Cluster scalability concepts
Node starvation
In the spec.containers.resources key of a pod YAML file, you define the number of resources the pod requires. After you create a new pod within a node, Kubernetes automatically allocates that specified number of resources to the pod so it runs with the amount of power it needs.
A single node is a single virtual machine (VM) that has a limited amount of resources available for pods, like CPU and RAM. You can't spin up an infinite number of pods in a node. When a node doesn't meet the needed requirements for the pod's resource, the pod competes with the specified resources for the node's resources, which leads to node starvation. The pod remains in a Pending status and isn't scheduled to any nodes until enough resources are available.
Cluster scalability
To avoid node starvation, the operator needs to scale out the cluster and add more VMs to the node pool. You can perform manual cluster scaling using the Azure CLI az aks scale command. You can also use the Azure portal to manually scale your cluster. Sign in to the portal and select your Azure Kubernetes Service (AKS) cluster. Under Settings, select Node pools. Select the node pool you want to scale, and then select Scale node pool.
Manual scaling can be overwhelming, especially for clusters with inconsistent and fluctuating demand. When the number of pods consistently fluctuates, you need to constantly monitor it for unscheduled pods and make any necessary tweaks in real time.
Cluster autoscaler
In AKS, the cluster autoscaler tool automates the cluster scaling process. When you enable it on your AKS cluster, it watches for unscheduled pods with resource constraints and automatically increases the number of nodes to meet the requirements.
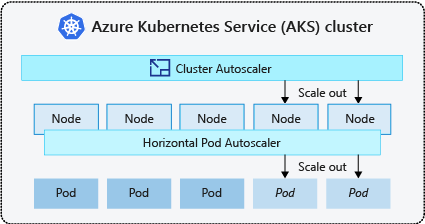
The cluster autoscaler can also decrease the number of nodes in a cluster if there's unused cluster capacity for a specified amount of time. When this condition is met, the autoscaler cordons (makes the node unavailable for the scheduling of new workloads) and drains (moves the existent workloads to other node) the node. As a result, all the pods that are scheduled in that node are safely moved to other nodes. It also ensures that no other pods are scheduled during the process. Then, it removes the node from the pool.
There are some situations where the cluster autoscaler can't remove a node due to pods that can't be moved out of that node. These situations include:
- A pod is directly created with a YAML file and isn't bound to any controllers, such as Deployments or ReplicaSets.
- The Pod Disruption Budget (PDB) is too restrictive and doesn't allow for the number of pods to fall below a certain threshold.
- The pod has a node selector for that particular node or a node affinity that prevents it from going somewhere else.
When autoscaling is enabled, manual cluster scaling is disabled.