Delta Lake logs in Warehouse in Microsoft Fabric
Applies to: ✅ Warehouse in Microsoft Fabric
Warehouse in Microsoft Fabric is built up open file formats. User tables are stored in parquet file format, and Delta Lake logs are published for all user tables.
The Delta Lake logs opens up direct access to the warehouse's user tables for any engine that can read Delta Lake tables. This access is limited to read-only to ensure the user data maintains ACID transaction compliance. All inserts, updates, and deletes to the data in the tables must be executed through the Warehouse. Once a transaction is committed, a system background process is initiated to publish the updated Delta Lake log for the affected tables.
How to get OneLake path
The following steps detail how to get the OneLake path from a table in a warehouse:
Open Warehouse in your Microsoft Fabric workspace.
In the Object Explorer, you find more options (...) on a selected table in the Tables folder. Select the Properties menu.
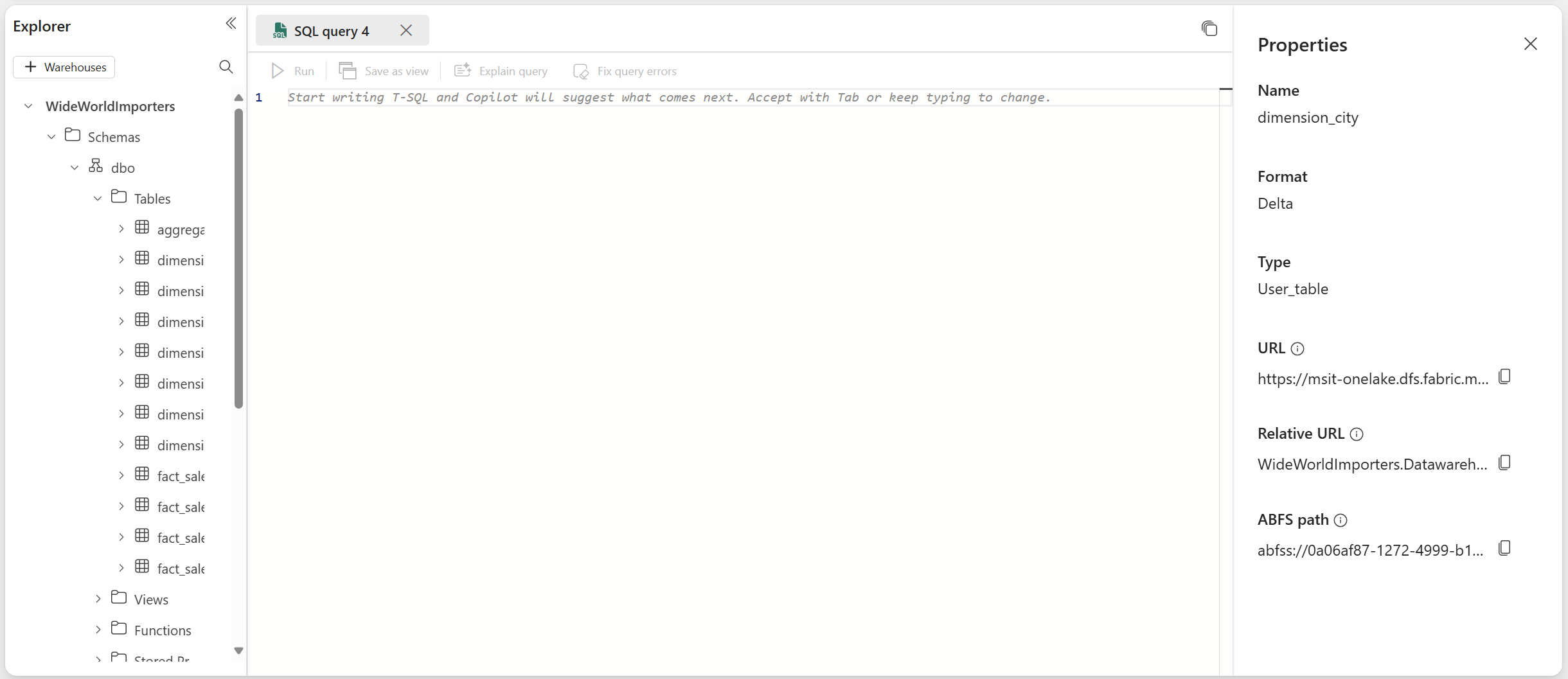
On selection, the Properties pane shows the following information:
- Name
- Format
- Type
- URL
- Relative path
- ABFS path

How to get Delta Lake logs path
You can locate Delta Lake logs via the following methods:
Delta Lake logs can be queried through shortcuts created in a lakehouse. You can view the files using a Microsoft Fabric Spark Notebook or the Lakehouse explorer in Fabric Data Engineering in the Microsoft Fabric portal.
Delta Lake logs can be found via Azure Storage Explorer, through Spark connections such as the Power BI Direct Lake mode, or using any other service that can read delta tables.
Delta Lake logs can be found in the
_delta_logfolder of each table through the OneLake Explorer in Windows, as shown in the following screenshot.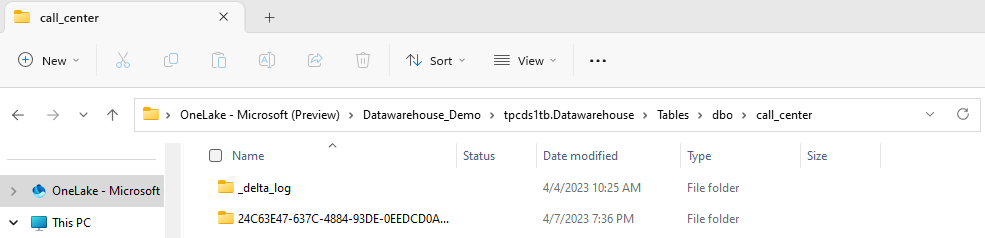

Pausing Delta Lake log publishing
Publishing of Delta Lake logs can be paused and resumed if needed. When publishing is paused, Microsoft Fabric engines that read tables outside of the Warehouse sees the data as it was before the pause. It ensures that reports remain stable and consistent, reflecting data from all tables as they existed before any changes were made to the tables. Once your data updates are complete, you can resume Delta Lake Log publishing to make all recent data changes visible to other analytical engines. Another use case for pausing Delta Lake log publishing is when users do not need interoperability with other compute engines in Microsoft Fabric, as it can help save on compute costs.
The syntax to pause and resume Delta Lake log publishing is as follows:
ALTER DATABASE CURRENT SET DATA_LAKE_LOG_PUBLISHING = PAUSED | AUTO
Example: pause and resume Delta Lake log publishing
To pause Delta Lake log publishing, use the following code snippet:
ALTER DATABASE CURRENT SET DATA_LAKE_LOG_PUBLISHING = PAUSED
Queries to warehouse tables on the current warehouse from other Microsoft Fabric engines (for example, queries from a Lakehouse) now show a version of the data as it was before pausing Delta Lake log publishing. Warehouse queries still show the latest version of data.
To resume Delta Lake log publishing, use the following code snippet:
ALTER DATABASE CURRENT SET DATA_LAKE_LOG_PUBLISHING = AUTO
When the state is changed back to AUTO, the Fabric Warehouse engine publishes logs of all recent changes made to tables on the warehouse, allowing other analytical engines in Microsoft Fabric to read the latest version of data.
Checking the status of Delta Lake log publishing
To check the current state of Delta Lake log publishing on all warehouses for the current workspace, use the following code snippet:
SELECT [name], [DATA_LAKE_LOG_PUBLISHING_DESC] FROM sys.databases
Limitations
- Table Names can only be used by Spark and other systems if they only contain these characters: A-Z a-z 0-9 and underscores.
- Column Names that will be used by Spark and other systems cannot contain:
- spaces
- tabs
- carriage returns
- [
- ,
- ;
- {
- }
- (
- )
- =
- ]