Tutorial: Migrate SQL Server to Azure SQL Managed Instance with DMS
You can use Azure Database Migration Service (DMS) and the Azure SQL migration extension in Azure Data Studio to migrate databases from a SQL Server instance to Azure SQL Managed Instance with minimum downtime.
For database migration methods that might require some manual configuration, see Migration guide: SQL Server to Azure SQL Managed Instance.
Tip
In Azure Database Migration Service, you can migrate your databases offline or while they are online. In an offline migration, application downtime starts when the migration starts. To limit downtime to the time it takes you to cut over to the new environment after the migration, use an online migration. We recommend that you test an offline migration to determine whether the downtime is acceptable. If the expected downtime isn't acceptable, do an online migration.
In this tutorial, you migrate the AdventureWorks2022 database from an on-premises instance of SQL Server to an instance of Azure SQL Managed Instance, using Azure Data Studio and Database Migration Service (DMS). This tutorial uses online migration mode, where application downtime is limited to a short cutover at the end of the migration.
In this tutorial, you learn how to:
- Launch the Migrate to Azure SQL wizard in Azure Data Studio
- Run an assessment of your source SQL Server databases
- Collect performance data from your source SQL Server instance
- Get a recommendation of the Azure SQL Managed Instance SKU best suited for your workload
- Specify details of your source SQL Server instance, backup location, and target instance of Azure SQL Managed Instance
- Create a new Azure Database Migration Service and install the self-hosted integration runtime to access source server and backups
- Start and monitor the progress for your migration
- Perform the migration cutover when you're ready
Important
Prepare for migration and reduce the duration of the online migration process as much as possible, to minimize the risk of interruption caused by instance reconfiguration or planned maintenance. In case of such an event, migration process will start from the beginning. In case of planned maintenance, there's a grace period of 36 hours where the target Azure SQL Managed Instance configuration or maintenance will be held before migration process is restarted.
Prerequisites
To complete this tutorial, you need to:
Install the Azure SQL migration extension for Azure Data Studio from the Azure Data Studio marketplace
Have an Azure account that's assigned to one of the following built-in roles:
Contributor for the target instance of Azure SQL Managed Instance and for the storage account where you upload your database backup files from a Server Message Block (SMB) network share, and Reader role for the Azure resource groups that contain the target instance of Azure SQL Managed Instance or your Azure storage account.
Owner or Contributor role for the Azure subscription (required if you create a new Database Migration Service instance).
As an alternative to using one of these built-in roles, you can assign custom roles.
Important
An Azure account is required only when you configure the migration steps. An Azure account isn't required for the assessment or to view Azure recommendations in the migration wizard in Azure Data Studio.
Create a target instance of Azure SQL Managed Instance.
Ensure that the logins used to connect the source SQL Server are members of the sysadmin server role or have
CONTROL SERVERpermission.Provide an SMB network share, Azure storage account file share, or Azure storage account blob container that contains your full database backup files and subsequent transaction log backup files. Database Migration Service uses the backup location during database migration.
The Azure SQL migration extension for Azure Data Studio doesn't take database backups, and doesn't initiate any database backups on your behalf. Instead, the service uses existing database backup files for the migration.
If your database backup files are in an SMB network share, create an Azure storage account that allows the DMS service to upload the database backup files, and to migrate databases. Make sure you create the Azure storage account in the same region where you create your instance of Database Migration Service.
You can write each backup to either a separate backup file or to multiple backup files. Appending multiple backups such as full and transaction logs into a single backup media isn't supported.
You can provide compressed backups to reduce the likelihood of experiencing potential issues associated with migrating large backups.
Ensure that the service account running the source SQL Server instance has read and write permissions on the SMB network share that contains database backup files.
If you're migrating a database that's protected by transparent data encryption (TDE), the certificate from the source SQL Server instance must be migrated to your Azure SQL target before you migrate data. For more information about migrating TDE-enabled databases, see Tutorial: Migrate TDE-enabled databases (preview) to Azure SQL in Azure Data Studio.
If your database contains sensitive data protected by Always Encrypted, the migration process automatically migrates your Always Encrypted keys to your Azure SQL target.
If your database backups are on a network file share, provide a computer on which you can install a self-hosted integration runtime to access and migrate database backups. The migration wizard gives you the download link and authentication keys to download and install your self-hosted integration runtime.
In preparation for the migration, ensure that the computer where you plan to install the self-hosted integration runtime has the following outbound firewall rules and domain names enabled:
Domain names Outbound port Description Public cloud: {datafactory}.{region}.datafactory.azure.net
or*.frontend.clouddatahub.net
Azure Government:{datafactory}.{region}.datafactory.azure.us
Microsoft Azure operated by 21Vianet:{datafactory}.{region}.datafactory.azure.cn443 Required by the self-hosted integration runtime to connect to the Data Migration service.
For a newly created data factory in the public cloud, locate the fully qualified domain name (FQDN) from your self-hosted integration runtime key, which is in format{datafactory}.{region}.datafactory.azure.net.
For an existing data factory, if you don't see the FQDN in your self-hosted integration key, use*.frontend.clouddatahub.netinstead.download.microsoft.com443 Required by the self-hosted integration runtime for downloading the updates. If you have disabled autoupdate, you can skip configuring this domain. .core.windows.net443 Used by the self-hosted integration runtime that connects to the Azure storage account to upload database backups from your network share. Tip
If your database backup files are already provided in an Azure storage account, a self-hosted integration runtime isn't required during the migration process.
If you use a self-hosted integration runtime, make sure that the computer on which the runtime is installed can connect to the source SQL Server instance and the network file share where backup files are located.
Enable outbound port 445 to allow access to the network file share. For more information, see recommendations for using a self-hosted integration runtime.
If you use Database Migration Service for the first time, make sure that
Microsoft.DataMigrationresource provider is registered in your subscription. Follow the steps to register the resource provider.
Launch the Migrate to Azure SQL wizard in Azure Data Studio
To open the Migrate to Azure SQL wizard:
In Azure Data Studio, go to Connections. Select and connect to your on-premises instance of SQL Server. You also can connect to SQL Server on an Azure virtual machine.
Right-click the server connection and select Manage.
In the server menu, under General, select Azure SQL Migration.
In the Azure SQL Migration dashboard, select Migrate to Azure SQL to open the migration wizard.
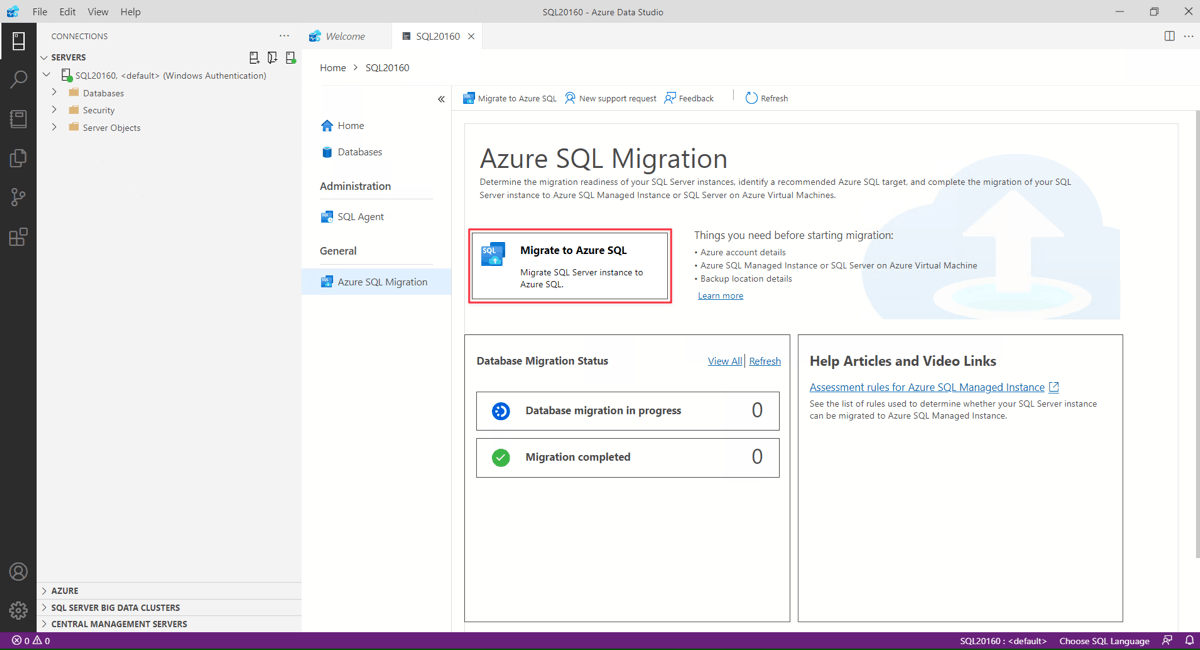
On the first page of the wizard, start a new session or resume a previously saved session.

Run database assessment, collect performance data and get Azure recommendation
Select the databases you want to assess, and select Next.
Select Azure SQL Managed Instance as the target.
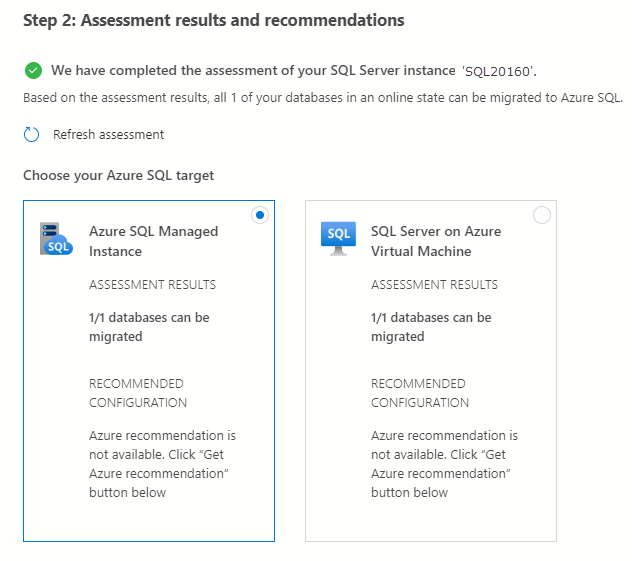
Select View/Select to view the assessment results.
In the assessment results, select the database, and then review the assessment report to make sure no issues were found.
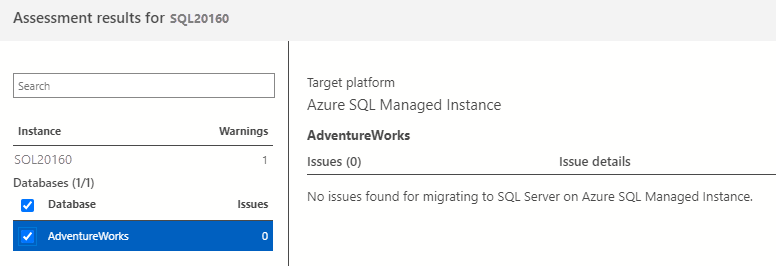
Select Get Azure recommendation to open the recommendations pane.
Select Collect performance data now. Select a folder on your local computer to store the performance logs, and then select Start.
Azure Data Studio will now collect performance data until you either stop the collection, press the Next button in the wizard or close Azure Data Studio.
After about 10 minutes, Azure Data Studio indicates that a recommendation is available for Azure SQL Managed Instance. You can also press the Refresh recommendation link after the initial 10 minutes to refresh and refine the recommendation with the extra data collected. An extended assessment is especially helpful if your usage patterns vary over time.
In the selected Azure SQL Managed Instance target, select View details to open the detailed SKU recommendation report.
In Review Azure SQL Managed Instance Recommendations, review the recommendation. To save a copy of the recommendation, select the Save recommendation report checkbox.
Select Close to close the recommendations pane.
Select Next to continue your database migration in the wizard.
Configure migration settings
Specify your Azure SQL Managed Instance by selecting your subscription, location, resource group from the corresponding dropdown lists and then select Next.
Select Online migration as the migration mode.
Note
In the online migration mode, the source SQL Server database can be used for read and write activity while database backups are continuously restored on target Azure SQL Managed Instance. Application downtime is limited to duration for the cutover at the end of migration.
Select the location of your database backups. Your database backups can either be located on an on-premises network share or in an Azure storage blob container.
Note
If your database backups are provided in an on-premises network share, DMS will require you to set up a self-hosted integration runtime in the next step of the wizard. If a self-hosted integration runtime is required to access your source database backups, check the validity of the backup set and upload them to your Azure storage account. If your database backups are already on an Azure storage blob container, you don't need to set up a self-hosted integration runtime.
For backups that are located on a network share, enter or select the following information:
| Field | Description |
|---|---|
| Source Credentials - Username | The credential (Windows / SQL authentication) to connect to the source SQL Server instance and validate the backup files. |
| Source Credentials - Password | The credential (Windows / SQL authentication) to connect to the source SQL Server instance and validate the backup files. |
| Network share location that contains backups | The network share location that contains the full and transaction log backup files. Any invalid files or backup files in the network share that don't belong to the valid backup set are automatically ignored during the migration process. |
| Windows user account with read access to the network share location | The Windows credential (username) that has read access to the network share to retrieve the backup files. |
| Password | The Windows credential (password) that has read access to the network share to retrieve the backup files. |
| Target database name | You can modify the target database name during the migration process. |
| Storage account details | The resource group and storage account where backup files are uploaded. You don't need to create a container. DMS automatically creates a blob container in the specified storage account during the upload process. |
For backups that are stored in an Azure storage blob container, enter or select the following information:
| Field | Description |
|---|---|
| Target database name | The target database name can be modified if you wish to change the database name on the target during the migration process. |
| Storage account details | The resource group, storage account and container where backup files are located. |
Important
If loopback check functionality is enabled and the source SQL Server and file share are on the same computer, then source won't be able to access the file share using FQDN. To fix this issue, disable loopback check functionality using the instructions here
The Azure SQL migration extension for Azure Data Studio no longer requires specific configurations on your Azure Storage account network settings to migrate your SQL Server databases to Azure. However, depending on your database backup location and desired storage account network settings, there are a few steps needed to ensure your resources can access the Azure Storage account. See the following table for the various migration scenarios and network configurations:
| Scenario | SMB network share | Azure Storage account container |
|---|---|---|
| Enabled from all networks | No extra steps | No extra steps |
| Enabled from selected virtual networks and IP addresses | See 1a | See 2a |
| Enabled from selected virtual networks and IP addresses + private endpoint | See 1b | See 2b |
1a - Azure Blob storage network configuration
If you have your Self-Hosted Integration Runtime (SHIR) installed on an Azure VM, see section 1b - Azure Blob storage network configuration. If you have your Self-Hosted Integration Runtime (SHIR) installed on your on-premises network, you need to add your client IP address of the hosting machine in your Azure Storage account as so:

To apply this specific configuration, connect to the Azure portal from the SHIR machine, open the Azure Storage account configuration, select Networking, and then mark the Add your client IP address checkbox. Select Save to make the change persistent. See section 2a - Azure Blob storage network configuration (Private endpoint) for the remaining steps.
1b - Azure Blob storage network configuration
If your SHIR is hosted on an Azure VM, you need to add the virtual network of the VM to the Azure Storage account since the VM has a non-public IP address that can't be added to the IP address range section.

To apply this specific configuration, locate your Azure Storage account, from the Data storage panel select Networking, then mark the Add existing virtual network checkbox. A new panel opens up. Select the subscription, virtual network, and subnet of the Azure VM hosting the integration runtime. This information can be found on the Overview page of the Azure VM. The subnet might say Service endpoint required if so, select Enable. Once everything is ready, save the updates. Refer to section 2a - Azure Blob storage network configuration (Private endpoint) for the remaining required steps.
2a - Azure Blob storage network configuration (private endpoint)
If your backups are placed directly into an Azure Storage container, all previous steps are unnecessary since there's no integration runtime communicating with the Azure Storage account. However, we still need to ensure that the target SQL Server instance can communicate with the Azure Storage account to restore the backups from the container. To apply this specific configuration, follow the instructions in section 1b - Azure Blob storage network configuration, specifying the target SQL instance Virtual Network when filling out the "Add existing virtual network" popup.
2b - Azure Blob storage network configuration (private endpoint)
If you have a private endpoint set up on your Azure Storage account, follow the steps outlined in section 2a - Azure Blob storage network configuration (private endpoint). However, you need to select the subnet of the private endpoint, not just the target SQL Server subnet. Ensure the private endpoint is hosted in the same VNet as the target SQL Server instance. If it isn't, create another private endpoint using the process in the Azure Storage account configuration section.
Create a Database Migration Service instance
Create a new Azure Database Migration Service or reuse an existing Service that you previously created.
If you previously created a Database Migration Service instance by using the Azure portal, you can't reuse the instance in the migration wizard in Azure Data Studio. You can reuse an instance only if you created the instance by using Azure Data Studio.
Use an existing instance of Database Migration Service
To use an existing instance of Database Migration Service:
In Resource group, select the resource group that contains an existing instance of Database Migration Service.
In Azure Database Migration Service, select an existing instance of Database Migration Service that's in the selected resource group.
Select Next.
Create a new instance of Database Migration Service
To create a new instance of Database Migration Service:
In Resource group, create a new resource group to contain a new instance of Database Migration Service.
Under Azure Database Migration Service, select Create new.
In Create Azure Database Migration Service, enter a name for your Database Migration Service instance, and then select Create.
After successful creation of DMS, you'll be provided with details to set up integration runtime.
Select the Download and install integration runtime link to open the download link in a web browser. Download the integration runtime, and then install it on a computer that meets the prerequisites to connect to the source SQL Server instance.
When installation is finished, Microsoft Integration Runtime Configuration Manager automatically opens to begin the registration process.
In the Authentication key table, copy one of the authentication keys that are provided in the wizard and paste it in Azure Data Studio. If the authentication key is valid, a green check icon appears in Integration Runtime Configuration Manager. A green check indicates that you can continue to Register.
After you register the self-hosted integration runtime, close Microsoft Integration Runtime Configuration Manager.
Note
For more information about how to use the self-hosted integration runtime, see Create and configure a self-hosted integration runtime.
In Create Azure Database Migration Service in Azure Data Studio, select Test connection to validate that the newly created Database Migration Service instance is connected to the newly registered self-hosted integration runtime.
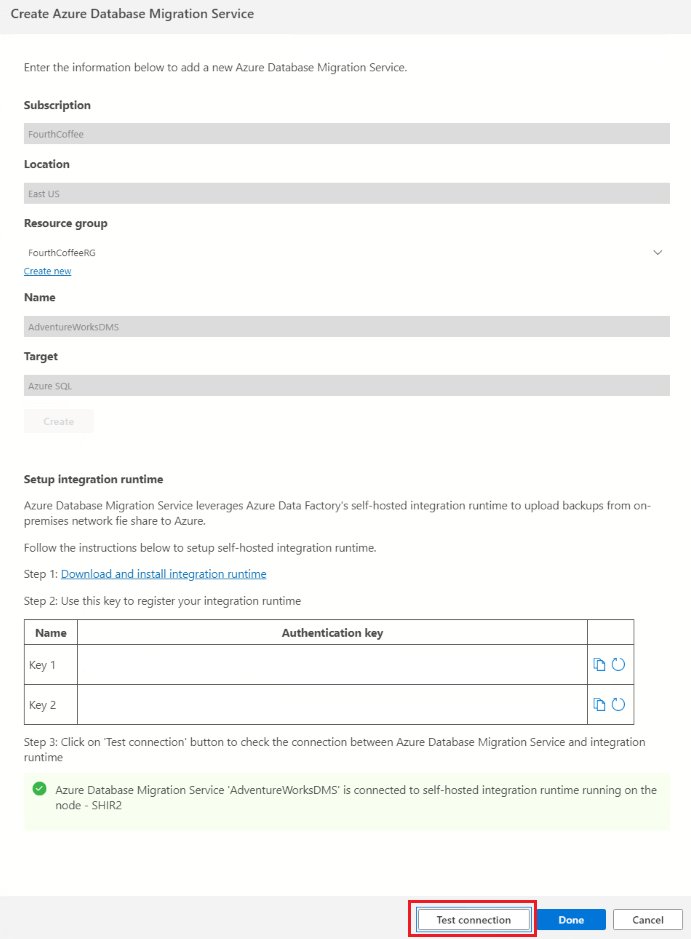
Return to the migration wizard in Azure Data Studio.
Start the database migration
Review the configuration you created, and then select Start migration to start the database migration.
Monitor the database migration
On the Database Migration Status, you can track the migrations in progress, migrations completed, and migrations failed (if any).
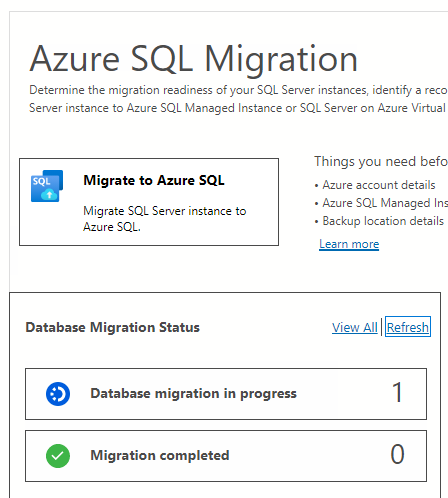
Select Database migrations in progress to view active migrations.
To get more information about a specific migration, select the database name.
The migration details pane displays the backup files and their corresponding status:
Status Description Arrived The backup file arrived in the source backup location and was validated. Uploading the integration runtime is uploading the backup file to the Azure storage account. Uploaded The backup file was uploaded to the Azure storage account. Restoring The service is restoring the backup file to Azure SQL Managed Instance. Restored The backup file is successfully restored in Azure SQL Managed Instance. Canceled The migration process was canceled. Ignored The backup file was ignored because it doesn't belong to a valid database backup chain. 

Complete migration cutover
The final step of the tutorial is to complete the migration cutover to ensure the migrated database in Azure SQL Managed Instance is ready for use. This process is the only part that requires downtime for applications that connect to the database and hence the timing of the cutover needs to be carefully planned with business or application stakeholders.
To complete the cutover:
- Stop all incoming transactions to the source database.
- Make application configuration changes to point to the target database in Azure SQL Managed Instance.
- Take a final log backup of the source database in the backup location specified
- Put the source database in read-only mode. Therefore, users can read data from the database but not modify it.
- Ensure all database backups have the status Restored in the monitoring details page.
- Select Complete cutover in the monitoring details page.
During the cutover process, the migration status changes from in progress to completing. When the cutover process is completed, the migration status changes to succeeded to indicate that the database migration is successful and that the migrated database is ready for use.
Important
After the cutover, availability of SQL Managed Instance with Business Critical service tier only can take significantly longer than General Purpose as three secondary replicas have to be seeded for Always On High Availability group. This operation duration depends on the size of data, for more information, see Management operations duration.
Limitations
Important
Online migrations with the Azure SQL extension use the same technology as the Log Replay Service (LRS), and have the same limitations. Before you migrate databases to the Business Critical service tier, consider these limitations, which don't apply to the General Purpose service tier.
Migrating to Azure SQL Managed Instance by using the Azure SQL extension for Azure Data Studio has the following limitations:
If you migrate a single database, the database backups must be placed in a flat-file structure inside a database folder (including the container root folder), and the folders can't be nested, as it isn't supported.
If you migrate multiple databases using the same Azure Blob Storage container, you must place backup files for different databases in separate folders inside the container.
Overwriting existing databases using DMS in your target Azure SQL Managed Instance isn't supported.
DMS doesn't support configuring high availability and disaster recovery on your target to match the source topology.
The following server objects aren't supported:
- SQL Server Agent jobs
- Credentials
- SSIS packages
- Server audit
You can't use an existing self-hosted integration runtime created from Azure Data Factory for database migrations with DMS. Initially, the self-hosted integration runtime should be created using the Azure SQL migration extension in Azure Data Studio and can be reused for further database migrations.
A single LRS job (created by DMS) can run for a maximum of 30 days. When this period expires, the job is automatically canceled thus your target database gets automatically deleted.
If you're migrating to a SQL Managed Instance in the Business Critical service tier, account for the delay in bringing the databases online on the primary replica while they're seeded to the secondary replicas. This is especially true for larger databases. If it's important that databases are available as soon as cutover completes, then consider the following workarounds:
Migrate to the General Purpose service tier first, and then upgrade to the Business Critical service tier. Upgrading your service tier is an online operation that keeps your databases online until a short failover as the final step of the upgrade operation.
Use the Managed Instance link for an online migration to a Business Critical instance without having to wait for databases to be available after the cutover.
If you received the following error:
Memory-optimized filegroup must be empty in order to be restored on General Purpose tier of SQL Database Managed Instance, this issue is by design. In-Memory OLTP isn't supported on the General Purpose tier of Azure SQL Managed Instance. To continue migration, one way is to upgrade to Business Critical tier, which supports In-Memory OLTP. Another way is to make sure the source database isn't using it while the Azure SQL Managed Instance is General Purpose.