How to: Access mirrored Azure Cosmos DB data in Lakehouse and notebooks from Microsoft Fabric (Preview)
In this guide, you learn how to Access mirrored Azure Cosmos DB data in Lakehouse and notebooks from Microsoft Fabric (Preview).
Important
Mirroring for Azure Cosmos DB is currently in preview. Production workloads aren't supported during preview. Currently, only Azure Cosmos DB for NoSQL accounts are supported.
Prerequisites
- An existing Azure Cosmos DB for NoSQL account.
- If you don't have an Azure subscription, Try Azure Cosmos DB for NoSQL free.
- If you have an existing Azure subscription, create a new Azure Cosmos DB for NoSQL account.
- An existing Fabric capacity. If you don't have an existing capacity, start a Fabric trial.
- The Azure Cosmos DB for NoSQL account must be configured for Fabric mirroring. For more information, see account requirements.
Tip
During the public preview, it's recommended to use a test or development copy of your existing Azure Cosmos DB data that can be recovered quickly from a backup.
Setup mirroring and prerequisites
Configure mirroring for the Azure Cosmos DB for NoSQL database. If you're unsure how to configure mirroring, refer to the configure mirrored database tutorial.
Navigate to the Fabric portal.
Create a new connection and mirrored database using your Azure Cosmos DB account's credentials.
Wait for replication to finish the initial snapshot of data.
Access mirrored data in Lakehouse and notebooks
Use Lakehouse to further extend the number of tools you can use to analyze your Azure Cosmos DB for NoSQL mirrored data. Here, you use Lakehouse to build a Spark notebook to query your data.
Navigate to the Fabric portal home again.
In the navigation menu, select Create.
Select Create, locate the Data Engineering section, and then select Lakehouse.
Provide a name for the Lakehouse and then select Create.
Now select Get Data, and then New shortcut. From the list of shortcut options, select Microsoft OneLake.
Select the mirrored Azure Cosmos DB for NoSQL database from the list of mirrored databases in your Fabric workspace. Select the tables to use with Lakehouse, select Next, and then select Create.
Open the context menu for the table in Lakehouse and select New or existing notebook.
A new notebook automatically opens and loads a dataframe using
SELECT LIMIT 1000.Run queries like
SELECT *using Spark.df = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)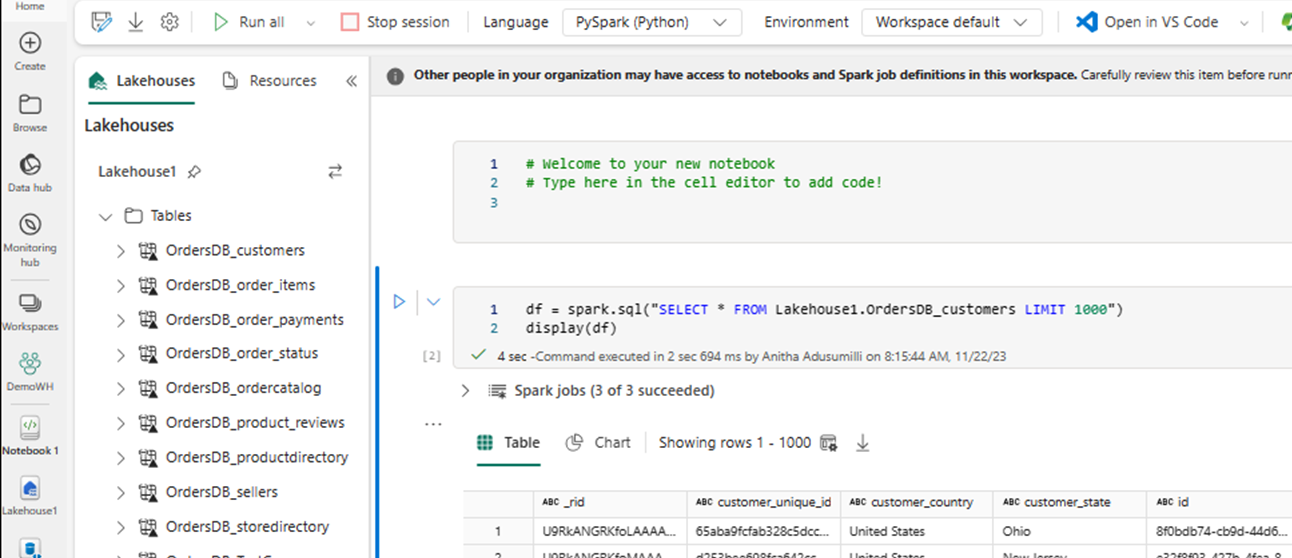
Note
This example assumes the name of your table. Use your own table when writing your Spark query.

Write back using Spark
Finally, you can use Spark and Python code to write data back to your source Azure Cosmos DB account from notebooks in Fabric. You might want to do this to write back analytical results to Cosmos DB, which can then be using as serving plane for OLTP applications.
Create four code cells within your notebook.
First, query your mirrored data.
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")Tip
The table names in these sample code blocks assume a certain data schema. Feel free to replace this with your own table and column names.
Now transform and aggregate the data.
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))Next, configure Spark to write back to your Azure Cosmos DB for NoSQL account using your credentials, database name, and container name.
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }Finally, use Spark to write back to the source database.
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()Run all of the code cells.
Important
Write operations to Azure Cosmos DB will consume request units (RUs).