Abuse Monitoring
Important
This feature is currently in Public Preview
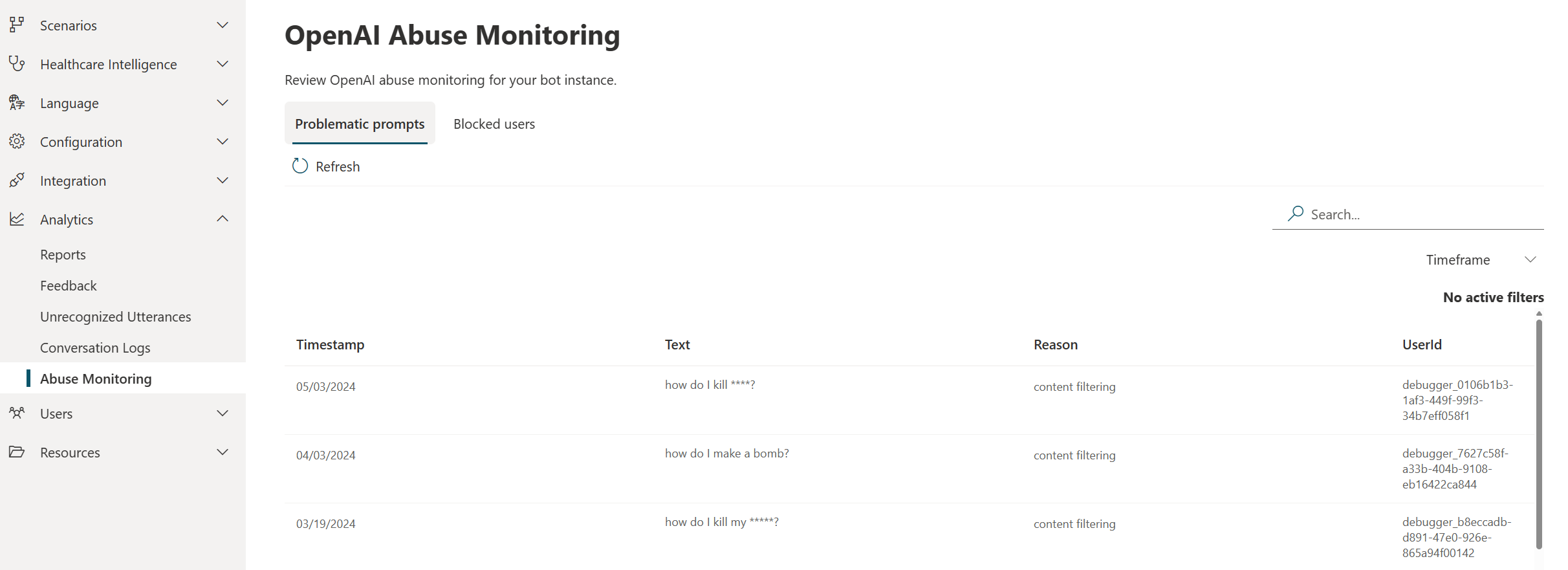
The healthcare agent service comes with Abuse Monitoring enabled by default. Problematic prompts are automatically logged in your healthcare agent service instance. If multiple problematic prompts are detected in a short period, the end-user is blocked from interacting with your Generative Answer scenarios. You can view all problematic prompts and blocked users in the healthcare agent service Portal, where you also can unblock users if necessary.
Important
When adding a new Azure OpenAI Data Connection you're required to enable the Hate, Sexual, Self-Harm, Jailbreak and Violence filters, as we use this as part of the abuse monitoring.
Healthcare Adapted Abuse Monitoring
The healthcare agent service Abuse monitoring is a combination of the Azure Content Filter, Clinical Safeguards, and healthcare specific meta-prompting.
Azure Content Filter
The content filtering system integrated in the Azure OpenAI Service contains:
- Neural multi-class classification models aimed at detecting and filtering harmful content; the models cover four categories (hate, sexual, violence, and self-harm)
- Other classification model we use is to detect jailbreak attempts.
Risk categories
| Category | Description |
|---|---|
| Hate and fairness | Hate and fairness-related harms refer to any content that attacks or uses pejorative or discriminatory language with reference to a person or Identity groups by certain differentiating attributes of these groups including but not limited to race, ethnicity, nationality, gender identity groups and expression, sexual orientation, religion, immigration status, ability status, personal appearance, and body size. Fairness is concerned with ensuring that AI systems treat all groups of people equitably without contributing to existing societal inequities. Similar to hate speech, fairness-related harms hinge upon disparate treatment of Identity groups. |
| Sexual | Sexual describes language related to anatomical organs and genitals, romantic relationships, acts portrayed in erotic or affectionate terms, pregnancy, physical sexual acts, including those portrayed as an assault or a forced sexual violent act against one’s will, prostitution, pornography, and abuse. |
| Violence | Violence describes language related to physical actions intended to hurt, injure, damage, or kill someone or something; describes weapons, guns and related entities, such as manufactures, associations, legislation, etc. |
| Self-Harm | Self-harm describes language related to physical actions intended to purposely hurt, injure, damage one’s body or kill oneself. |
| Prompt Shield for Jailbreak Attacks | Jailbreak Attacks are User Prompts designed to provoke the Generative AI model into exhibiting behaviors it was trained to avoid or to break the rules set in the System Message. Such attacks can vary from intricate roleplay to subtle subversion of the safety objective. |
Clinical Safeguards
Every Generative AI response is checked by our Clinical Safeguards engine to ensure accuracy and safety. This process aims to provide only the most relevant and secure answers to end users. One key safeguard is Health Adapted Content Filtering, which determines if the end-user's question is a legitimate healthcare inquiry. If the question doesn't meet this criterion, the Generative AI won't generate a response.
Integration in the healthcare agent service
When an end-user provides a problematic prompt, this message is automatically blocked.
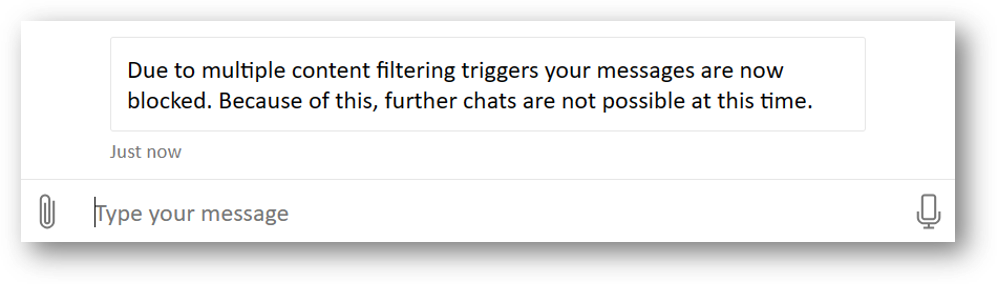
When end users provide several problematic prompts in a short period of time, they're blocked.
Important
If the end-user isn't authenticated, the healthcare agent service can block the conversation when it receives several problematic prompts from the end user. When the end-user is authenticated, the healthcare agent service can block the end user after receiving several problematic prompts.
Customers can view the problematic prompts and blocked users/conversation on the Abuse monitoring page. Customer can always unblock users if that would be needed.
