What are lakehouse schemas (Preview)?
Lakehouse supports the creation of custom schemas. Schemas allow you to group your tables together for better data discovery, access control, and more.
Create a lakehouse schema
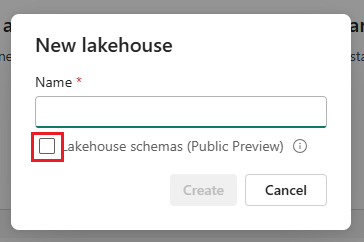
To enable schema support for your lakehouse, check the box next to Lakehouse schemas (Public Preview) when you create it.
Important
Workspace names must only contain alphanumeric characters due to preview limitations. If special characters are used in workspace names some of Lakehouse features won't work.
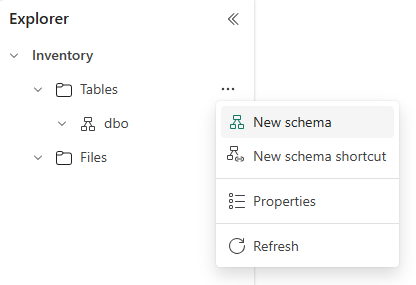
Once you create the lakehouse, you can find a default schema named dbo under Tables. This schema is always there and can't be changed or removed. To create a new schema, hover over Tables, select …, and choose New schema. Enter your schema name and select Create. You'll see your schema listed under Tables in alphabetical order.
Store tables in lakehouse schemas
You need a schema name to store a table in a schema. Otherwise, it goes to the default dbo schema.
df.write.mode("Overwrite").saveAsTable("contoso.sales")
You can use Lakehouse Explorer to arrange your tables and drag and drop table names to different schemas.
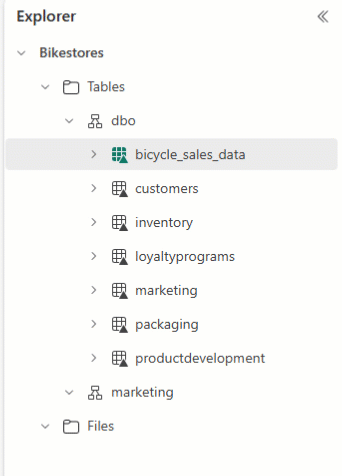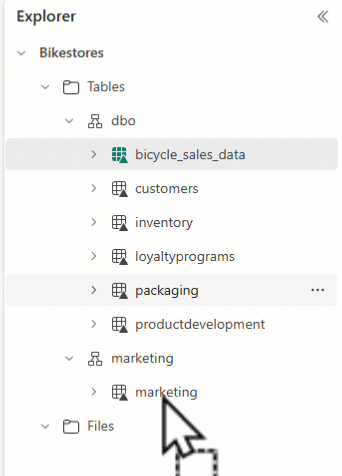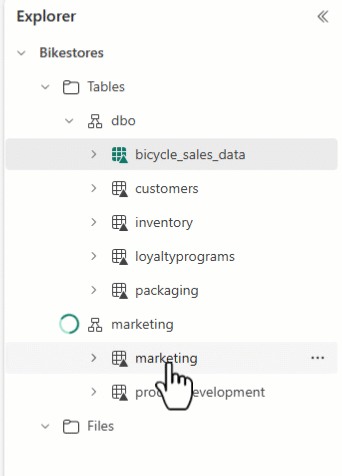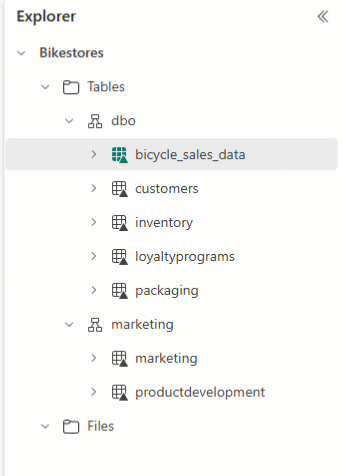
Caution
If you modify the table, you must also update related items like notebook code or dataflows to ensure they are aligned with the correct schema.
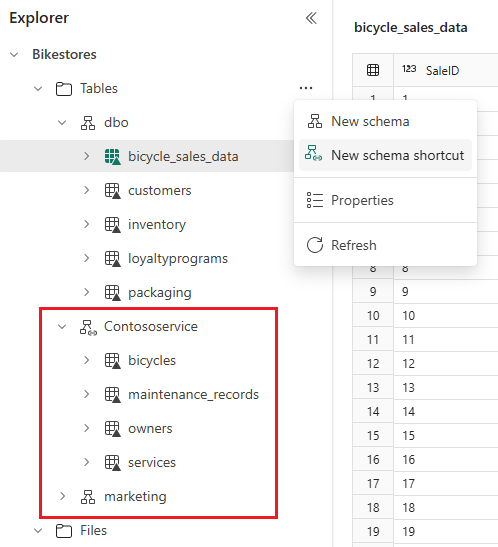
Bring multiple tables with schema shortcut
To reference multiple Delta tables from other Fabric lakehouse or external storage, use schema shortcut that displays all tables under the chosen schema or folder. Any changes to the tables in the source location also appear in the schema. To create a schema shortcut, hover over Tables, select on …, and choose New schema shortcut. Then select a schema on another lakehouse, or a folder with Delta tables on your external storage like Azure Data Lake Storage (ADLS) Gen2. That creates a new schema with your referenced tables.
Access lakehouse schemas for Power BI reporting
To make your semantic model, just choose the tables that you want to use. Tables can be in different schemas. If tables from different schemas share the same name, you see numbers next to table names when in the model view.
Lakehouse schemas in notebook
When you look at a schema enabled lakehouse in the notebook object explorer, you see tables are in schemas. You can drag and drop table into a code cell and get a code snippet that refers to the schema where the table is located. Use this namespace to refer to tables in your code: "workspace.lakehouse.schema.table". If you leave out any of the elements, the executor uses default setting. For example, if you only give table name, it uses default schema (dbo) from default lakehouse for the notebook.
Important
If you want to use schemas in your code make sure that the default lakehouse for the notebook is schema enabled.
Cross-workspace Spark SQL queries
Use the namespace "workspace.lakehouse.schema.table” to refer to tables in your code. This way, you can join tables from different workspaces if the user who runs the code has permission to access the tables.
SELECT *
FROM operations.hr.hrm.employees as employees
INNER JOIN global.corporate.company.departments as departments
ON employees.deptno = departments.deptno;
Important
Make sure you join tables only from lakehouses that have schemas enabled. Joining tables from lakehouses that don’t have schemas enabled won’t work.
Public preview limitations
Below listed unsupported features/functionalities are for current release of public preview. They'll be resolved in the coming releases before General Availability.
| Unsupported Features/ Functionality | Notes |
|---|---|
| Shared lakehouse | Using workspace in the namespace for shared lakehouses won't work, e.g. wokrkspace.sharedlakehouse.schema.table. THe user must have workspace role in order to use workspace in the namaspace. |
| Non-Delta, Managed table schema | Getting schema for managed, non-Delta formatted tables (for example, CSV) isn't supported. Expanding these tables in lakehouse explorer doesn't show any schema information in the UX. |
| External Spark tables | External Spark table operations (for example, discovery, getting schema, etc.) aren't supported. These tables are unidentified in the UX. |
| Public API | Public APIs (List tables, Load table, exposing defaultSchema extended property etc.) aren't supported for schema enabled Lakehouse. Existing public APIs called on a schema enabled Lakehouse results an error. |
| Update table properties | Not supported. |
| Workspace name containing special characters | Workspace with special characters (for example, space, slashes) isn't supported. A user error is shown. |
| Spark views | Not supported. |
| Hive specific features | Not supported. |
| Spark.catalog API | Not supported. Use Spark SQL instead. |
USE <schemaName> |
Doesn't work cross workspaces, but supported within same workspace. |
| Migration | Migration of existing non-schema Lakehouses to schema-based Lakehouses isn't supported. |