Create a training run using the Foundation Model Fine-tuning API
Important
This feature is in Public Preview in the following regions: centralus, eastus, eastus2, northcentralus, and westus.
This article describes how to create and configure a training run using the Foundation Model Fine-tuning (now part of Mosaic AI Model Training) API, and describes all of the parameters used in the API call. You can also create a run using the UI. For instructions, see Create a training run using the Foundation Model Fine-tuning UI.
Requirements
Create a training run
To create training runs programmatically, use the create() function. This function trains a model on the provided dataset and converts the final Composer checkpoint to a Hugging Face formatted checkpoint for inference.
The required inputs are the model you want to train, the location of your training dataset, and where to register your model. There are also optional parameters that allow you to perform evaluation and change the hyperparameters of your run.
After the run completes, the completed run and final checkpoint are saved, the model is cloned, and that clone is registered to Unity Catalog as a model version for inference.
The model from the completed run, not the cloned model version in Unity Catalog, and its Composer and Hugging Face checkpoints are saved to MLflow. The Composer checkpoints can be used for continued fine-tuning tasks.
See Configure a training run for details about arguments for the create() function.
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-3.2-3B-Instruct',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Configure a training run
The following table summarizes the parameters for the foundation_model.create() function.
| Parameter | Required | Type | Description |
|---|---|---|---|
model |
x | str | The name of the model to use. See Supported models. |
train_data_path |
x | str | The location of your training data. This can be a location in Unity Catalog (<catalog>.<schema>.<table> or dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl), or a HuggingFace dataset.For INSTRUCTION_FINETUNE, the data should be formatted with each row containing a prompt and response field.For CONTINUED_PRETRAIN, this is a folder of .txt files. See Prepare data for Foundation Model Fine-tuning for accepted data formats and Recommended data size for model training for data size recommendations. |
register_to |
x | str | The Unity Catalog catalog and schema (<catalog>.<schema> or <catalog>.<schema>.<custom-name>) where the model is registered after training for easy deployment. If custom-name is not provided, this defaults to the run name. |
data_prep_cluster_id |
str | The cluster ID of the cluster to use for Spark data processing. This is required for instruction training tasks where the training data is in a Delta table. For information on how to find the cluster ID, see Get cluster ID. | |
experiment_path |
str | The path to the MLflow experiment where the training run output (metrics and checkpoints) is saved. Defaults to the run name within the user’s personal workspace (i.e. /Users/<username>/<run_name>). |
|
task_type |
str | The type of task to run. Can be CHAT_COMPLETION (default), CONTINUED_PRETRAIN, or INSTRUCTION_FINETUNE. |
|
eval_data_path |
str | The remote location of your evaluation data (if any). Must follow the same format as train_data_path. |
|
eval_prompts |
List[str] | A list of prompt strings to generate responses during evaluation. Default is None (do not generate prompts). Results are logged to the experiment every time the model is checkpointed. Generations occur at every model checkpoint with the following generation parameters: max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
str | The remote location of a custom model checkpoint for training. Default is None, meaning the run starts from the original pretrained weights of the chosen model. If custom weights are provided, these weights are used instead of the original pretrained weights of the model. These weights must be a Composer checkpoint and must match the architecture of the model specified. See Build on custom model weights |
|
training_duration |
str | The total duration of your run. Default is one epoch or 1ep. Can be specified in epochs (10ep) or tokens (1000000tok). |
|
learning_rate |
str | The learning rate for model training. For all models other than Llama 3.1 405B Instruct, the default learning rate is 5e-7. For Llama 3.1 405B Instruct, the default learning rate is 1.0e-5. The optimizer is DecoupledLionW with betas of 0.99 and 0.95 and no weight decay. The learning rate scheduler is LinearWithWarmupSchedule with a warmup of 2% of the total training duration and a final learning rate multiplier of 0. |
|
context_length |
str | The maximum sequence length of a data sample. This is used to truncate any data that is too long and to package shorter sequences together for efficiency. The default is 8192 tokens or the maximum context length for the provided model, whichever is lower. You can use this parameter to configure the context length, but configuring beyond each model’s maximum context length is not supported. See Supported models for the maximum supported context length of each model. |
|
validate_inputs |
Boolean | Whether to validate the access to input paths before submitting the training job. Default is True. |
Build on custom model weights
Foundation Model Fine-tuning supports adding custom weights using the optional parameter custom_weights_path to train and customize a model.
To get started, set custom_weights_path to the Composer checkpoint path from a previous training run. Checkpoint paths can be found in the Artifacts tab of a previous MLflow run. The checkpoint folder name corresponds to the batch and epoch of a particular snapshot, such as ep29-ba30/.

- To provide the latest checkpoint from a previous run, set
custom_weights_pathto the Composer checkpoint. For example,custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - To provide an earlier checkpoint, set
custom_weights_pathto a path to a folder containing.distcpfiles corresponding to the desired checkpoint, such ascustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Next, update the model parameter to match the base model of the checkpoint you passed to custom_weights_path.
In the following example ift-meta-llama-3-1-70b-instruct-ohugkq is a previous run that fine-tunes meta-llama/Meta-Llama-3.1-70B. To fine-tune the latest checkpoint from ift-meta-llama-3-1-70b-instruct-ohugkq, set the model and custom_weights_path variables as follows:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
See Configure a training run for configuring other parameters in your fine-tuning run.
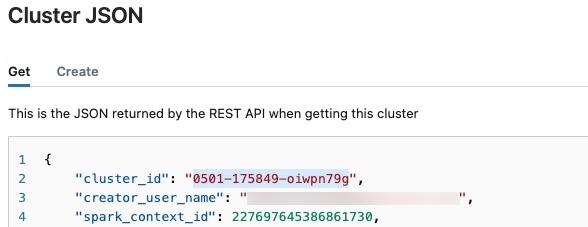
Get cluster ID
To retrieve the cluster ID:
In the left nav bar of the Databricks workspace, click Compute.
In the table, click the name of your cluster.
Click
 in the upper-right corner and select View JSON from the drop-down menu.
in the upper-right corner and select View JSON from the drop-down menu.The Cluster JSON file appears. Copy the cluster ID, which is the first line in the file.
Get status of a run
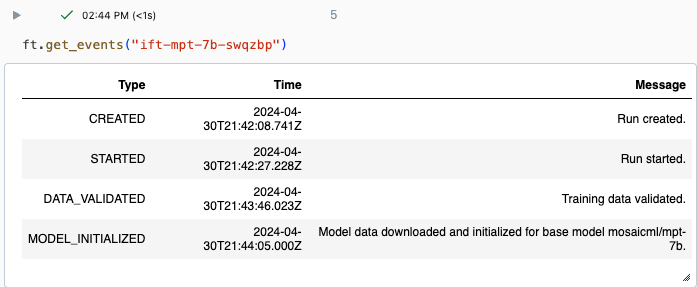
You can track the progress of a run using the Experiment page in the Databricks UI or using the API command get_events(). For details, see View, manage, and analyze Foundation Model Fine-tuning runs.
Example output from get_events():
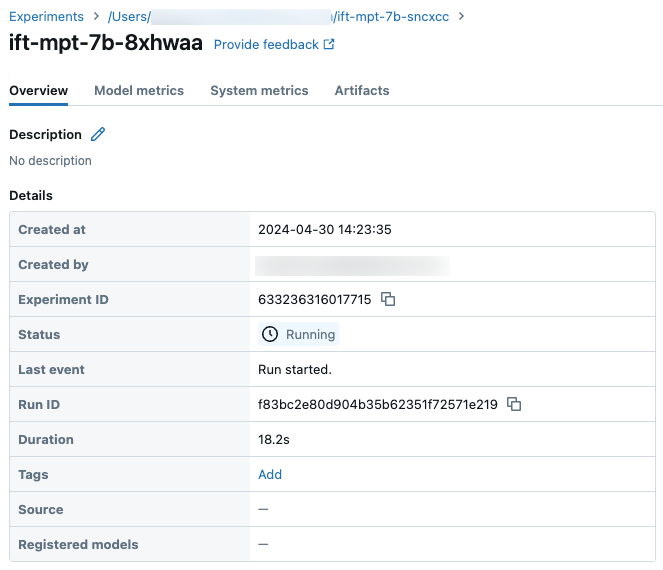
Sample run details on the Experiment page:
Next steps
After your training run is complete, you can review metrics in MLflow and deploy your model for inference. See steps 5 through 7 of Tutorial: Create and deploy a Foundation Model Fine-tuning run.
See the Instruction fine-tuning: Named Entity Recognition demo notebook for an instruction fine-tuning example that walks through data preparation, fine-tuning training run configuration and deployment.
Notebook example
The following notebook shows an example of how to generate synthetic data using the Meta Llama 3.1 405B Instruct model and use that data to fine-tune a model: