Use parallel jobs in pipelines
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
This article explains how to use the CLI v2 and Python SDK v2 to run parallel jobs in Azure Machine Learning pipelines. Parallel jobs accelerate job execution by distributing repeated tasks on powerful multinode compute clusters.
Machine learning engineers always have scale requirements on their training or inferencing tasks. For example, when a data scientist provides a single script to train a sales prediction model, machine learning engineers need to apply this training task to each individual data store. Challenges of this scale-out process include long execution times that cause delays, and unexpected issues that require manual intervention to keep the task running.
The core job of Azure Machine Learning parallelization is to split a single serial task into mini-batches and dispatch those mini-batches to multiple computes to execute in parallel. Parallel jobs significantly reduce end-to-end execution time and also handle errors automatically. Consider using Azure Machine Learning Parallel job to train many models on top of your partitioned data or to accelerate your large-scale batch inferencing tasks.
For example, in a scenario where you're running an object detection model on a large set of images, Azure Machine Learning parallel jobs let you easily distribute your images to run custom code in parallel on a specific compute cluster. Parallelization can significantly reduce time cost. Azure Machine Learning parallel jobs can also simplify and automate your process to make it more efficient.
Prerequisites
- Have an Azure Machine Learning account and workspace.
- Understand Azure Machine Learning pipelines.
- Install the Azure CLI and the
mlextension. For more information, see Install, set up, and use the CLI (v2). Themlextension automatically installs the first time you run anaz mlcommand. - Understand how to create and run Azure Machine Learning pipelines and components with the CLI v2.
Create and run a pipeline with a parallel job step
An Azure Machine Learning parallel job can be used only as a step in a pipeline job.
The following examples come from Run a pipeline job using parallel job in pipeline in the Azure Machine Learning examples repository.
Prepare for parallelization
This parallel job step requires preparation. You need an entry script that implements the predefined functions. You also need to set attributes in your parallel job definition that:
- Define and bind your input data.
- Set the data division method.
- Configure your compute resources.
- Call the entry script.
The following sections describe how to prepare the parallel job.
Declare the inputs and data division setting
A parallel job requires one major input to be split and processed in parallel. The major input data format can be either tabular data or a list of files.
Different data formats have different input types, input modes, and data division methods. The following table describes the options:
| Data format | Input type | Input mode | Data division method |
|---|---|---|---|
| File list | mltable or uri_folder |
ro_mount or download |
By size (number of files) or by partition |
| Tabular data | mltable |
direct |
By size (estimated physical size) or by partition |
Note
If you use tabular mltable as your major input data, you need to:
- Install the
mltablelibrary in your environment, as in line 9 of this conda file. - Have a MLTable specification file under your specified path with the
transformations: - read_delimited:section filled out. For examples, see Create and manage data assets.
You can declare your major input data with the input_data attribute in the parallel job YAML or Python, and bind the data with the defined input of your parallel job by using ${{inputs.<input name>}}. Then you define the data division attribute for your major input depending on your data division method.
| Data division method | Attribute name | Attribute type | Job example |
|---|---|---|---|
| By size | mini_batch_size |
string | Iris batch prediction |
| By partition | partition_keys |
list of strings | Orange juice sales prediction |
Configure the compute resources for parallelization
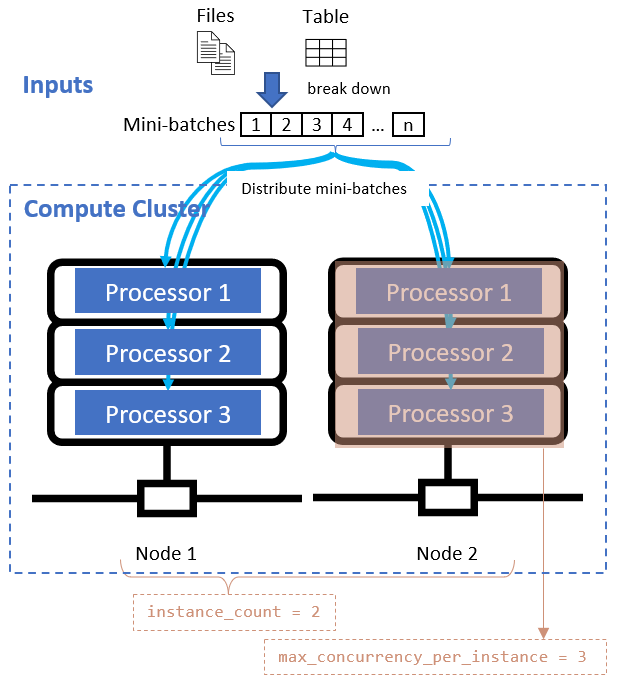
After you define the data division attribute, configure the compute resources for your parallelization by setting the instance_count and max_concurrency_per_instance attributes.
| Attribute name | Type | Description | Default value |
|---|---|---|---|
instance_count |
integer | The number of nodes to use for the job. | 1 |
max_concurrency_per_instance |
integer | The number of processors on each node. | For a GPU compute: 1. For a CPU compute: number of cores. |
These attributes work together with your specified compute cluster, as shown in the following diagram:
Call the entry script
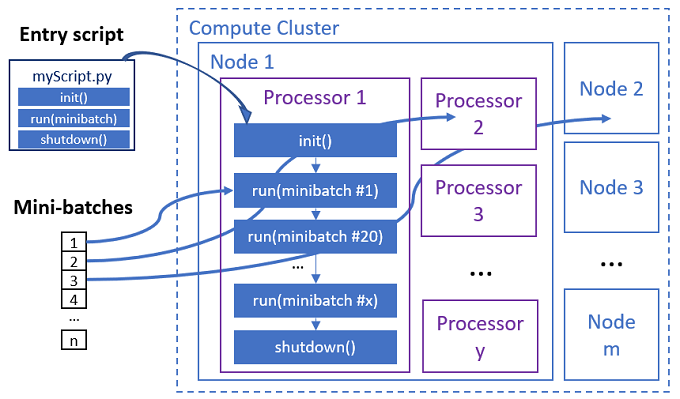
The entry script is a single Python file that implements the following three predefined functions with custom code.
| Function name | Required | Description | Input | Return |
|---|---|---|---|---|
Init() |
Y | Common preparation before starting to run mini-batches. For example, use this function to load the model into a global object. | -- | -- |
Run(mini_batch) |
Y | Implements main execution logic for mini-batches. | mini_batch is pandas dataframe if input data is a tabular data, or file path list if input data is a directory. |
Dataframe, list, or tuple. |
Shutdown() |
N | Optional function to do custom cleanups before returning the compute to the pool. | -- | -- |
Important
To avoid exceptions when parsing arguments in Init() or Run(mini_batch) functions, use parse_known_args instead of parse_args. See the iris_score example for an entry script with argument parser.
Important
The Run(mini_batch) function requires a return of either a dataframe, list, or tuple item. The parallel job uses the count of that return to measure the success items under that mini-batch. Mini-batch count should be equal to the return list count if all items have processed.
The parallel job executes the functions in each processor, as shown in the following diagram.
See the following entry script examples:
To call the entry script, set the following two attributes in your parallel job definition:
| Attribute name | Type | Description |
|---|---|---|
code |
string | Local path to the source code directory to upload and use for the job. |
entry_script |
string | The Python file that contains the implementation of predefined parallel functions. |
Parallel job step example
The following parallel job step declares the input type, mode, and data division method, binds the input, configures the compute, and calls the entry script.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Consider automation settings
Azure Machine Learning parallel job exposes many optional settings that can automatically control the job without manual intervention. The following table describes these settings.
| Key | Type | Description | Allowed values | Default value | Set in attribute or program argument |
|---|---|---|---|---|---|
mini_batch_error_threshold |
integer | Number of failed mini-batches to ignore in this parallel job. If the count of failed mini-batches is higher than this threshold, the parallel job is marked as failed. The mini-batch is marked as failed if: - The count of return from run() is less than the mini-batch input count.- Exceptions are caught in custom run() code. |
[-1, int.max] |
-1, meaning ignore all failed mini-batches |
Attribute mini_batch_error_threshold |
mini_batch_max_retries |
integer | Number of retries when the mini-batch fails or times out. If all retries fail, the mini-batch is marked as failed per the mini_batch_error_threshold calculation. |
[0, int.max] |
2 |
Attribute retry_settings.max_retries |
mini_batch_timeout |
integer | Timeout in seconds for executing the custom run() function. If execution time is higher than this threshold, the mini-batch is aborted and marked as failed to trigger retry. |
(0, 259200] |
60 |
Attribute retry_settings.timeout |
item_error_threshold |
integer | The threshold of failed items. Failed items are counted by the number gap between inputs and returns from each mini-batch. If the sum of failed items is higher than this threshold, the parallel job is marked as failed. | [-1, int.max] |
-1, meaning ignore all failures during parallel job |
Program argument--error_threshold |
allowed_failed_percent |
integer | Similar to mini_batch_error_threshold, but uses the percent of failed mini-batches instead of the count. |
[0, 100] |
100 |
Program argument--allowed_failed_percent |
overhead_timeout |
integer | Timeout in seconds for initialization of each mini-batch. For example, load mini-batch data and pass it to the run() function. |
(0, 259200] |
600 |
Program argument--task_overhead_timeout |
progress_update_timeout |
integer | Timeout in seconds for monitoring the progress of mini-batch execution. If no progress updates are received within this timeout setting, the parallel job is marked as failed. | (0, 259200] |
Dynamically calculated by other settings | Program argument--progress_update_timeout |
first_task_creation_timeout |
integer | Timeout in seconds for monitoring the time between the job start and the run of the first mini-batch. | (0, 259200] |
600 |
Program argument--first_task_creation_timeout |
logging_level |
string | The level of logs to dump to user log files. | INFO, WARNING, or DEBUG |
INFO |
Attribute logging_level |
append_row_to |
string | Aggregate all returns from each run of the mini-batch and output it into this file. May refer to one of the outputs of the parallel job by using the expression ${{outputs.<output_name>}} |
Attribute task.append_row_to |
||
copy_logs_to_parent |
string | Boolean option whether to copy the job progress, overview, and logs to the parent pipeline job. | True or False |
False |
Program argument--copy_logs_to_parent |
resource_monitor_interval |
integer | Time interval in seconds to dump node resource usage (for example cpu or memory) to log folder under the logs/sys/perf path. Note: Frequent dump resource logs slightly slow execution speed. Set this value to 0 to stop dumping resource usage. |
[0, int.max] |
600 |
Program argument--resource_monitor_interval |
The following sample code updates these settings:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Create the pipeline with parallel job step
The following example shows the complete pipeline job with the parallel job step inline:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Submit the pipeline job
Submit your pipeline job with parallel step by using the az ml job create CLI command:
az ml job create --file pipeline.yml
Check parallel step in studio UI
After you submit a pipeline job, the SDK or CLI widget gives you a web URL link to the pipeline graph in the Azure Machine Learning studio UI.
To view parallel job results, double-click the parallel step in the pipeline graph, select the Settings tab in the details panel, expand Run settings, and then expand the Parallel section.

To debug parallel job failure, select the Outputs + logs tab, expand the logs folder, and check job_result.txt to understand why the parallel job failed. For information about the logging structure of parallel jobs, see readme.txt in the same folder.
