Configure multiple nodes and enable scale-to-zero by using AKS
Azure Kubernetes Service allows you to create different node pools to match specific workloads to the nodes running in each node pool. The process of matching workloads to nodes lets you plan to compute consumption and optimize cost.
Your company's drone-tracking solution is deployed on Azure Kubernetes Service (AKS) as many containerized applications and services. Your team developed a new predictive-modeling service that processes flight-path information in extreme weather conditions and creates optimal flight routes. This service requires GPU-based virtual-machine (VM) support and runs only on specific days during the week.
You want to configure a cluster node pool dedicated to processing flight-path information. The process runs for only a couple of hours a day, and you want to use a GPU-based node pool. However, you want to pay for the nodes only when you use them.
Let's look at how node pools and how AKS uses nodes, then at how to scale the node count in a node pool.
What is a node pool?
A node pool describes a group of nodes with the same configuration in an AKS cluster. These nodes contain the underlying VMs that run your applications. You can create two types of node pools on an AKS-managed Kubernetes cluster:
System node pools
User node pools
System node pools
System node pools host critical system pods that make up your cluster's control plane. A system node pool allows the use of Linux only as the node OS and runs only Linux-based workloads. Nodes in a system node pool are reserved for system workloads and normally not used to run custom workloads. Every AKS cluster must contain at least one system node pool with at least one node, and you must define the underlying VM sizes for nodes.
User node pools
User node pools support your workloads, and you can specify Windows or Linux as the node operating system. You can also define the underlying VM sizes for nodes and run specific workloads. For example, your drone-tracking solution has a batch-processing service that you deploy to a node pool with a configuration for general-purpose VMs. The new predictive-modeling service requires higher-capacity, GPU-based VMs. You decide to configure a separate node pool and configure it to use GPU-enabled nodes.
Number of nodes in a node pool
You can configure up to 100 nodes in a node pool. However, the number of nodes you choose to configure depends on the number of pods that run per node.
For example, in a system node pool, it's essential to set the maximum number of pods that run on a single node to 30. This value guarantees that enough space is available to run the system pods critical to cluster health. When the number of pods exceeds this minimum value, new nodes are required in the pool to schedule extra workloads. For this reason, a system node pool needs at least one node in the pool. For production environments, the recommended node count for a system node pool is a minimum of three nodes.
User node pools are designed to run custom workloads and don't have the 30-pod requirement. User node pools allow you to set the node count for a pool to zero.
Manage application demand in an AKS cluster
In AKS, when you increase or decrease the amount of compute resources in a Kubernetes cluster, you're scaling. You can scale either the number of workload instances that need to run or the number of nodes on which these workloads run. You can scale workloads on an AKS-managed cluster in one of two ways. The first option is to scale the pods or nodes manually as necessary. The second option is through automation, where you can use the horizontal pod autoscaler to scale pods and the cluster autoscaler to scale nodes.
How to scale a node pool manually
If you're running workloads that execute for a specific duration at specific known intervals, manually scaling the node pool size is a good way to control node costs.
Assume that the predictive-modeling service requires a GPU-based node pool and runs for an hour every day at noon. You can configure the node pool with specific GPU-based nodes and scale the node pool to zero nodes when you're not using the cluster.
Here's an example of the az aks node pool add command that you can use to create the node pool. Notice the --node-vm-size parameter, which specifies the Standard_NC6 GPU-based VM size for the nodes in the pool.
az aks nodepool add \
--resource-group resourceGroup \
--cluster-name aksCluster \
--name gpunodepool \
--node-count 1 \
--node-vm-size Standard_NC6 \
--no-wait
When the pool is ready, you can use the az aks nodepool scale command to scale the node pool to zero nodes. Notice that the --node-count parameter is set to zero. Here's an example of the command:
az aks nodepool scale \
--resource-group resourceGroup \
--cluster-name aksCluster \
--name gpunodepool \
--node-count 0
How to scale a cluster automatically
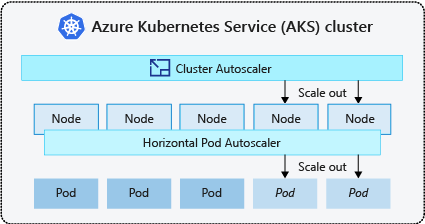
AKS uses the Kubernetes cluster autoscaler to automatically scale workloads. The cluster can scale by using two options:
The horizontal pod autoscaler
The cluster autoscaler
Let's look at each option, starting with the horizontal pod autoscaler.
Horizontal pod autoscaler
Use the Kubernetes horizontal pod autoscaler to monitor the resource demand on a cluster and automatically scale the number of workload replicas.
The Kubernetes Metrics Server collects memory and processor metrics from controllers, nodes, and containers that run on the AKS cluster. One way to access this information is to use the Metrics API. The horizontal pod autoscaler checks the Metrics API every 30 seconds to decide whether your application needs more instances to meet the required demand.
Assume your company also has a batch-processing service that schedules drone flight paths. You notice that the service gets inundated with requests and builds up a backlog of deliveries, causing delays and frustrations for customers. Increasing the number of batch-processing service replicas could enable the timely processing of orders.
To solve the problem, you configure the horizontal pod autoscaler to increase the number of service replicas when needed. When the number of batch requests decrease, it decreases the number of service replicas.
However, the horizontal pod autoscaler scales pods only on available nodes in the configured node pools of the cluster.
Cluster autoscaler
A resource constraint is triggered when the horizontal pod autoscaler can't schedule another pod on the existing nodes in a node pool. You need to use the cluster autoscaler to scale the number of nodes in a cluster's node pools in times of constraints. The cluster autoscaler checks the defined metrics and scales the number of nodes up or down based on the computing resources required.
The cluster autoscaler is used alongside the horizontal pod autoscaler.
The cluster autoscaler monitors for both scale-up and scale-down events, and allows the Kubernetes cluster to change the node count in a node pool as resource demands change.
You configure each node pool with different scale rules. For example, you might want to configure only one node pool to allow autoscaling, or you might configure a node pool to scale only to a specific number of nodes.
Important
You lose the ability to scale the node count to zero when you enable the cluster autoscaler on a node pool. Instead, you can set the min count to zero to save on cluster resources.