Preparing hard drives for an Import Job
The WAImportExport tool is the drive preparation and repair tool that you can use with the Microsoft Azure Import/Export service. You can use this tool to copy data to the hard drives you are going to ship to an Azure datacenter. After an import job has completed, you can use this tool to repair any blobs that were corrupted, were missing, or conflicted with other blobs. After you receive the drives from a completed export job, you can use this tool to repair any files that were corrupted or missing on the drives. In this article, we go over the use of this tool.
Prerequisites
Requirements for WAImportExport.exe
- Machine configuration
- Windows 7, Windows Server 2008 R2, or a newer Windows operating system
- .NET Framework 4 must be installed. See FAQ on how to check if .NET Framework is installed on the machine.
- Storage account key - You need at least one of the account keys for the storage account.
Preparing disk for import job
- BitLocker - BitLocker must be enabled on the machine running the WAImportExport tool. See the FAQ for how to enable BitLocker.
- Disks accessible from machine on which WAImportExport Tool is run. See FAQ for disk specification.
- Source files - The files you plan to import must be accessible from the copy machine, whether they are on a network share or a local hard drive.
Repairing a partially failed import job
- Copy log file that is generated when Azure Import/Export service copies data between Storage Account and Disk. It is located in your target storage account.
Repairing a partially failed export job
- Copy log file that is generated when Azure Import/Export service copies data between Storage Account and Disk. It is located in your source storage account.
- Manifest file - [Optional] Located on exported drive that was returned by Microsoft.
Download and install WAImportExport
Download the latest version of WAImportExport.exe. Extract the zipped content to a directory on your computer.
Your next task is to create CSV files.
Prepare the dataset CSV file
What is dataset CSV
Dataset CSV file is the value of /dataset flag is a CSV file that contains a list of directories and/or a list of files to be copied to target drives. The first step to creating an import job is to determine which directories and files you are going to import. This can be a list of directories, a list of unique files, or a combination of those two. When a directory is included, all files in the directory and its subdirectories will be part of the import job.
For each directory or file to be imported, you must identify a destination virtual directory or blob in the Azure Blob service. You will use these targets as inputs to the WAImportExport tool. Directories should be delimited with the forward slash character "/".
The following table shows some examples of blob targets:
| Source file or directory | Destination blob or virtual directory |
|---|---|
| H:\Video | https://mystorageaccount.blob.core.windows.net/video |
| H:\Photo | https://mystorageaccount.blob.core.windows.net/photo |
| K:\Temp\FavoriteVideo.ISO | https://mystorageaccount.blob.core.windows.net/favorite/FavoriteVideo.ISO |
| \myshare\john\music | https://mystorageaccount.blob.core.windows.net/music |
Sample dataset.csv
BasePath,DstBlobPathOrPrefix,BlobType,Disposition,MetadataFile,PropertiesFile
"F:\50M_original\100M_1.csv.txt","containername/100M_1.csv.txt",BlockBlob,rename,"None",None
"F:\50M_original\","containername/",BlockBlob,rename,"None",None
Dataset CSV file fields
| Field | Description |
|---|---|
| BasePath | [Required] The value of this parameter represents the source where the data to be imported is located. The tool will recursively copy all data located under this path. Allowed Values: This has to be a valid path on local computer or a valid share path and should be accessible by the user. The directory path must be an absolute path (not a relative path). If the path ends with "\", it represents a directory else a path ending without "\" represents a file. No regex is allowed in this field. If the path contains spaces, put it in "". Example: "c:\Directory\c\Directory\File.txt" "\\FBaseFilesharePath.domain.net\sharename\directory" |
| DstBlobPathOrPrefix | [Required] The path to the destination virtual directory in your Windows Azure storage account. The virtual directory may or may not already exist. If it does not exist, Import/Export service will create one. Be sure to use valid container names when specifying destination virtual directories or blobs. Keep in mind that container names must be lowercase. For container naming rules, see Naming and Referencing Containers, Blobs, and Metadata. If only root is specified, the directory structure of the source is replicated in the destination blob container. If a different directory structure is desired than the one in source, multiple rows of mapping in CSV You can specify a container, or a blob prefix like music/70s/. The destination directory must begin with the container name, followed by a forward slash "/", and optionally may include a virtual blob directory that ends with "/". When the destination container is the root container, you must explicitly specify the root container, including the forward slash, as $root/. Since blobs under the root container cannot include "/" in their names, any subdirectories in the source directory will not be copied when the destination directory is the root container. Example If the destination blob path is https://mystorageaccount.blob.core.windows.net/video, the value of this field can be video/ |
| BlobType | [Optional] block | page Currently Import/Export service supports 2 kinds of Blobs. Page blobs and Block BlobsBy default all files will be imported as Block Blobs. And *.vhd and *.vhdx will be imported as Page BlobsThere is a limit on the block-blob and page-blob allowed size. See Storage scalability targets for more information. |
| Disposition | [Optional] rename | no-overwrite | overwrite This field specifies the copy-behavior during import i.e when data is being uploaded to the storage account from the disk. Available options are: rename|overwrite|no-overwrite.Defaults to "rename" if nothing specified. Rename: If an object with same name is present, creates a copy in destination. Overwrite: overwrites the file with newer file. The file with last-modified wins. No-overwrite: Skips writing the file if already present. |
| MetadataFile | [Optional] The value to this field is the metadata file which can be provided if the one needs to preserve the metadata of the objects or provide custom metadata. Path to the metadata file for the destination blobs. See Import/Export service Metadata and Properties File Format for more information |
| PropertiesFile | [Optional] Path to the property file for the destination blobs. See Import/Export service Metadata and Properties File Format for more information. |
Prepare InitialDriveSet or AdditionalDriveSet CSV file
What is driveset CSV
The value of the /InitialDriveSet or /AdditionalDriveSet flag is a CSV file that contains the list of disks to which the drive letters are mapped so that the tool can correctly pick the list of disks to be prepared. If the data size is greater than a single disk size, the WAImportExport tool will distribute the data across multiple disks enlisted in this CSV file in an optimized way.
There is no limit on the number of disks the data can be written to in a single session. The tool will distribute data based on disk size and folder size. It will select the disk that is most optimized for the object-size. The data when uploaded to the storage account will be converged back to the directory structure that was specified in dataset file. In order to create a driveset CSV, follow the steps below.
Create basic volume and assign drive letter
In order to create a basic volume and assign a drive letter, by following the instructions for "Simpler partition creation" given at Overview of Disk Management.
Sample InitialDriveSet and AdditionalDriveSet CSV file
DriveLetter,FormatOption,SilentOrPromptOnFormat,Encryption,ExistingBitLockerKey
G,AlreadyFormatted,SilentMode,AlreadyEncrypted,060456-014509-132033-080300-252615-584177-672089-411631
H,Format,SilentMode,Encrypt,
Driveset CSV file fields
| Fields | Value |
|---|---|
| DriveLetter | [Required] Each drive that is being provided to the tool as the destination needs have a simple NTFS volume on it and a drive letter assigned to it. Example: R or r |
| FormatOption | [Required] Format | AlreadyFormatted Format: Specifying this will format all the data on the disk. AlreadyFormatted: The tool will skip formatting when this value is specified. |
| SilentOrPromptOnFormat | [Required] SilentMode | PromptOnFormat SilentMode: Providing this value will enable user to run the tool in Silent Mode. PromptOnFormat: The tool will prompt the user to confirm whether the action is really intended at every format. If not set, command will abort and display error message: "Incorrect value for SilentOrPromptOnFormat: none" |
| Encryption | [Required] Encrypt | AlreadyEncrypted The value of this field decides which disk to encrypt and which not to. Encrypt: Tool will format the drive. If value of "FormatOption" field is "Format" then this value is required to be "Encrypt". If "AlreadyEncrypted" is specified in this case, it will result into an error "When Format is specified, Encrypt must also be specified". AlreadyEncrypted: Tool will decrypt the drive using the BitLockerKey provided in "ExistingBitLockerKey" Field. If value of "FormatOption" field is "AlreadyFormatted", then this value can be either "Encrypt" or "AlreadyEncrypted" |
| ExistingBitLockerKey | [Required] If value of "Encryption" field is "AlreadyEncrypted" The value of this field is the BitLocker key that is associated with the particular disk. This field should be left blank if the value of "Encryption" field is "Encrypt". If BitLocker Key is specified in this case, it will result into an error "BitLocker Key should not be specified". Example: 060456-014509-132033-080300-252615-584177-672089-411631 |
Preparing disk for import job
To prepare drives for an import job, call the WAImportExport tool with the PrepImport command. Which parameters you include depends on whether this is the first copy session, or a subsequent copy session.
First session
First Copy Session to Copy a Single/Multiple Directory to a single/multiple Disk (depending on what is specified in CSV file) WAImportExport tool PrepImport command for the first copy session to copy directories and/or files with a new copy session:
WAImportExport.exe PrepImport /j:<JournalFile> /id:<SessionId> [/logdir:<LogDirectory>] [/sk:<StorageAccountKey>] [/silentmode] [/InitialDriveSet:<driveset.csv>] /DataSet:<dataset.csv>
Example:
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#1 /sk:\*\*\*\*\*\*\*\*\*\*\*\*\* /InitialDriveSet:driveset-1.csv /DataSet:dataset-1.csv /logdir:F:\logs
Add data in subsequent session
In subsequent copy sessions, you do not need to specify the initial parameters. You need to use the same journal file in order for the tool to remember where it left in the previous session. The state of the copy session is written to the journal file. Here is the syntax for a subsequent copy session to copy additional directories and or files:
WAImportExport.exe PrepImport /j:<SameJournalFile> /id:<DifferentSessionId> [DataSet:<differentdataset.csv>]
Example:
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#2 /DataSet:dataset-2.csv
Add drives to latest session
If the data did not fit in specified drives in InitialDriveset, one can use the tool to add additional drives to same copy session.
Note
The session id should match the previous session id. Journal file should match the one specified in previous session.
WAImportExport.exe PrepImport /j:<SameJournalFile> /id:<SameSessionId> /AdditionalDriveSet:<newdriveset.csv>
Example:
WAImportExport.exe PrepImport /j:SameJournalTest.jrn /id:session#2 /AdditionalDriveSet:driveset-2.csv
Abort the latest session:
If a copy session is interrupted and it is not possible to resume (for example, if a source directory proved inaccessible), you must abort the current session so that it can be rolled back and new copy sessions can be started:
WAImportExport.exe PrepImport /j:<SameJournalFile> /id:<SameSessionId> /AbortSession
Example:
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#2 /AbortSession
Only the last copy session, if terminated abnormally, can be aborted. Note that you cannot abort the first copy session for a drive. Instead you must restart the copy session with a new journal file.
Resume a latest interrupted session
If a copy session is interrupted for any reason, you can resume it by running the tool with only the journal file specified:
WAImportExport.exe PrepImport /j:<SameJournalFile> /id:<SameSessionId> /ResumeSession
Example:
WAImportExport.exe PrepImport /j:JournalTest.jrn /id:session#2 /ResumeSession
Important
When you resume a copy session, do not modify the source data files and directories by adding or removing files.
WAImportExport parameters
| Parameters | Description |
|---|---|
| /j:<JournalFile> | Required Path to the journal file. A journal file tracks a set of drives and records the progress in preparing these drives. The journal file must always be specified. |
| /logdir:<LogDirectory> | Optional. The log directory. Verbose log files as well as some temporary files will be written to this directory. If not specified, current directory will be used as the log directory. The log directory can be specified only once for the same journal file. |
| /id:<SessionId> | Required The session Id is used to identify a copy session. It is used to ensure accurate recovery of an interrupted copy session. |
| /ResumeSession | Optional. If the last copy session was terminated abnormally, this parameter can be specified to resume the session. |
| /AbortSession | Optional. If the last copy session was terminated abnormally, this parameter can be specified to abort the session. |
| /sn:<StorageAccountName> | Required Only applicable for RepairImport and RepairExport. The name of the storage account. |
| /sk:<StorageAccountKey> | Required The key of the storage account. |
| /InitialDriveSet:<driveset.csv> | Required When running the first copy session A CSV file that contains a list of drives to prepare. |
| /AdditionalDriveSet:<driveset.csv> | Required. When adding drives to current copy session. A CSV file that contains a list of additional drives to be added. |
| /r:<RepairFile> | Required Only applicable for RepairImport and RepairExport. Path to the file for tracking repair progress. Each drive must have one and only one repair file. |
| /d:<TargetDirectories> | Required. Only applicable for RepairImport and RepairExport. For RepairImport, one or more semicolon-separated directories to repair; For RepairExport, one directory to repair, e.g. root directory of the drive. |
| /CopyLogFile:<DriveCopyLogFile> | Required Only applicable for RepairImport and RepairExport. Path to the drive copy log file (verbose or error). |
| /ManifestFile:<DriveManifestFile> | Required Only applicable for RepairExport. Path to the drive manifest file. |
| /PathMapFile:<DrivePathMapFile> | Optional. Only applicable for RepairImport. Path to the file containing mappings of file paths relative to the drive root to locations of actual files (tab-delimited). When first specified, it will be populated with file paths with empty targets, which means either they are not found in TargetDirectories, access denied, with invalid name, or they exist in multiple directories. The path map file can be manually edited to include the correct target paths and specified again for the tool to resolve the file paths correctly. |
| /ExportBlobListFile:<ExportBlobListFile> | Required. Only applicable for PreviewExport. Path to the XML file containing list of blob paths or blob path prefixes for the blobs to be exported. The file format is the same as the blob list blob format in the Put Job operation of the Import/Export service REST API. |
| /DriveSize:<DriveSize> | Required. Only applicable for PreviewExport. Size of drives to be used for export. For example, 500 GB, 1.5 TB. Note: 1 GB = 1,000,000,000 bytes1 TB = 1,000,000,000,000 bytes |
| /DataSet:<dataset.csv> | Required A CSV file that contains a list of directories and/or a list of files to be copied to target drives. |
| /silentmode | Optional. If not specified, it will remind you the requirement of drives and need your confirmation to continue. |
Tool output
Sample drive manifest file
<?xml version="1.0" encoding="UTF-8"?>
<DriveManifest Version="2011-MM-DD">
<Drive>
<DriveId>drive-id</DriveId>
<StorageAccountKey>storage-account-key</StorageAccountKey>
<ClientCreator>client-creator</ClientCreator>
<!-- First Blob List -->
<BlobList Id="session#1-0">
<!-- Global properties and metadata that applies to all blobs -->
<MetadataPath Hash="md5-hash">global-metadata-file-path</MetadataPath>
<PropertiesPath Hash="md5-hash">global-properties-file-path</PropertiesPath>
<!-- First Blob -->
<Blob>
<BlobPath>blob-path-relative-to-account</BlobPath>
<FilePath>file-path-relative-to-transfer-disk</FilePath>
<ClientData>client-data</ClientData>
<Length>content-length</Length>
<ImportDisposition>import-disposition</ImportDisposition>
<!-- page-range-list-or-block-list -->
<!-- page-range-list -->
<PageRangeList>
<PageRange Offset="1073741824" Length="512" Hash="md5-hash" />
<PageRange Offset="1073741824" Length="512" Hash="md5-hash" />
</PageRangeList>
<!-- block-list -->
<BlockList>
<Block Offset="1073741824" Length="4194304" Id="block-id" Hash="md5-hash" />
<Block Offset="1073741824" Length="4194304" Id="block-id" Hash="md5-hash" />
</BlockList>
<MetadataPath Hash="md5-hash">metadata-file-path</MetadataPath>
<PropertiesPath Hash="md5-hash">properties-file-path</PropertiesPath>
</Blob>
</BlobList>
</Drive>
</DriveManifest>
Sample journal file (XML) for each drive
[BeginUpdateRecord][2016/11/01 21:22:25.379][Type:ActivityRecord]
ActivityId: DriveInfo
DriveState: [BeginValue]
<?xml version="1.0" encoding="UTF-8"?>
<Drive>
<DriveId>drive-id</DriveId>
<BitLockerKey>*******</BitLockerKey>
<ManifestFile>\DriveManifest.xml</ManifestFile>
<ManifestHash>D863FE44F861AE0DA4DCEAEEFFCCCE68</ManifestHash> </Drive>
[EndValue]
SaveCommandOutput: Completed
[EndUpdateRecord]
Sample journal file (JRN) for session that records the trail of sessions
[BeginUpdateRecord][2016/11/02 18:24:14.735][Type:NewJournalFile]
VocabularyVersion: 2013-02-01
[EndUpdateRecord]
[BeginUpdateRecord][2016/11/02 18:24:14.749][Type:ActivityRecord]
ActivityId: PrepImportDriveCommandContext
LogDirectory: F:\logs
[EndUpdateRecord]
[BeginUpdateRecord][2016/11/02 18:24:14.754][Type:ActivityRecord]
ActivityId: PrepImportDriveCommandContext
StorageAccountKey: *******
[EndUpdateRecord]
FAQ
General
What is WAImportExport tool?
The WAImportExport tool is the drive preparation and repair tool that you can use with the Microsoft Azure Import/Export service. You can use this tool to copy data to the hard drives you are going to ship to an Azure data center. After an import job has completed, you can use this tool to repair any blobs that were corrupted, were missing, or conflicted with other blobs. After you receive the drives from a completed export job, you can use this tool to repair any files that were corrupted or missing on the drives.
How does the WAImportExport tool work on multiple source dir and disks?
If the data size is greater than the disk size, the WAImportExport tool will distribute the data across the disks in an optimized way. The data copy to multiple disks can be done in parallel or sequentially. There is no limit on the number of disks the data can be written to simultaneously. The tool will distribute data based on disk size and folder size. It will select the disk that is most optimized for the object-size. The data when uploaded to the storage account will be converged back to the specified directory structure.
Where can I find previous version of WAImportExport tool?
WAImportExport tool has all functionalities that WAImportExport V1 tool had. WAImportExport tool allows users to specify multiple sources and write to multiple drives. Additionally, one can easily manage multiple source locations from which the data needs to be copied in a single CSV file. However, in case you need SAS support or want to copy single source to single disk, you can download WAImportExport V1 Tool and refer to WAImportExport V1 Reference for help with WAImportExport V1 usage.
What is a session ID?
The tool expects the copy session (/id) parameter to be the same if the intent is to spread the data across multiple disks. Maintaining the same name of the copy session will enable user to copy data from one or multiple source locations into one or multiple destination disks/directories. Maintaining same session id enables the tool to pick up the copy of files from where it was left the last time.
However, same copy session cannot be used to import data to different storage accounts.
When copy-session name is same across multiple runs of the tool, the logfile (/logdir) and storage account key (/sk) is also expected to be the same.
SessionId can consist of letters, 0~9, underscore (_), dash (-) or hash (#), and its length must be 3~30.
e.g. session-1 or session#1 or session_1
What is a journal file?
Each time you run the WAImportExport tool to copy files to the hard drive, the tool creates a copy session. The state of the copy session is written to the journal file. If a copy session is interrupted (for example, due to a system power loss), it can be resumed by running the tool again and specifying the journal file on the command line.
For each hard drive that you prepare with the Azure Import/Export Tool, the tool will create a single journal file with name "<DriveID>.xml" where drive Id is the serial number associated to the drive that the tool reads from the disk. You will need the journal files from all of your drives to create the import job. The journal file can also be used to resume drive preparation if the tool is interrupted.
What is a log directory?
The log directory specifies a directory to be used to store verbose logs as well as temporary manifest files. If not specified, the current directory will be used as the log directory. The logs are verbose logs.
Prerequisites
What are the specifications of my disk?
One or more empty 2.5-inch or 3.5-inch SATAII or III or SSD hard drives connected to the copy machine.
How can I enable BitLocker on my machine?
Simple way to check is by right-clicking on System drive. It will show you options for BitLocker if the capability is turned on. If it is off, you won't see it.
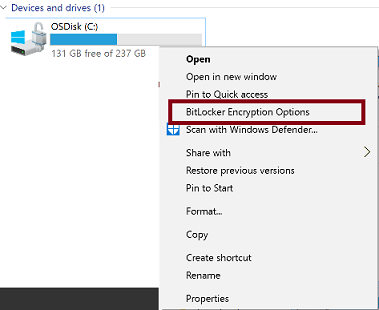
Here is an article on how to enable BitLocker
It is possible that your machine does not have TPM chip. If you do not get an output using tpm.msc, look at the next FAQ.
How to disable Trusted Platform Module (TPM) in BitLocker?
Note
Only if there is no TPM in their servers, you need to disable TPM policy. It is not necessary to disable TPM if there is a trusted TPM in user's server.
In order to disable TPM in BitLocker, go through the following steps:
- Launch Group Policy Editor by typing gpedit.msc on a command prompt. If Group Policy Editor appears to be unavailable, for enabling BitLocker first. See previous FAQ.
- Open Local Computer Policy > Computer Configuration > Administrative Templates > Windows Components> BitLocker Drive Encryption > Operating System Drives.
- Edit Require additional authentication at startup policy.
- Set the policy to Enabled and make sure Allow BitLocker without a compatible TPM is checked.
How to check if .NET 4 or higher version is installed on my machine?
All Microsoft .NET Framework versions are installed in following directory: %windir%\Microsoft.NET\Framework\
Navigate to the above mentioned part on your target machine where the tool needs to run. Look for folder name starting with "v4". Absence of such a directory means .NET 4 is not installed on your machine. You can download .NET 4 on your machine using Microsoft .NET Framework 4 (Web Installer).
Limits
How many drives can I prepare/send at the same time?
There is no limit on the number of disks that the tool can prepare. However, the tool expects drive letters as inputs. That limits it to 25 simultaneous disk preparation. A single job can handle maximum of 10 disks at a time. If you prepare more than 10 disks targeting the same storage account, the disks can be distributed across multiple jobs.
Can I target more than one storage account?
Only one storage account can be submitted per job and in single copy session.
Capabilities
Does WAImportExport.exe encrypt my data?
Yes. BitLocker encryption is enabled and required for this process.
What will be the hierarchy of my data when it appears in the storage account?
Although data is distributed across disks, the data when uploaded to the storage account will be converged back to the directory structure specified in the dataset CSV file.
How many of the input disks will have active IO in parallel, when copy is in progress?
The tool distributes data across the input disks based on the size of the input files. That said, the number of active disks in parallel completely depends on the nature of the input data. Depending on the size of individual files in the input dataset, one or more disks may show active IO in parallel. See next question for more details.
How does the tool distribute the files across the disks?
WAImportExport Tool reads and writes files batch by batch, one batch contains max of 100000 files. This means that max 100000 files can be written parallel. Multiple disks are written to simultaneously if these 100000 files are distributed to multi drives. However whether the tool writes to multiple disks simultaneously or a single disk depends on the cumulative size of the batch. For instance, in case of smaller files, if all of 10,0000 files are able to fit in a single drive, tool will write to only one disk during the processing of this batch.
WAImportExport output
There are two journal files, which one should I upload to Azure portal?
.xml - For each hard drive that you prepare with the WAImportExport tool, the tool will create a single journal file with name <DriveID>.xml where DriveID is the serial number associated to the drive that the tool reads from the disk. You will need the journal files from all of your drives to create the import job in the Azure portal. This journal file can also be used to resume drive preparation if the tool is interrupted.
.jrn - The journal file with suffix .jrn contains the status for all copy sessions for a hard drive. It also contains the information needed to create the import job. You must always specify a journal file when running the WAImportExport tool, as well as a copy session ID.
Next steps
- Setting Up the Azure Import/Export Tool
- Setting properties and metadata during the import process
- Sample workflow to prepare hard drives for an import job
- Quick reference for frequently used commands
- Reviewing job status with copy log files
- Repairing an import job
- Repairing an export job
- Troubleshooting the Azure Import/Export Tool