Authoring speech experiences in Composer
APPLIES TO: Composer v1.x and v2.x
Bots are able to communicate over speech based channels, such as Direct Line Speech (enabling speech experiences in Web Chat), or via embedded devices.
Bots can use text-to-speech (also known as speech synthesis, and referred to as speech in this article) to convert text to human-like synthesized speech. Text is converted to a phonetic representation (the individual components of speech sounds) which are converted to waveforms that are output as speech. Composer uses Speech Synthesis Markup Language (SSML), an XML-based markup language that lets developers specify how input text is converted into synthesized speech. SSML gives developers the ability to customize different aspects of speech, like pitch, pronunciation, rate of speech, and more.
This modality lets developers create bots in Composer that can not only respond visually with text, but also audibly with speech. Bot developers and designers can create bots with various voices in different languages with the speech middleware and using SSML tags.
Add Speech components to your bot responses
It's important to ensure that bot responses are optimized for the channels that they'll be available on. For example, a welcome message written in text along with an Adaptive Card attachment won't be suitable when sent via a speech capable channel. For this reason, bot responses can contain both text and speech responses, with the speech response used by the channel when required.
Using the response editor, bot developers can easily add speech components to bots and customize them with SSML tags.
To add speech to a bot, complete the following steps:
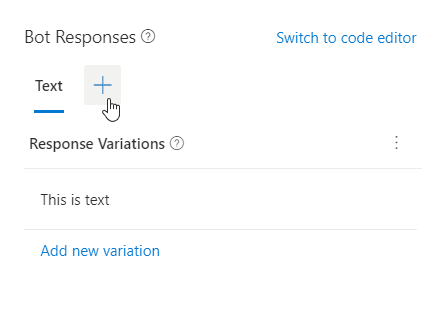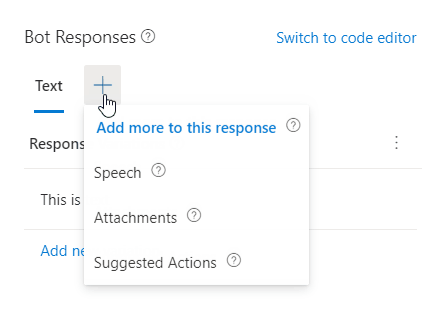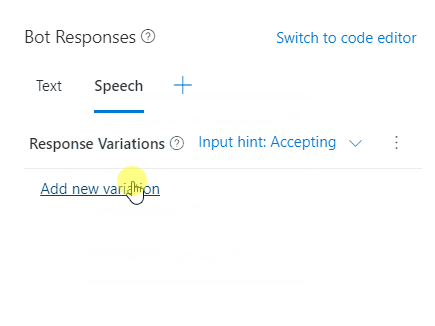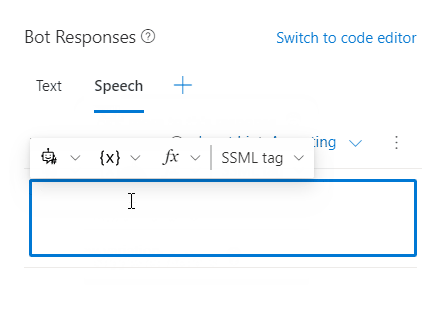
Open a bot project and add a Send a response action to one of your dialogs. Enter text in the Text box for a fallback text response.
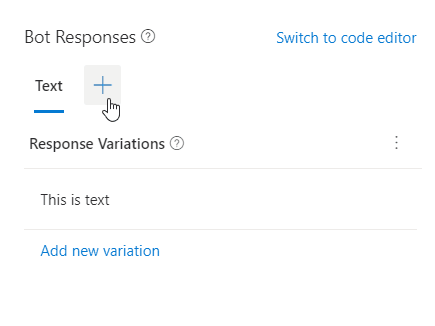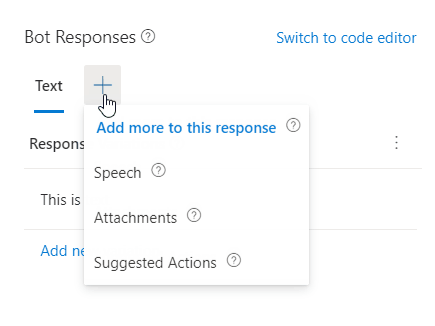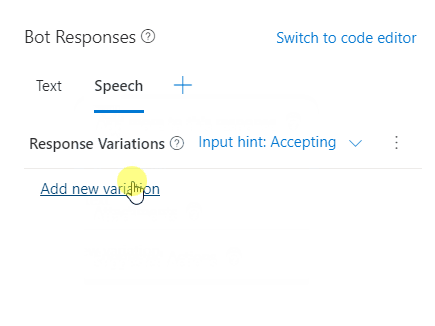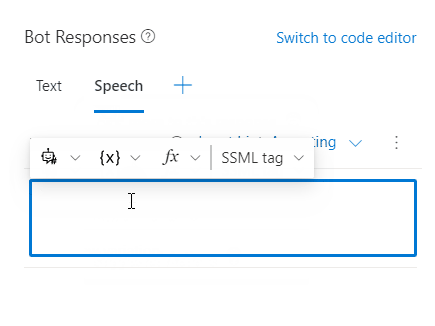
Now click the + next to Text. You'll see three options: Speech, Attachments, and Suggested Actions. Select Speech.
When speech is added, you'll see Input hint: accepting next to Response variations. Select Input hint: accepting to see all of the available input hints:
- Accepting: Indicates that your bot is passively ready for input but isn't awaiting a response from the user (this is the default value if no specific InputHint value is set).
- Ignoring: Indicates that your bot isn't ready to receive input from the user.
- Excepting: Indicates that your bot is actively awaiting a response from the user
For more information, see the Bot Framework SDK article Add input hints to messages with the Bot Connector API.
You can add SSML tags to your speech component to customize your speech output. Select SSML tag in the command bar to see the SSML tag options.
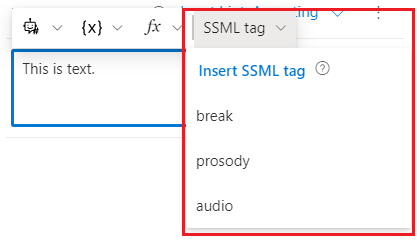
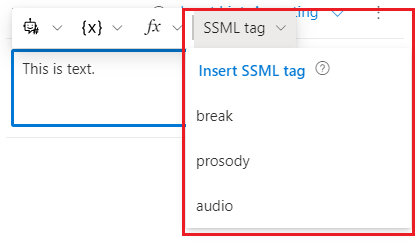
Composer supports the following SSML tags:
- break: Inserts pauses (or
breaks) between words, or prevent pauses automatically added by the text-to-speech service. - prosody: Specifies changes to pitch, contour, range, rate, duration, and volume for the text-to-speech output.
- audio: Allows you to insert MP3 audio into an SSML document.
For more information, see the Improve synthesis with Speech Synthesis Markup Language (SSML) article.
- break: Inserts pauses (or
Voice font and speech related bot settings
In order for speech responses to work correctly on some channels, including Direct Line Speech channels, there are some required SSML tags that must be present.
- Speak - required to enable use of SSML tags.
- Voice - defines the voice font that will be used when responses are read out as speech by the channel.
Tip
Visit the language and voice support for the Speech Service documentation to see a list of supported voice fonts. It's recommended that you use neural voice fonts, where available, as these sound particularly human-like.
Composer makes it as easy as possible for bot builders to develop speech applications, automatically including these SSML tags on all outgoing responses, with the ability to modify related properties in the Composer runtime settings.
To access the speech related settings, complete the following steps:
Open a Composer bot project and select Configure in the navigation pane
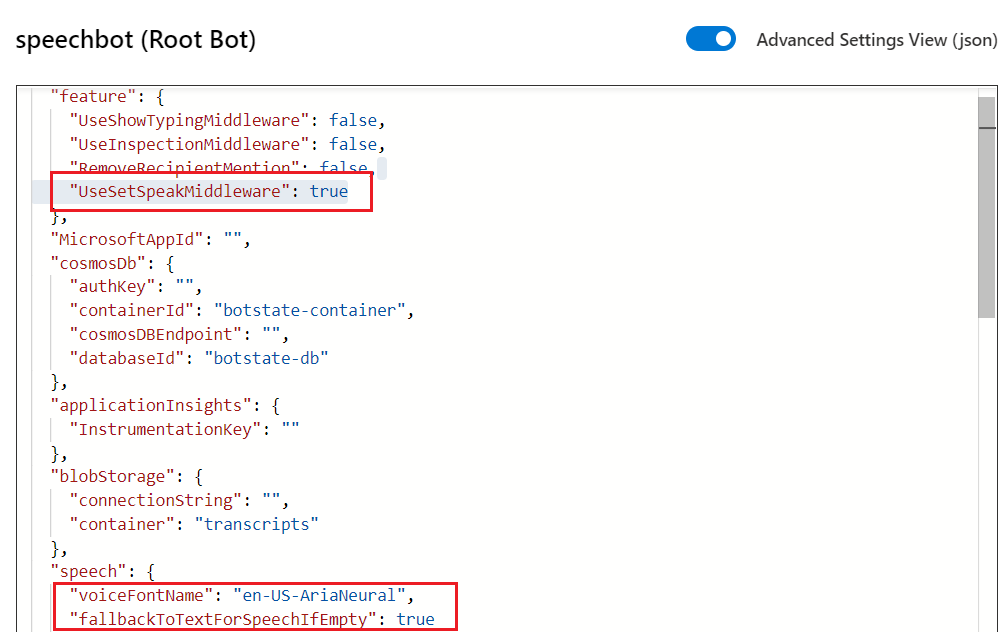
Select Advanced Settings View (json) to show the JSON view of the project settings. There are two relevant speech sections, shown below.
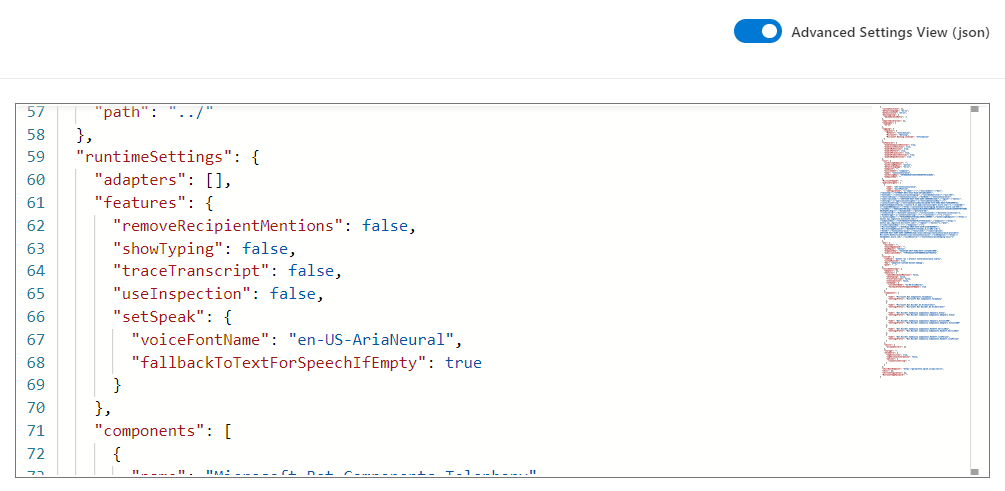
"voiceFontName": "en-US-AriaNeural": Determines thevoiceFontNameyour bot will use to speak, and the default isen-US-AriaNeural. You can customize this using any of the available voices and locales appropriate for your bot."fallbackToTextForSpeechIfEmpty": true: Determines whether text will be used if speech is empty, and thedefaultis true. If you don't add SSML tags to your speech, there will be silence, and instead the text will be displayed as a fallback message. To turn this off, set this tofalse.
Note
If you need to disable the speak or voice SSML tags being applied to all responses, you can do this by removing the setSpeak element from your bot settings completely. This will disable the related middleware within the runtime.
Connect to channels
Speech is supported by the Direct Line Speech channel within Azure Bot Service. For information about connecting a bot to channels that support voice, see Connect a bot to Direct Line Speech.
Test speech
To test speech capabilities in your bot, connect your bot to a speech enabled channel, such as Direct Line Speech, and use the channel's native communication method to test your bot, such as Web Chat.
To inspect the responses being sent by your bot, including speech specific responses containing the automatically added SSML tags, plus any that you've manually added, do the following.
- Go to a bot project and create a few activities that have text and speech.
- Start your bot and test it in the Emulator. You'll see SSML elements appear in the inspect activity JSON.