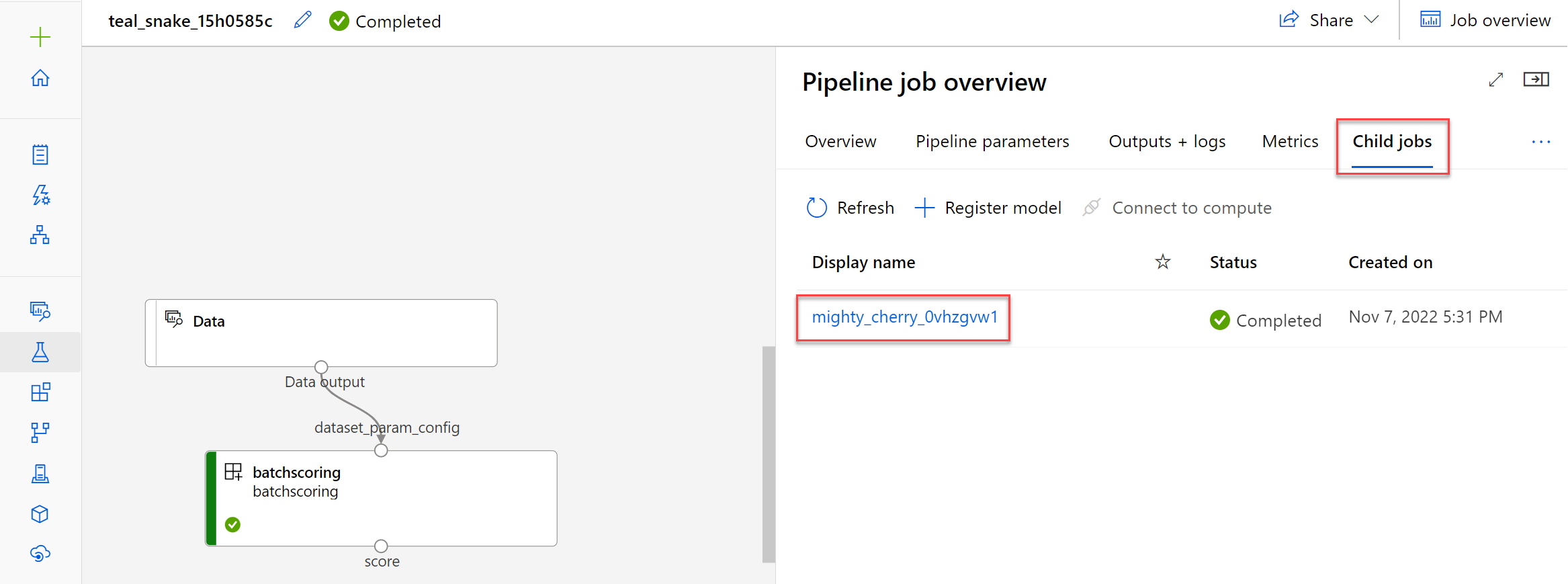
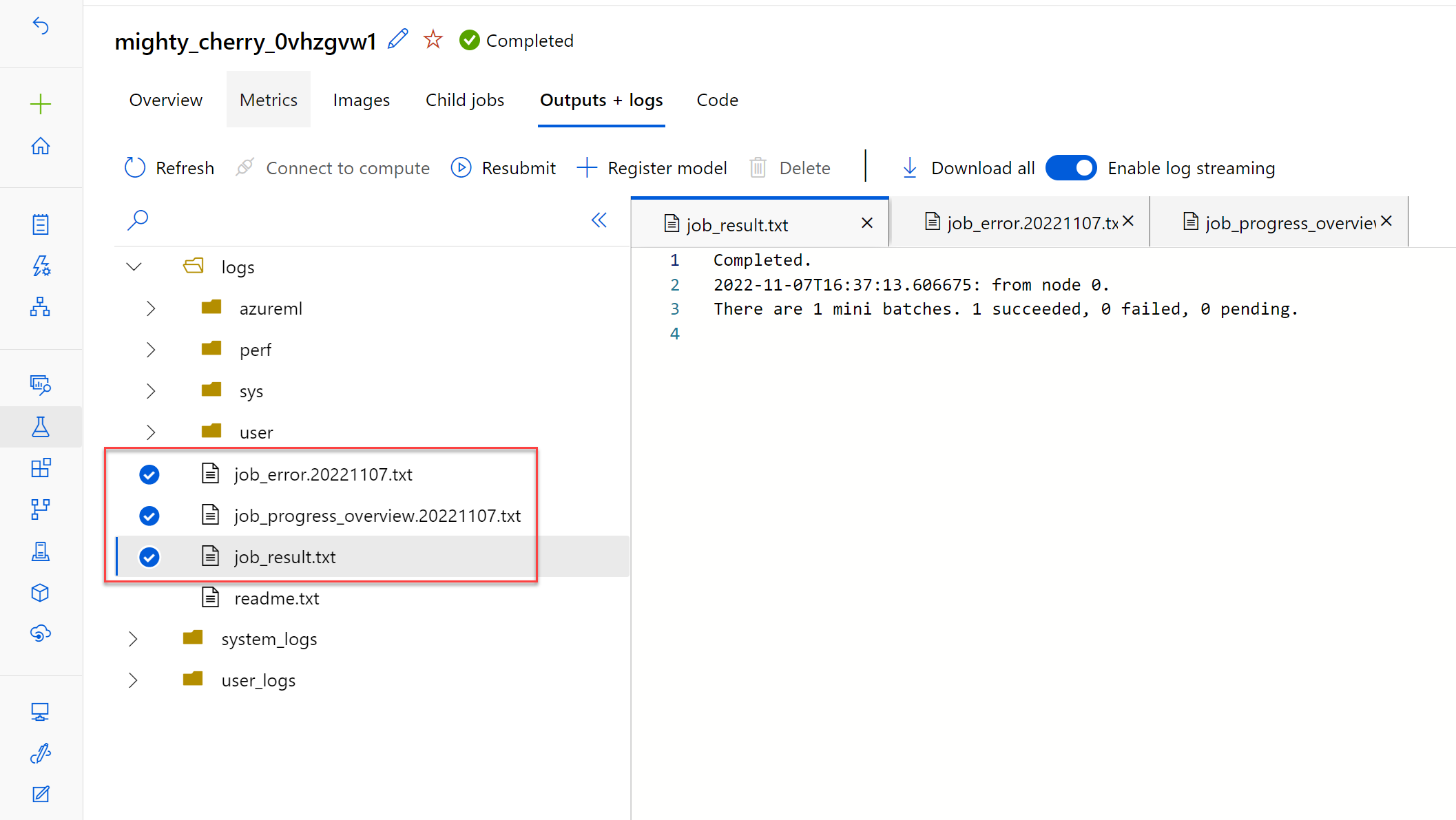
If you want to troubleshoot the scoring script, you can select the child job and review its outputs and logs.
Navigate to the Outputs + logs tab. The logs/user/ folder contains three files that will help you troubleshoot:
job_error.txt: Summarize the errors in your script.job_progress_overview.txt: Provides high-level information about the number of mini-batches processed so far.job_result.txt: Shows errors in calling theinit()andrun()function in the scoring script.