How to build simple, efficient, and low-latency data pipelines
Today’s data-driven businesses continuously produce data, which necessitates engineering data pipelines that continuously ingest and transform this data. These pipelines should be able to process and deliver data exactly-once, produce results with latencies less than 200 milliseconds, and always try to minimize costs.
This article describes batch and incremental stream processing approaches for engineering data pipelines, why incremental stream processing is the better option, and next steps for getting started with Databricks incremental stream processing offerings, Streaming on Azure Databricks and What is Delta Live Tables?. These features allow you to quickly write and run pipelines that guarantee delivery semantics, latency, cost, and more.
The pitfalls of repeated batch jobs
When setting up your data pipeline, you may at first write repeated batch jobs to ingest your data. For example, every hour you could run a Spark job that reads from your source and writes data into a sink like Delta Lake. The challenge with this approach is incrementally processing your source, because the Spark job that runs every hour needs to begin where the last one ended. You can record the latest timestamp of the data you processed, and then select all rows with timestamps more recent than that timestamp, but there are pitfalls:
To run a continuous data pipeline, you might try to schedule an hourly batch job that incrementally reads from your source, does transformations, and writes the result to a sink, such as Delta Lake. This approach can have pitfalls:
- A Spark job that queries for all new data after a timestamp will miss late data.
- A Spark job that fails can lead to breaking exactly-once guarantees, if not handled carefully.
- A Spark job that lists the contents of cloud storage locations to find new files will become expensive.
You then still need to repeatedly transform this data. You might write repeated batch jobs that then aggregate your data or apply other operations, which further complicates and reduces efficiency of the pipeline.
A batch example
To fully understand the pitfalls of batch ingestion and transformation for your pipeline, consider the following examples.
Missed data
Given a Kafka topic with usage data that determines how much to charge your customers, and your pipeline is ingesting in batches, the sequence of events may look like this:
- Your first batch has two records at 8am and 8:30am.
- You update the latest timestamp to 8:30am.
- You get another record at 8:15am.
- Your second batch queries for everything after 8:30am, so you miss the record at 8:15am.
In addition, you don’t want to overcharge or undercharge your users so you must ensure you are ingesting every record exactly once.
Redundant processing
Next, suppose your data contains rows of user purchases and you want to aggregate the sales per hour so that you know the most popular times in your store. If purchases for the same hour arrive in different batches, then you will have multiple batches that produce outputs for the same hour:
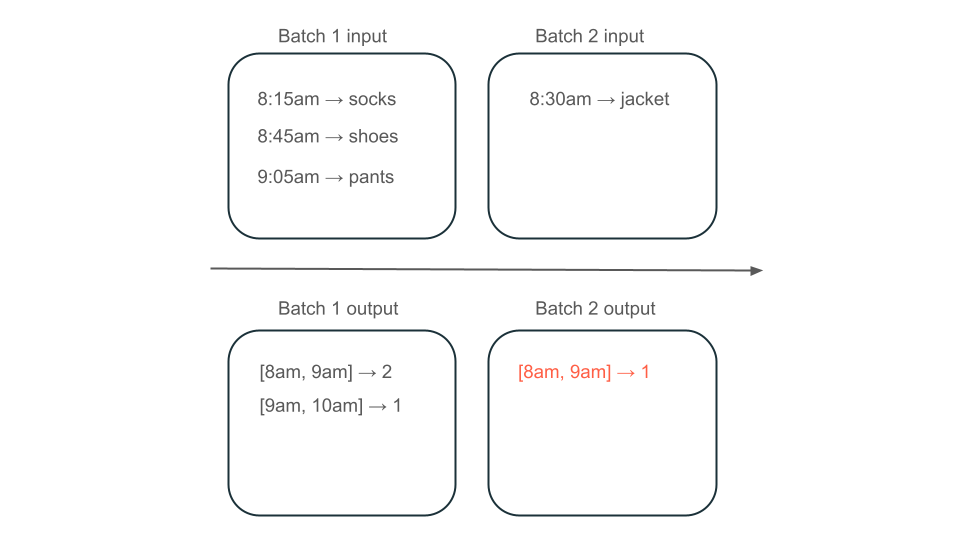
Does the 8am to 9am window have two elements (the output of batch 1), one element (the output of batch 2), or three (the output of none of the batches)? The data required to produce a given window of time appears across multiple batches of transformation. To resolve this, you might partition your data by day and reprocess the entire partition when you need to compute a result. Then, you can overwrite the results in your sink:
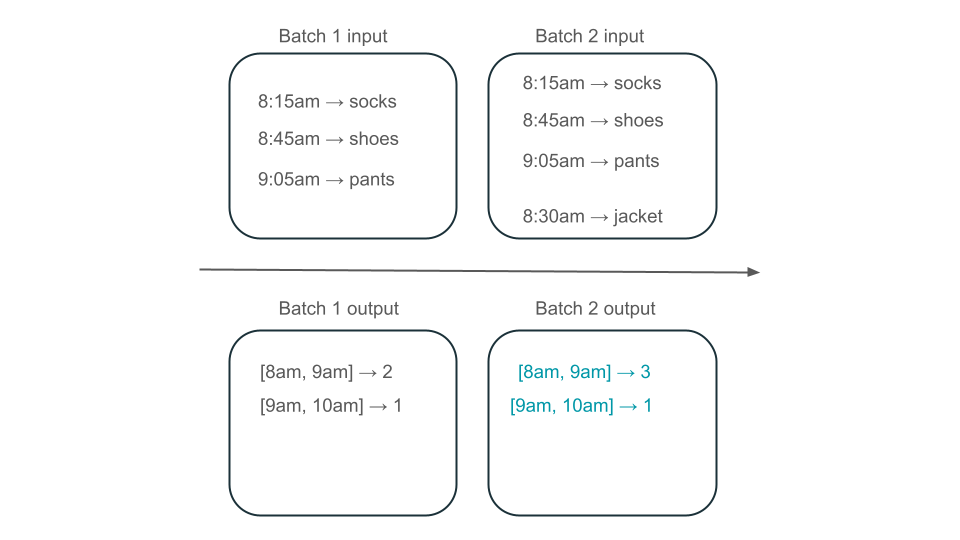
However, this comes at the expense of latency and cost, because the second batch needs to do the unnecessary work of processing data that it may have already processed.
No pitfalls with incremental stream processing
Incremental stream processing makes it easy to avoid all of the pitfalls of repeated batch jobs to ingest and transform data. Databricks Structured Streaming and Delta Live Tables manage implementation complexities of streaming to allow you to focus on just your business logic. You only need to specify what source to connect to, what transformations should be done to the data, and where to write the result.
Incremental ingestion
Incremental ingestion in Databricks is powered by Apache Spark Structured Streaming, which can incrementally consume a source of data and write it to a sink. The Structured Streaming engine can consume data exactly once, and the engine can handle out-of-order data. The engine can be run either in notebooks, or using streaming tables in Delta Live Tables.
The Structured Streaming engine on Databricks provides proprietary streaming sources such as AutoLoader, which can incrementally process cloud files in a cost-effective way. Databricks also provides connectors for other popular message buses like Apache Kafka, Amazon Kinesis, Apache Pulsar, and Google Pub/Sub.
Incremental transformation
Incremental transformation in Databricks with Structured Streaming allows you to specify transformations to DataFrames with the same API as a batch query, but it tracks data across batches and aggregated values over time so that you don’t have to. It never has to reprocess data, so it is faster and more cost effective than repeated batch jobs. Structured Streaming produces a stream of data that it can append to your sink, like Delta Lake, Kafka, or any other supported connector.
Materialized Views in Delta Live Tables is powered by the Enzyme engine. Enzyme still incrementally processes your source, but instead of producing a stream, it creates a materialized view, which is a pre-computed table that stores the results of a query you give it. Enzyme is able to efficiently determine how new data affects the results of your query, and it keeps the pre-computed table up-to-date.
Materialized Views create a view over your aggregate that is always efficiently updating itself so that, for example, in the scenario described above, you know that the 8am to 9am window has three elements.
Structured Streaming or Delta Live Tables?
The significant difference between Structured Streaming and Delta Live Tables is the way in which you operationalize your streaming queries. In Structured Streaming, you manually specify many configurations, and you have to manually stitch queries together. You must explicitly start queries, wait for them to terminate, cancel them upon failure, and other actions. In Delta Live Tables, you declaratively give Delta Live Tables your pipelines to run, and it keeps them running.
Delta Live Tables also has features such as Materialized Views, which efficiently and incrementally precompute transformations of your data.
For more information on these features, see Streaming on Azure Databricks and What is Delta Live Tables?.
Next steps
Create your first pipeline with Delta Live Tables. See Tutorial: Run your first Delta Live Tables pipeline.
Run your first Structured Streaming queries on Databricks. See Run your first Structured Streaming workload.
Use a materialied view. See Use materialized views in Databricks SQL.