Tutorial: Ingest data into a Warehouse
Applies to: ✅ Warehouse in Microsoft Fabric
In this tutorial, learn how to ingest data from Microsoft Azure Storage into a Warehouse to create tables.
Note
This tutorial forms part of an end-to-end scenario. In order to complete this tutorial, you must first complete these tutorials:
Ingest data
In this task, learn how to ingest data into the warehouse to create tables.
Ensure that the workspace you created in the first tutorial is open.
In the workspace landing pane, select + New Item to display the full list of available item types.
From the list, in the Get data section, select the Data pipeline item type.
In the New pipeline window, in the Name box, enter
Load Customer Data.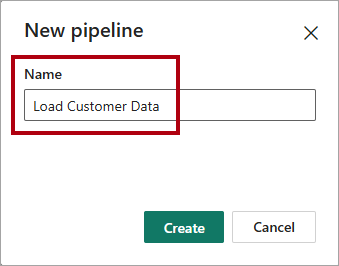
To provision the pipeline, select Create. Provisioning is complete when the Build a data pipeline landing page appears.
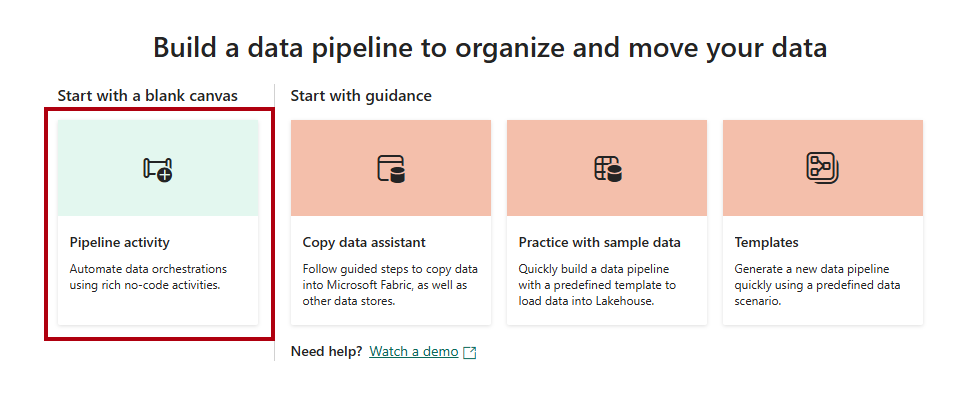
On the data pipeline landing page, select Pipeline activity.
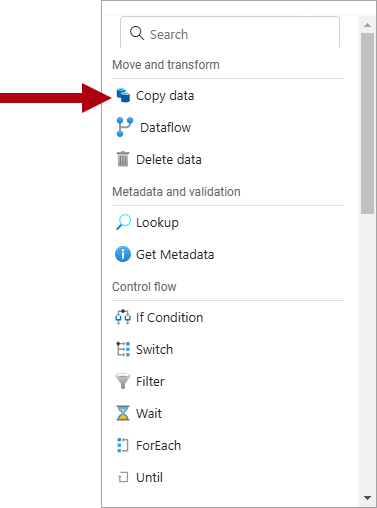
In the menu, from inside the Move and transform section, select Copy data.
On the pipeline design canvas, select the Copy data activity.
To set up the activity, on the General page, in the Name box, replace the default text with
CD Load dimension_customer.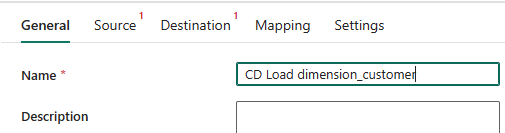
On the Source page, in the Connection dropdown, select More in order to reveal all of the data sources you can choose from, including data sources in OneLake catalog.
Select + New to create a new data source.
Search for, and then select, Azure Blobs.
On the Connect data source page, in the Account name or URL box, enter
https://fabrictutorialdata.blob.core.windows.net/sampledata/.Notice that the Connection name dropdown is automatically populated and that the authentication kind is set to Anonymous.
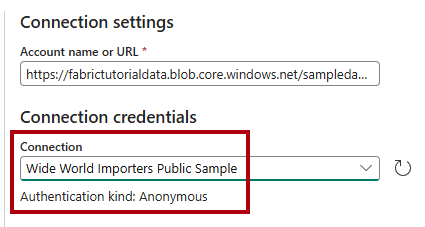
Select Connect.
On the Source page, to access the Parquet files in the data source, complete the following settings:
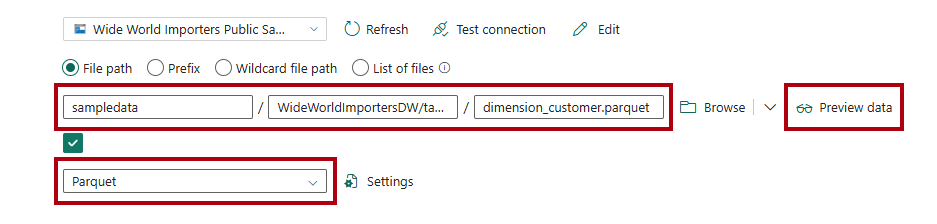
In the File path boxes, enter:
File path - Container:
sampledataFile path - Directory:
WideWorldImportersDW/tablesFile path - File name:
dimension_customer.parquet
In the File format dropdown, select Parquet.
To preview the data and test that there are no errors, select Preview data.
On the Destination page, in the Connection dropdown, select the
Wide World Importerswarehouse.For Table option, select the Auto create table option.
In the first Table box, enter
dbo.In the second box, enter
dimension_customer.
On the Home ribbon, select Run.
In the Save and run? dialog, select Save and run to have the pipeline load the
dimension_customertable.
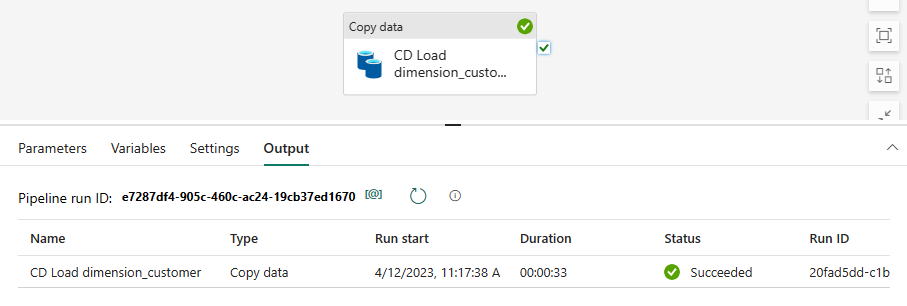
To monitor the progress of the copy activity, review the pipeline run activities in the Output page (wait for it to complete with a Succeeded status).