How to create and query a vector search index
This article describes how to create and query a vector search index using Mosaic AI Vector Search.
You can create and manage vector search components, like a vector search endpoint and vector search indices, using the UI, the Python SDK, or the REST API.
Requirements
- Unity Catalog enabled workspace.
- Serverless compute enabled. For instructions, see Connect to serverless compute.
- Source table must have Change Data Feed enabled. For instructions, see Use Delta Lake change data feed on Azure Databricks.
- To create a vector search index, you must have CREATE TABLE privileges on the catalog schema where the index will be created.
- To query an index that is owned by another user, you must have additional privileges. See Query a vector search endpoint.
Permission to create and manage vector search endpoints is configured using access control lists. See Vector search endpoint ACLs.
Installation
To use the vector search SDK, you must install it in your notebook. Use the following code:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
Authentication
See Data protection and authentication.
Create a vector search endpoint
You can create a vector search endpoint using the Databricks UI, Python SDK, or the API.
Create a vector search endpoint using the UI
Follow these steps to create a vector search endpoint using the UI.
In the left sidebar, click Compute.
Click the Vector Search tab and click Create.

The Create endpoint form opens. Enter a name for this endpoint.
Click Confirm.
Create a vector search endpoint using the Python SDK
The following example uses the create_endpoint() SDK function to create a vector search endpoint.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Create a vector search endpoint using the REST API
See the REST API reference documentation: POST /api/2.0/vector-search/endpoints.
(Optional) Create and configure an endpoint to serve the embedding model
If you choose to have Databricks compute the embeddings, you can use a pre-configured Foundation Model APIs endpoint or create a model serving endpoint to serve the embedding model of your choice. See Pay-per-token Foundation Model APIs or Create generative AI model serving endpoints for instructions. For example notebooks, see Notebook examples for calling an embeddings model.
When you configure an embedding endpoint, Databricks recommends that you remove the default selection of Scale to zero. Serving endpoints can take a couple of minutes to warm up, and the initial query on an index with a scaled down endpoint might timeout.
Note
The vector search index initialization might time out if the embedding endpoint isn’t configured appropriately for the dataset. You should only use CPU endpoints for small datasets and tests. For larger datasets, use a GPU endpoint for optimal performance.
Create a vector search index
You can create a vector search index using the UI, the Python SDK, or the REST API. The UI is the simplest approach.
There are two types of indexes:
- Delta Sync Index automatically syncs with a source Delta Table, automatically and incrementally updating the index as the underlying data in the Delta Table changes.
- Direct Vector Access Index supports direct read and write of vectors and metadata. The user is responsible for updating this table using the REST API or the Python SDK. This type of index cannot be created using the UI. You must use the REST API or the SDK.
Create index using the UI
In the left sidebar, click Catalog to open the Catalog Explorer UI.
Navigate to the Delta table you want to use.
Click the Create button at the upper-right, and select Vector search index from the drop-down menu.
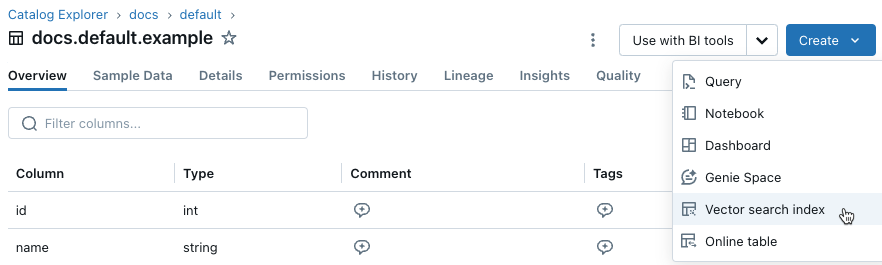
Use the selectors in the dialog to configure the index.
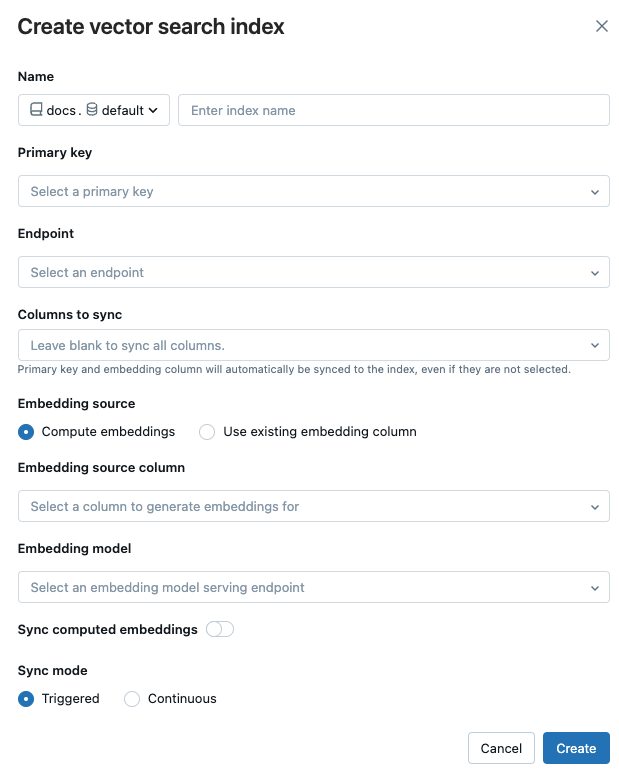
Name: Name to use for the online table in Unity Catalog. The name requires a three-level namespace,
<catalog>.<schema>.<name>. Only alphanumeric characters and underscores are allowed.Primary key: Column to use as a primary key.
Endpoint: Select the vector search endpoint that you want to use.
Columns to sync: Select the columns to sync with the vector index. If you leave this field blank, all columns from the source table are synced with the index. The primary key column and embedding source column or embedding vector column are always synced.
Embedding source: Indicate if you want Databricks to compute embeddings for a text column in the Delta table (Compute embeddings), or if your Delta table contains precomputed embeddings (Use existing embedding column).
- If you selected Compute embeddings, select the column that you want embeddings computed for and the endpoint that is serving the embedding model. Only text columns are supported.
- If you selected Use existing embedding column, select the column that contains the precomputed embeddings and the embedding dimension. The format of the precomputed embedding column should be
array[float].
Sync computed embeddings: Toggle this setting to save the generated embeddings to a Unity Catalog table. For more information, see Save generated embedding table.
Sync mode: Continuous keeps the index in sync with seconds of latency. However, it has a higher cost associated with it since a compute cluster is provisioned to run the continuous sync streaming pipeline. For both Continuous and Triggered, the update is incremental — only data that has changed since the last sync is processed.
With Triggered sync mode, you use the Python SDK or the REST API to start the sync. See Update a Delta Sync Index.
When you have finished configuring the index, click Create.
Create index using the Python SDK
The following example creates a Delta Sync Index with embeddings computed by Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
The following example creates a Delta Sync Index with self-managed embeddings. This example also shows the use of the optional parameter columns_to_sync to select only a subset of columns to use in the index.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
By default, all columns from the source table are synced with the index. To sync only a subset of columns, use columns_to_sync. The primary key and embedding columns are always included in the index.
To sync only the primary key and the embedding column, you must specify them in columns_to_sync as shown:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
To sync additional columns, specify them as shown. You do not need to include the primary key and the embedding column, as they are always synced.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
The following example creates a Direct Vector Access Index.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Create index using the REST API
See the REST API reference documentation: POST /api/2.0/vector-search/indexes.
Save generated embedding table
If Databricks generates the embeddings, you can save the generated embeddings to a table in Unity Catalog. This table is created in the same schema as the vector index and is linked from the vector index page.
The name of the table is the name of the vector search index, appended by _writeback_table. The name is not editable.
You can access and query the table like any other table in Unity Catalog. However, you should not drop or modify the table, as it is not intended to be manually updated. The table is deleted automatically if the index is deleted.
Update a vector search index
Update a Delta Sync Index
Indexes created with Continuous sync mode automatically update when the source Delta table changes. If you are using Triggered sync mode, use the Python SDK or the REST API to start the sync.
Python SDK
index.sync()
REST API
See the REST API reference documentation: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Update a Direct Vector Access Index
You can use the Python SDK or the REST API to insert, update, or delete data from a Direct Vector Access Index.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
See the REST API reference documentation: POST /api/2.0/vector-search/indexes.
The following code example illustrates how to update an index using a personal access token (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
The following code example illustrates how to update an index using a service principal.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Query a vector search endpoint
You can only query the vector search endpoint using the Python SDK, the REST API, or the SQL vector_search() AI function.
Note
If the user querying the endpoint is not the owner of the vector search index, the user must have the following UC privileges:
- USE CATALOG on the catalog that contains the vector search index.
- USE SCHEMA on the schema that contains the vector search index.
- SELECT on the vector search index.
To perform a hybrid keyword-similarity search, set the parameter query_type to hybrid. The default value is ann (approximate nearest neighbor).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
See the REST API reference documentation: POST /api/2.0/vector-search/indexes/{index_name}/query.
The following code example illustrates how to query an index using a personal access token (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
The following code example illustrates how to query an index using a service principal.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Important
The vector_search() AI function is in Public Preview.
To use this AI function, see vector_search function.
Use filters on queries
A query can define filters based on any column in the Delta table. similarity_search returns only rows that match the specified filters. The following filters are supported:
| Filter operator | Behavior | Examples |
|---|---|---|
NOT |
Negates the filter. The key must end with “NOT”. For example, “color NOT” with value “red” matches documents where the color is not red. | {"id NOT": 2} {“color NOT”: “red”} |
< |
Checks if the field value is less than the filter value. The key must end with ” <”. For example, “price <” with value 200 matches documents where the price is less than 200. | {"id <": 200} |
<= |
Checks if the field value is less than or equal to the filter value. The key must end with ” <=”. For example, “price <=” with value 200 matches documents where the price is less than or equal to 200. | {"id <=": 200} |
> |
Checks if the field value is greater than the filter value. The key must end with ” >”. For example, “price >” with value 200 matches documents where the price is greater than 200. | {"id >": 200} |
>= |
Checks if the field value is greater than or equal to the filter value. The key must end with ” >=”. For example, “price >=” with value 200 matches documents where the price is greater than or equal to 200. | {"id >=": 200} |
OR |
Checks if the field value matches any of the filter values. The key must contain OR to separate multiple subkeys. For example, color1 OR color2 with value ["red", "blue"] matches documents where either color1 is red or color2 is blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Matches partial strings. | {"column LIKE": "hello"} |
| No filter operator specified | Filter checks for an exact match. If multiple values are specified, it matches any of the values. | {"id": 200} {"id": [200, 300]} |
See the following code examples:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
See POST /api/2.0/vector-search/indexes/{index_name}/query.
Example notebooks
The examples in this section demonstrate usage of the vector search Python SDK.
LangChain examples
See How to use LangChain with Mosaic AI Vector Search for using Mosaic AI Vector Search as in integration with LangChain packages.
The following notebook shows how to convert your similarity search results to LangChain documents.
Vector search with the Python SDK notebook
Notebook examples for calling an embeddings model
The following notebooks demonstrate how to configure a Mosaic AI Model Serving endpoint for embeddings generation.