System.IO.Pipelines in .NET
System.IO.Pipelines is a library that is designed to make it easier to do high-performance I/O in .NET. It's a library targeting .NET Standard that works on all .NET implementations.
The library is available in the System.IO.Pipelines Nuget package.
What problem does System.IO.Pipelines solve
Apps that parse streaming data are composed of boilerplate code having many specialized and unusual code flows. The boilerplate and special case code is complex and difficult to maintain.
System.IO.Pipelines was architected to:
- Have high performance parsing streaming data.
- Reduce code complexity.
The following code is typical for a TCP server that receives line-delimited messages (delimited by '\n') from a client:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
The preceding code has several problems:
- The entire message (end of line) might not be received in a single call to
ReadAsync. - It's ignoring the result of
stream.ReadAsync.stream.ReadAsyncreturns how much data was read. - It doesn't handle the case where multiple lines are read in a single
ReadAsynccall. - It allocates a
bytearray with each read.
To fix the preceding problems, the following changes are required:
Buffer the incoming data until a new line is found.
Parse all the lines returned in the buffer.
It's possible that the line is bigger than 1 KB (1024 bytes). The code needs to resize the input buffer until the delimiter is found in order to fit the complete line inside the buffer.
- If the buffer is resized, more buffer copies are made as longer lines appear in the input.
- To reduce wasted space, compact the buffer used for reading lines.
Consider using buffer pooling to avoid allocating memory repeatedly.
The following code addresses some of these problems:
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
The previous code is complex and doesn't address all the problems identified. High-performance networking usually means writing complex code to maximize performance. System.IO.Pipelines was designed to make writing this type of code easier.
Pipe
The Pipe class can be used to create a PipeWriter/PipeReader pair. All data written into the PipeWriter is available in the PipeReader:
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
Pipe basic usage
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
There are two loops:
FillPipeAsyncreads from theSocketand writes to thePipeWriter.ReadPipeAsyncreads from thePipeReaderand parses incoming lines.
There are no explicit buffers allocated. All buffer management is delegated to the PipeReader and PipeWriter implementations. Delegating buffer management makes it easier for consuming code to focus solely on the business logic.
In the first loop:
- PipeWriter.GetMemory(Int32) is called to get memory from the underlying writer.
- PipeWriter.Advance(Int32)
is called to tell the
PipeWriterhow much data was written to the buffer. - PipeWriter.FlushAsync is called to make the data available to the
PipeReader.
In the second loop, the PipeReader consumes the buffers written by PipeWriter. The buffers come from the socket. The call to PipeReader.ReadAsync:
Returns a ReadResult that contains two important pieces of information:
- The data that was read in the form of
ReadOnlySequence<byte>. - A boolean
IsCompletedthat indicates if the end of data (EOF) has been reached.
- The data that was read in the form of
After finding the end of line (EOL) delimiter and parsing the line:
- The logic processes the buffer to skip what's already processed.
PipeReader.AdvanceTois called to tell thePipeReaderhow much data has been consumed and examined.
The reader and writer loops end by calling Complete. Complete lets the underlying Pipe release the memory it allocated.
Backpressure and flow control
Ideally, reading and parsing work together:
- The reading thread consumes data from the network and puts it in buffers.
- The parsing thread is responsible for constructing the appropriate data structures.
Typically, parsing takes more time than just copying blocks of data from the network:
- The reading thread gets ahead of the parsing thread.
- The reading thread has to either slow down or allocate more memory to store the data for the parsing thread.
For optimal performance, there's a balance between frequent pauses and allocating more memory.
To solve the preceding problem, the Pipe has two settings to control the flow of data:
- PauseWriterThreshold: Determines how much data should be buffered before calls to FlushAsync pause.
- ResumeWriterThreshold: Determines how much data the reader has to observe before calls to
PipeWriter.FlushAsyncresume.
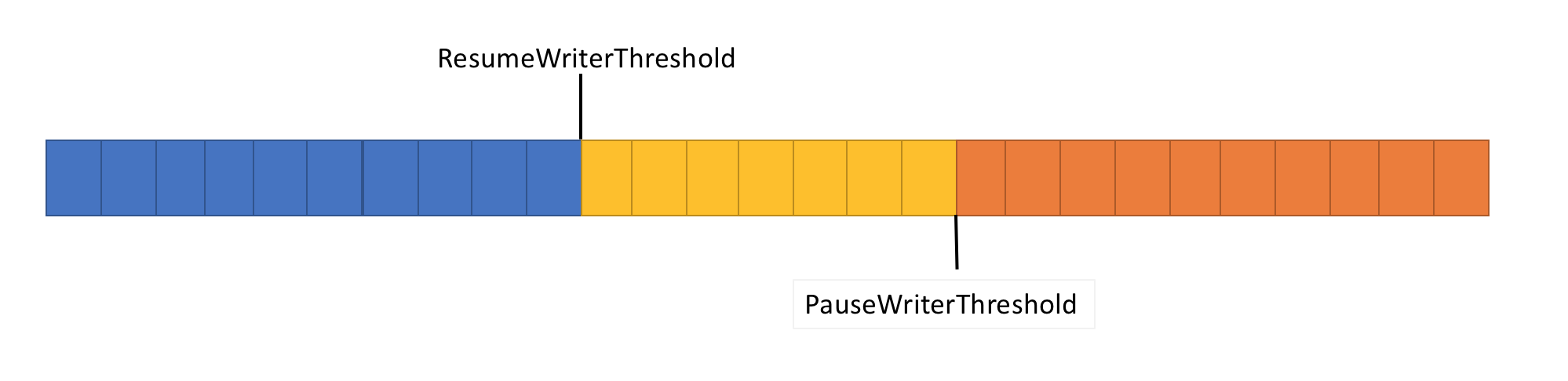
- Returns an incomplete
ValueTask<FlushResult>when the amount of data in thePipecrossesPauseWriterThreshold. - Completes
ValueTask<FlushResult>when it becomes lower thanResumeWriterThreshold.
Two values are used to prevent rapid cycling, which can occur if one value is used.
Examples
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
PipeScheduler
Typically when using async and await, asynchronous code resumes on either a TaskScheduler or the current SynchronizationContext.
When doing I/O, it's important to have fine-grained control over where the I/O is performed. This control allows taking advantage of CPU caches effectively. Efficient caching is critical for high-performance apps like web servers. PipeScheduler provides control over where asynchronous callbacks run. By default:
- The current SynchronizationContext is used.
- If there's no
SynchronizationContext, it uses the thread pool to run callbacks.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool is the PipeScheduler implementation that queues callbacks to the thread pool. PipeScheduler.ThreadPool is the default and generally the best choice. PipeScheduler.Inline can cause unintended consequences such as deadlocks.
Pipe reset
It's frequently efficient to reuse the Pipe object. To reset the pipe, call PipeReader Reset when both the PipeReader and PipeWriter are complete.
PipeReader
PipeReader manages memory on the caller's behalf. Always call PipeReader.AdvanceTo after calling PipeReader.ReadAsync. This lets the PipeReader know when the caller is done with the memory so that it can be tracked. The ReadOnlySequence<byte> returned from PipeReader.ReadAsync is only valid until the call the PipeReader.AdvanceTo. It's illegal to use ReadOnlySequence<byte> after calling PipeReader.AdvanceTo.
PipeReader.AdvanceTo takes two SequencePosition arguments:
- The first argument determines how much memory was consumed.
- The second argument determines how much of the buffer was observed.
Marking data as consumed means that the pipe can return the memory to the underlying buffer pool. Marking data as observed controls what the next call to PipeReader.ReadAsync does. Marking everything as observed means that the next call to PipeReader.ReadAsync won't return until there's more data written to the pipe. Any other value will make the next call to PipeReader.ReadAsync return immediately with the observed and unobserved data, but not data that has already been consumed.
Read streaming data scenarios
There are a couple of typical patterns that emerge when trying to read streaming data:
- Given a stream of data, parse a single message.
- Given a stream of data, parse all available messages.
The following examples use the TryParseLines method for parsing messages from a ReadOnlySequence<byte>. TryParseLines parses a single message and updates the input buffer to trim the parsed message from the buffer. TryParseLines isn't part of .NET, it's a user written method used in the following sections.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
Read a single message
The following code reads a single message from a PipeReader and returns it to the caller.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
The preceding code:
- Parses a single message.
- Updates the consumed
SequencePositionand examinedSequencePositionto point to the start of the trimmed input buffer.
The two SequencePosition arguments are updated because TryParseLines removes the parsed message from the input buffer. Generally, when parsing a single message from the buffer, the examined position should be one of the following:
- The end of the message.
- The end of the received buffer if no message was found.
The single message case has the most potential for errors. Passing the wrong values to examined can result in an out of memory exception or an infinite loop. For more information, see the PipeReader common problems section in this article.
Reading multiple messages
The following code reads all messages from a PipeReader and calls ProcessMessageAsync on each.
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Cancellation
PipeReader.ReadAsync:
- Supports passing a CancellationToken.
- Throws an OperationCanceledException if the
CancellationTokenis canceled while there's a read pending. - Supports a way to cancel the current read operation via PipeReader.CancelPendingRead, which avoids raising an exception. Calling
PipeReader.CancelPendingReadcauses the current or next call toPipeReader.ReadAsyncto return a ReadResult withIsCanceledset totrue. This can be useful for halting the existing read loop in a non-destructive and non-exceptional way.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
PipeReader common problems
Passing the wrong values to
consumedorexaminedmay result in reading already read data.Passing
buffer.Endas examined may result in:- Stalled data
- Possibly an eventual Out of Memory (OOM) exception if data isn't consumed. For example,
PipeReader.AdvanceTo(position, buffer.End)when processing a single message at a time from the buffer.
Passing the wrong values to
consumedorexaminedmay result in an infinite loop. For example,PipeReader.AdvanceTo(buffer.Start)ifbuffer.Starthasn't changed will cause the next call toPipeReader.ReadAsyncto return immediately before new data arrives.Passing the wrong values to
consumedorexaminedmay result in infinite buffering (eventual OOM).Using the
ReadOnlySequence<byte>after callingPipeReader.AdvanceTomay result in memory corruption (use after free).Failing to call
PipeReader.Complete/CompleteAsyncmay result in a memory leak.Checking ReadResult.IsCompleted and exiting the reading logic before processing the buffer results in data loss. The loop exit condition should be based on
ReadResult.Buffer.IsEmptyandReadResult.IsCompleted. Doing this incorrectly could result in an infinite loop.
Problematic code
❌ Data loss
The ReadResult can return the final segment of data when IsCompleted is set to true. Not reading that data before exiting the read loop will result in data loss.
Warning
Do NOT use the following code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The following sample is provided to explain PipeReader Common problems.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
Warning
Do NOT use the preceding code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The preceding sample is provided to explain PipeReader Common problems.
❌ Infinite loop
The following logic may result in an infinite loop if the Result.IsCompleted is true but there's never a complete message in the buffer.
Warning
Do NOT use the following code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The following sample is provided to explain PipeReader Common problems.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Warning
Do NOT use the preceding code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The preceding sample is provided to explain PipeReader Common problems.
Here's another piece of code with the same problem. It's checking for a non-empty buffer before checking ReadResult.IsCompleted. Because it's in an else if, it will loop forever if there's never a complete message in the buffer.
Warning
Do NOT use the following code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The following sample is provided to explain PipeReader Common problems.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Warning
Do NOT use the preceding code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The preceding sample is provided to explain PipeReader Common problems.
❌ Unresponsive application
Unconditionally calling PipeReader.AdvanceTo with buffer.End in the examined position may result in the application becoming unresponsive when parsing a single message. The next call to PipeReader.AdvanceTo won't return until:
- There's more data written to the pipe.
- And the new data wasn't previously examined.
Warning
Do NOT use the following code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The following sample is provided to explain PipeReader Common problems.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
Warning
Do NOT use the preceding code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The preceding sample is provided to explain PipeReader Common problems.
❌ Out of Memory (OOM)
With the following conditions, the following code keeps buffering until an OutOfMemoryException occurs:
- There's no maximum message size.
- The data returned from the
PipeReaderdoesn't make a complete message. For example, it doesn't make a complete message because the other side is writing a large message (For example, a 4-GB message).
Warning
Do NOT use the following code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The following sample is provided to explain PipeReader Common problems.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
Warning
Do NOT use the preceding code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The preceding sample is provided to explain PipeReader Common problems.
❌ Memory Corruption
When writing helpers that read the buffer, any returned payload should be copied before calling Advance. The following example will return memory that the Pipe has discarded and may reuse it for the next operation (read/write).
Warning
Do NOT use the following code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The following sample is provided to explain PipeReader Common problems.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
Warning
Do NOT use the preceding code. Using this sample will result in data loss, hangs, security issues and should NOT be copied. The preceding sample is provided to explain PipeReader Common problems.
PipeWriter
The PipeWriter manages buffers for writing on the caller's behalf. PipeWriter implements IBufferWriter<byte>. IBufferWriter<byte> makes it possible to get access to buffers to perform writes without extra buffer copies.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
The previous code:
- Requests a buffer of at least 5 bytes from the
PipeWriterusing GetMemory. - Writes bytes for the ASCII string
"Hello"to the returnedMemory<byte>. - Calls Advance to indicate how many bytes were written to the buffer.
- Flushes the
PipeWriter, which sends the bytes to the underlying device.
The previous method of writing uses the buffers provided by the PipeWriter. It could also have used PipeWriter.WriteAsync, which:
- Copies the existing buffer to the
PipeWriter. - Calls
GetSpan,Advanceas appropriate and calls FlushAsync.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
Cancellation
FlushAsync supports passing a CancellationToken. Passing a CancellationToken results in an OperationCanceledException if the token is canceled while there's a flush pending. PipeWriter.FlushAsync supports a way to cancel the current flush operation via PipeWriter.CancelPendingFlush without raising an exception. Calling PipeWriter.CancelPendingFlush causes the current or next call to PipeWriter.FlushAsync or PipeWriter.WriteAsync to return a FlushResult with IsCanceled set to true. This can be useful for halting the yielding flush in a non-destructive and non-exceptional way.
PipeWriter common problems
- GetSpan and GetMemory return a buffer with at least the requested amount of memory. Don't assume exact buffer sizes.
- There's no guarantee that successive calls will return the same buffer or the same-sized buffer.
- A new buffer must be requested after calling Advance to continue writing more data. The previously acquired buffer can't be written to.
- Calling
GetMemoryorGetSpanwhile there's an incomplete call toFlushAsyncisn't safe. - Calling
CompleteorCompleteAsyncwhile there's unflushed data can result in memory corruption.
Tips for using PipeReader and PipeWriter
The following tips will help you use the System.IO.Pipelines classes successfully:
- Always complete the PipeReader and PipeWriter, including an exception where applicable.
- Always call PipeReader.AdvanceTo after calling PipeReader.ReadAsync.
- Periodically
awaitPipeWriter.FlushAsync while writing, and always check FlushResult.IsCompleted. Abort writing ifIsCompletedistrue, as that indicates the reader is completed and no longer cares about what is written. - Do call PipeWriter.FlushAsync after writing something that you want the
PipeReaderto have access to. - Do not call
FlushAsyncif the reader can't start untilFlushAsyncfinishes, as that may cause a deadlock. - Ensure that only one context "owns" a
PipeReaderorPipeWriteror accesses them. These types are not thread-safe. - Never access a ReadResult.Buffer after calling
AdvanceToor completing thePipeReader.
IDuplexPipe
The IDuplexPipe is a contract for types that support both reading and writing. For example, a network connection would be represented by an IDuplexPipe.
Unlike Pipe, which contains a PipeReader and a PipeWriter, IDuplexPipe represents a single side of a full duplex connection. That means what is written to the PipeWriter will not be read from the PipeReader.
Streams
When reading or writing stream data, you typically read data using a de-serializer and write data using a serializer. Most of these read and write stream APIs have a Stream parameter. To make it easier to integrate with these existing APIs, PipeReader and PipeWriter expose an AsStream method. AsStream returns a Stream implementation around the PipeReader or PipeWriter.
Stream example
PipeReader and PipeWriter instances can be created using the static Create methods given a Stream object and optional corresponding creation options.
The StreamPipeReaderOptions allow for control over the creation of the PipeReader instance with the following parameters:
- StreamPipeReaderOptions.BufferSize is the minimum buffer size in bytes used when renting memory from the pool, and defaults to
4096. - StreamPipeReaderOptions.LeaveOpen flag determines whether or not the underlying stream is left open after the
PipeReadercompletes, and defaults tofalse. - StreamPipeReaderOptions.MinimumReadSize represents the threshold of remaining bytes in the buffer before a new buffer is allocated, and defaults to
1024. - StreamPipeReaderOptions.Pool is the
MemoryPool<byte>used when allocating memory, and defaults tonull.
The StreamPipeWriterOptions allow for control over the creation of the PipeWriter instance with the following parameters:
- StreamPipeWriterOptions.LeaveOpen flag determines whether or not the underlying stream is left open after the
PipeWritercompletes, and defaults tofalse. - StreamPipeWriterOptions.MinimumBufferSize represents the minimum buffer size to use when renting memory from the Pool, and defaults to
4096. - StreamPipeWriterOptions.Pool is the
MemoryPool<byte>used when allocating memory, and defaults tonull.
Important
When creating PipeReader and PipeWriter instances using the Create methods, you need to consider the Stream object lifetime. If you need access to the stream after the reader or writer is done with it, you'll need to set the LeaveOpen flag to true on the creation options. Otherwise, the stream will be closed.
The following code demonstrates the creation of PipeReader and PipeWriter instances using the Create methods from a stream.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
The application uses a StreamReader to read the lorem-ipsum.txt file as a stream, and it must end with a blank line. The FileStream is passed to PipeReader.Create, which instantiates a PipeReader object. The console application then passes its standard output stream to PipeWriter.Create using Console.OpenStandardOutput(). The example supports cancellation.