Use online tables for real-time feature serving
Important
Online tables are in Public Preview in the following regions: westus, eastus, eastus2, northeurope, westeurope. For pricing information, see Online Tables pricing.
An online table is a read-only copy of a Delta Table that is stored in row-oriented format optimized for online access. Online tables are fully serverless tables that auto-scale throughput capacity with the request load and provide low latency and high throughput access to data of any scale. Online tables are designed to work with Mosaic AI Model Serving, Feature Serving, and retrieval-augmented generation (RAG) applications where they are used for fast data lookups.
You can also use online tables in queries using Lakehouse Federation. When using Lakehouse Federation, you must use a Serverless SQL warehouse to access online tables. Only read operations (SELECT) are supported. This capability is intended for interactive or debugging purposes only and should not be used for production or mission critical workloads.
Creating an online table using the Databricks UI is a one-step process. Just select the Delta table in Catalog Explorer and select Create online table. You can also use the REST API or the Databricks SDK to create and manage online tables. See Work with online tables using APIs.
Requirements
- The workspace must be enabled for Unity Catalog. Follow the documentation to create a Unity Catalog Metastore, enable it in a workspace, and create a Catalog.
- A model must be registered in Unity Catalog to access online tables.
Work with online tables using the UI
This section describes how to create and delete online tables, and how to check the status and trigger updates of online tables.
Create an online table using the UI
You create an online table using Catalog Explorer. For information about required permissions, see User permissions.
To create an online table, the source Delta table must have a primary key. If the Delta table you want to use does not have a primary key, create one by following these instructions: Use an existing Delta table in Unity Catalog as a feature table.
In Catalog Explorer, navigate to the source table that you want to sync to an online table. From the Create menu, select Online table.
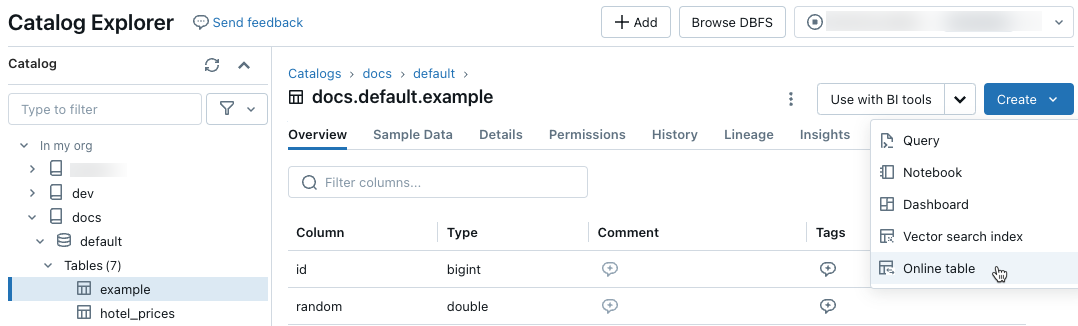
Use the selectors in the dialog to configure the online table.
Name: Name to use for the online table in Unity Catalog.
Primary Key: Column(s) in the source table to use as primary key(s) in the online table.
Timeseries Key: (Optional). Column in the source table to use as timeseries key. When specified, the online table includes only the row with the latest timeseries key value for each primary key.
Sync mode: Specifies how the synchronization pipeline updates the online table. Select one of Snapshot, Triggered, or Continuous.
Policy Description Snapshot The pipeline runs once to take a snapshot of the source table and copy it to the online table. Subsequent changes to the source table are automatically reflected in the online table by taking a new snapshot of the source and creating a new copy. The content of the online table is updated atomically. Triggered The pipeline runs once to create an initial snapshot copy of the source table in the online table. Unlike the Snapshot sync mode, when the online table is refreshed, only changes since the last pipeline execution are retrieved and applied to the online table. The incremental refresh can be manually triggered or automatically triggered according to a schedule. Continuous The pipeline runs continuously. Subsequent changes to the source table are incrementally applied to the online table in real time streaming mode. No manual refresh is necessary.
Note
To support Triggered or Continuous sync mode, the source table must have Change data feed enabled.
- When you are done, click Confirm. The online table page appears.
- The new online table is created under the catalog, schema, and name specified in the creation dialog. In Catalog Explorer, the online table is indicated by
 .
.
Get status and trigger updates using the UI
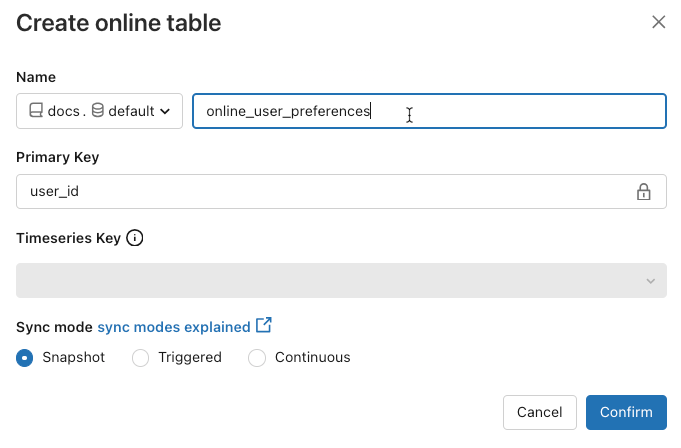
To check the status of the online table, click the name of the table in the Catalog to open it. The online table page appears with the Overview tab open. The Data Ingest section shows the status of the latest update. To trigger an update, click Sync now. The Data Ingest section also includes a link to the DLT pipeline that updates the table.
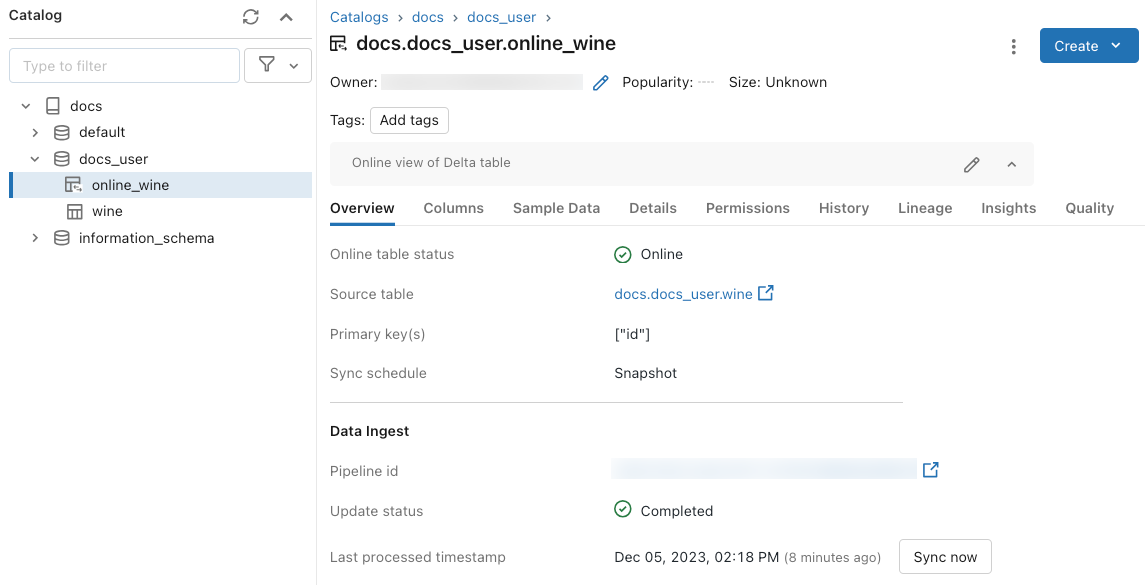
Schedule periodic updates
For online tables with Snapshot or Triggered sync mode, you can schedule automatic periodic updates. The update schedule is managed by the DLT pipeline that updates the table.
- In Catalog Explorer, navigate to the online table.
- In the Data Ingest section, click the link to the pipeline.
- In the upper-right corner, click Schedule, and add a new schedule or update existing schedules.
Delete an online table using the UI
From the online table page, select Delete from the ![]() kebab menu.
kebab menu.
Work with online tables using APIs
You can also use the Databricks SDK or the REST API to create and manage online tables.
For reference information, see the reference documentation for the Databricks SDK for Python or the REST API.
Requirements
Databricks SDK version 0.20 or above.
Create an online table using APIs
Databricks SDK - Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
REST API
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
The online table automatically starts syncing after it is created.
Get status and trigger refresh using APIs
You can view the status and the spec of the online table following the example below. If your online table is not continuous and you would like to trigger a manual refresh of its data, you can use the pipeline API to do so.
Use the pipeline ID associated with the online table in the online table spec and start a new update on the pipeline to trigger the refresh. This is equivalent to clicking Sync now in the online table UI in Catalog Explorer.
Databricks SDK - Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'DLT: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
REST API
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in DLT: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
Delete an online table using APIs
Databricks SDK - Python
w.online_tables.delete('main.default.my_online_table')
REST API
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
Deleting the online table stops any ongoing data synchronization and releases all its resources.
Serve online table data using a feature serving endpoint
For models and applications hosted outside of Databricks, you can create a feature serving endpoint to serve features from online tables. The endpoint makes features available at low latency using a REST API.
Create a feature spec.
When you create a feature spec, you specify the source Delta table. This allows the feature spec to be used in both offline and online scenarios. For online lookups, the serving endpoint automatically uses the online table to perform low-latency feature lookups.
The source Delta table and the online table must use the same primary key.
The feature spec can be viewed in the Function tab in Catalog Explorer.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )Create a feature serving endpoint.
This step assumes that you have created an online table named
user_preferences_online_tablethat synchonizes data from the Delta tableuser_preferences. Use the feature spec to create a feature serving endpoint. The endpoint makes data available through a REST API using the associated online table.Note
The user who performs this operation must be the owner of both the offline table and online table.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )Python API
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )Get data from the feature serving endpoint.
To access the API endpoint, send an HTTP GET request to the endpoint URL. The example shows how to do this using Python APIs. For other languages and tools, see Feature Serving.
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
Use online tables with RAG applications
RAG applications are a common use case for online tables. You create an online table for the structured data that the RAG application needs and host it on a feature serving endpoint. The RAG application uses the feature serving endpoint to look up relevant data from the online table.
The typical steps are as follows:
- Create a feature serving endpoint.
- Create a tool using LangChain or any similar package that uses the endpoint to look up relevant data.
- Use the tool in a LangChain agent or similar agent to retrieve relevant data.
- Create a model serving endpoint to host the application.
For step-by-step instructions and an example notebook, see Feature engineering example: structured RAG application.
Notebook examples
The following notebook illustrates how to publish features to online tables for real-time serving and automated feature lookup.
Online tables demo notebook
Use online tables with Mosaic AI Model Serving
You can use online tables to look up features for Mosaic AI Model Serving. When you sync a feature table to an online table, models trained using features from that feature table automatically look up feature values from the online table during inference. No additional configuration is required.
Use a
FeatureLookupto train the model.For model training, use features from the offline feature table in the model training set, as shown in the following example:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Serve the model with Mosaic AI Model Serving. The model automatically looks up features from the online table. See Automatic feature lookup with Databricks Model Serving for details.
User permissions
You must have the following permissions to create an online table:
SELECTprivilege on the source table.USE_CATALOGprivilege on the destination catalog.USE_SCHEMAandCREATE_TABLEprivilege on the destination schema.
To manage the data synchronization pipeline of an online table, you must either be the owner of the online table or be granted the REFRESH privilege on the online table. Users who do not have USE_CATALOG and USE_SCHEMA privileges on the catalog will not see the online table in Catalog Explorer.
The Unity Catalog metastore must have Privilege Model Version 1.0.
Endpoint permission model
A unique service principal is automatically created for a feature serving or model serving endpoint with limited permissions required to query data from online tables. This service principal allows endpoints to access data independently of the user who created the resource and ensures that the endpoint can continue to function if the creator leaves the workspace.
The lifetime of this service principal is the lifetime of the endpoint. Audit logs may indicate system generated records for the owner of the Unity Catalog catalog granting necessary privileges to this service principal.
Limitations
- Only one online table is supported per source table.
- An online table and its source table can have at most 1000 columns.
- Columns of data types ARRAY, MAP, or STRUCT cannot be used as primary keys in the online table.
- If a column is used as a primary key in the online table, all rows in the source table where the column contains null values are ignored.
- Foreign, system, and internal tables are not supported as source tables.
- Source tables without Delta change data feed enabled support only the Snapshot sync mode.
- Delta Sharing tables are only supported in the Snapshot sync mode.
- Catalog, schema, and table names of the online table can only contain alphanumeric characters and underscores, and must not start with numbers. Dashes (
-) are not allowed. - Columns of String type are limited to 64KB length.
- Column names are limited to 64 characters in length.
- The maximum size of the row is 2MB.
- The combined size of all online tables in a Unity Catalog metastore during public preview is 2TB uncompressed user data.
- The maximum queries per second (QPS) is 12,000. Reach out to your Databricks account team to increase the limit.
Troubleshooting
I don’t see the Create online table option
The cause is usually that the table you are trying to sync from (the source table) is not a supported type. Make sure the source table’s Securable Kind (shown in the Catalog Explorer Details tab) is one of the supported options below:
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
I can’t select either Triggered or Continuous sync modes when I create an online table
This happens if the source table does not have Delta change data feed enabled or if it is a View or materialized view. To use the Incremental sync mode, either enable change data feed on the source table, or use a non-view table.
Online table update fails or status shows offline
To begin troubleshooting this error, click the pipeline id that appears in the Overview tab of the online table in Catalog Explorer.
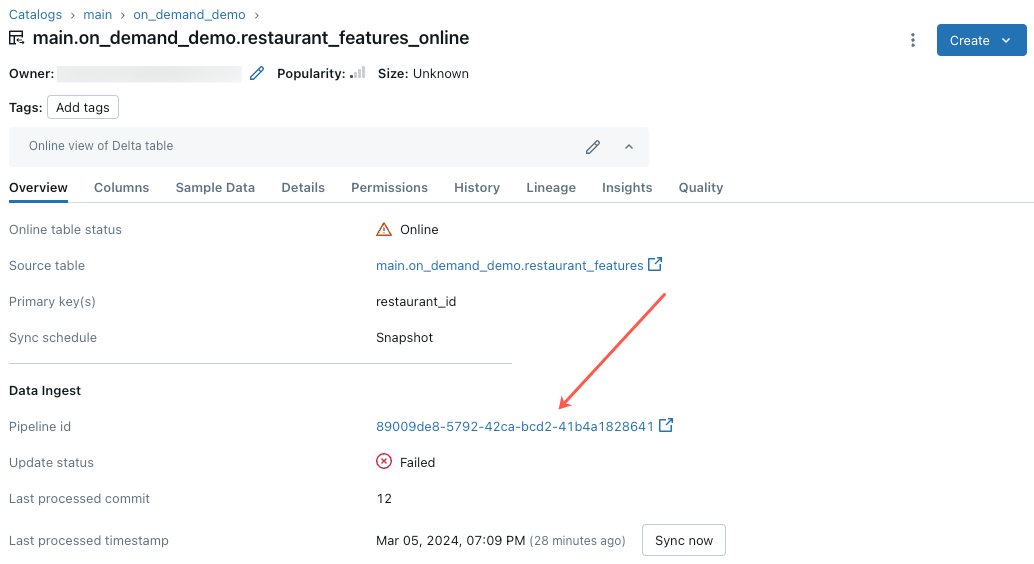
On the pipeline UI page that appears, click on the entry that says “Failed to resolve flow ‘__online_table”.
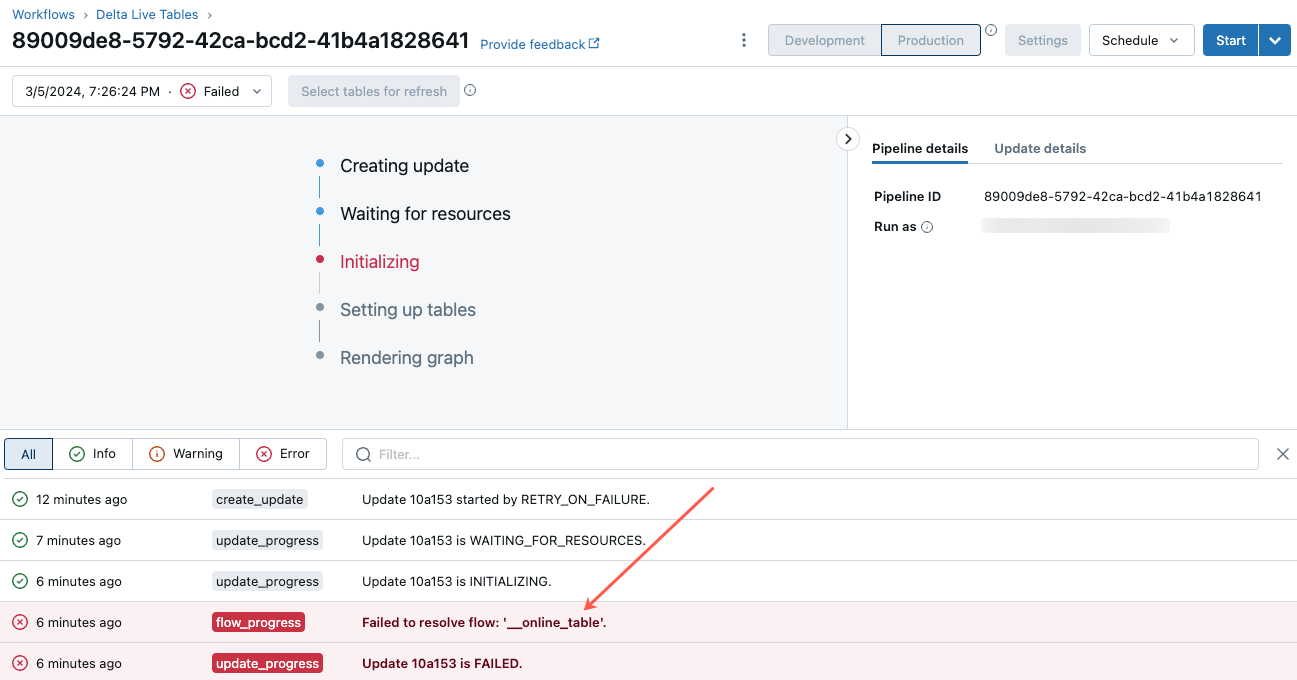
A popup appears with details in the Error details section.
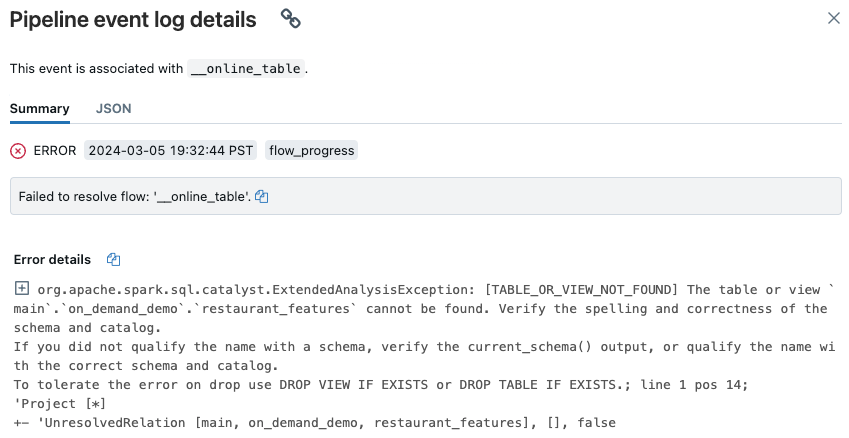
Common causes of errors include the following:
The source table was deleted, or deleted and recreated with the same name, while the online table was synchronizing. This is particularly common with continuous online tables, because they are constantly synchronizing.
The source table cannot be accessed through Serverless Compute due to firewall settings. In this situation, the Error details section might show the error message “Failed to start the DLT service on cluster xxx…”.
The aggregate size of online tables exceeds the 2 TB (uncompressed size) metastore-wide limit. The 2 TB limit refers to the uncompressed size after expanding the Delta table in row-oriented format. The size of the table in row-format can be significantly larger than the size of the Delta table shown in Catalog Explorer, which refers to the compressed size of the table in a column-oriented format. The difference can be as large as 100x, depending on the content of the table.
To estimate the uncompressed, row-expanded size of a Delta table, use the following query from a Serverless SQL Warehouse. The query returns the estimated expanded table size in bytes. Succesfully executing this query also confirms that Serverless Compute can access the source table.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;