Use the Review App for human reviews of a gen AI app
Important
This feature is in Public Preview.
Collect feedback from subject matter experts (SMEs)
This article describes how to:
- Give your stakeholders the ability to chat with a pre-production generative AI app and give feedback
- Create an evaluation dataset, backed by a Unity Catalog delta table
- Leverage SMEs to expand and iterate on that evaluation dataset
- Leverage SMEs to label production traces to understand quality of your gen AI app
What happens in a human evaluation?
The Databricks review app stages an environment where stakeholders can interact with it - in other words, have a conversation, ask questions, provide feedback, and so on.
There are two main ways to use the review app:
- Chat with the bot: Collect questions, answers, and feedback in an inference table so you can further analyze the gen AI app's performance. In this way, the review app helps to ensure the quality and safety of the answers your application provides.
- Label responses in a session: Collect feedback and expectations from SMEs in a labeling session, stored under an MLFLow run. You can optionally sync these labels to an evaluation dataset.
Requirements
- Developers must install the
databricks-agentsSDK to set up permissions and configure the review app.
%pip install databricks-agents
dbutils.library.restartPython()
- For chat with the bot:
- Inference tables must be enabled on the endpoint that is serving the agent.
- Each human reviewer must have access to the review app workspace or be synced to your Databricks account with SCIM. See the next section, Set up permissions to use the review app.
- For labeling sessions:
Set up permissions to use the review app
Note
- For chatting with the bot, human reviewers do not require access to the workspace
- For labeling sessions, human reviewers do require access to the workspace
Setup permissions for "Chat with the bot"
- For users who do not have access to the workspace, an account admin uses account-level SCIM provisioning to sync users and groups automatically from your identity provider to your Azure Databricks account. You can also manually register these users and groups to give them access when you set up identities in Databricks. See Sync users and groups from Microsoft Entra ID using SCIM.
- For users who already have access to the workspace that contains the review app, no additional configuration is required.
The following code example shows how to give users permission to the model that was deployed via agents.deploy. The users parameter takes a list of email addresses.
from databricks import agents
# Note that <user_list> can specify individual users or groups.
agents.set_permissions(model_name=<model_name>, users=[<user_list>], permission_level=agents.PermissionLevel.CAN_QUERY)
Setup permissions for labeling sessions
Users are automatically granted the appropriate permissions (write access to an experiment and read access to a dataset) when you create a labeling session and provide the assigned_users argument.
For more info, see Create a labeling session and send for review below.
Deploy the review app
When you deploy a gen AI app using agents.deploy(), the review app is automatically enabled and deployed. The output from the command shows the URL for the review app. For information about deploying gen AI app (also called an "agent", see Deploy an agent for generative AI application.
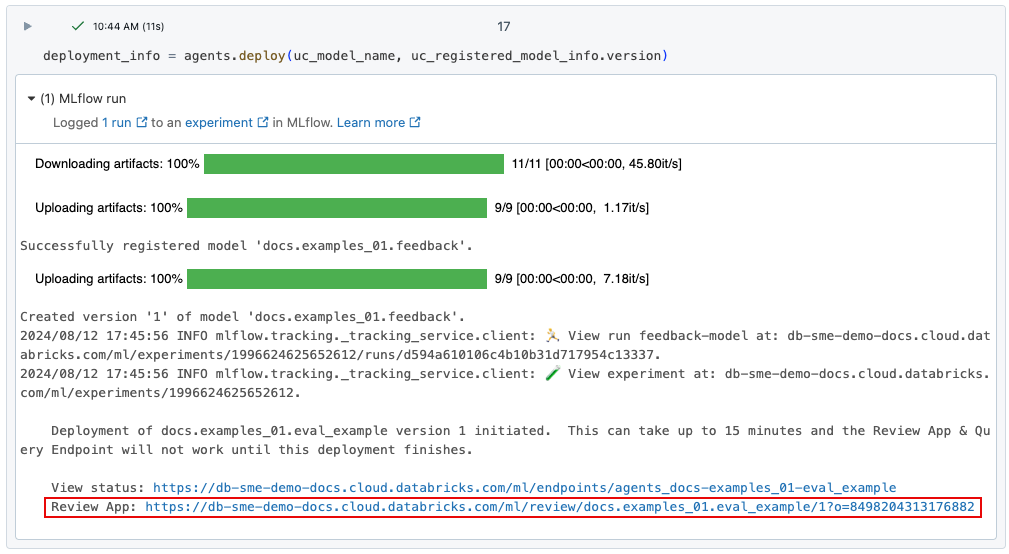
If you lose the link to the Review App UI, you can find it using get_review_app().
import mlflow
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
mlflow.set_experiment("same_exp_used_to_deploy_the_agent")
my_app = review_app.get_review_app()
print(my_app.url)
print(my_app.url + "/chat") # For "Chat with the bot".
Concepts
Datasets
A Dataset is a collection of examples used to evaluate a gen AI application. Dataset records contain inputs to a gen AI application and optionally expectations (ground truth labels, like expected_facts or guidelines). Datasets are linked to an MLFlow experiment, and can be directly used as inputs to mlflow.evaluate(). Datasets are backed by Delta tables in Unity Catalog, inheriting the permissions defined by the Delta table. To create a dataset, see Create a Dataset.
Example evaluation dataset, showing only inputs and expectations columns:

Evaluation datasets have the following schema:
| Column | Data Type | Description |
|---|---|---|
| dataset_record_id | string | The unique identifier for the record. |
| inputs | string | Inputs to evaluation as json serialized dict<str, Any> |
| expectations | string | Expected values as json serialized dict<str, Any> |
| create_time | timestamp | The time when the record was created. |
| created_by | string | The user who created the record. |
| last_update_time | timestamp | The time when the record was last updated. |
| last_updated_by | string | The user who last updated the record. |
| source | struct | The source of the dataset record |
| source.human | struct | Defined when the source is from a human |
| source.human.user_name | string | The name of the user associated with the record. |
| source.document | string | Defined when the record was synthesized from a doc |
| source.document.doc_uri | string | The URI of the document. |
| source.document.content | string | The content of the document. |
| source.trace | string | Defined when the record was created from a trace |
| source.trace.trace_id | string | The unique identifier for the trace. |
| tags | map | Key-value tags for the dataset record |
Review App
The Review App allows you you to:
- Curate an evaluation dataset with your SMEs.
- Collect feedback from your SME on a set of MLFlow traces from your application.
- Give your SMEs access to free-form chat with the bot, storing their feedback in inference tables to simulate production behavior.
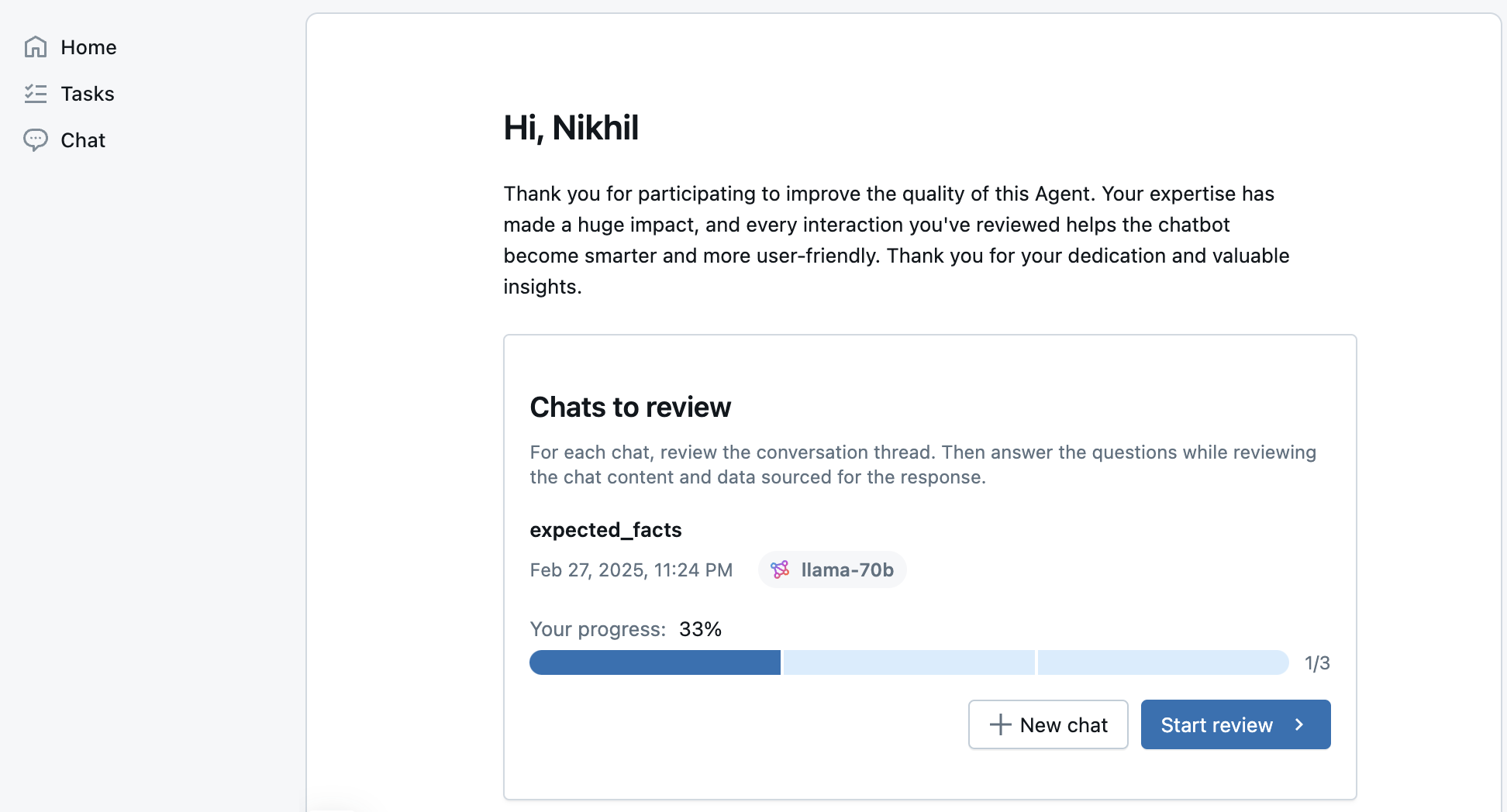
Labeling Sessions
A Labeling Session is a finite set of traces or dataset records to get labeled by an SME in the Review App UI. Traces can come from inference tables for an application in production, or an offline trace in MLFlow experiments. The results of a labeling session will be stored as an MLFlow run. Labels are stored as Assessments on MLFlow Traces. Labels with “expectations” can be synced back to an evaluation Dataset.
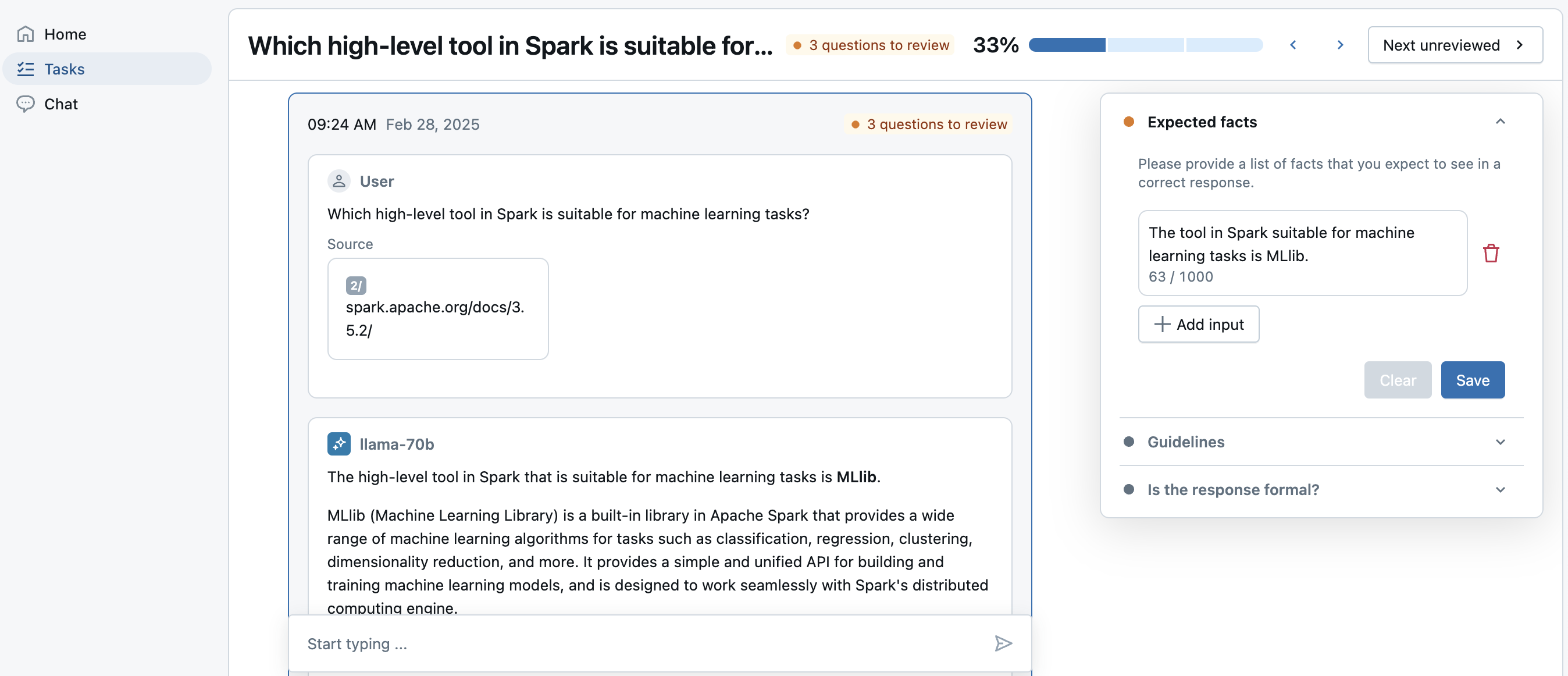
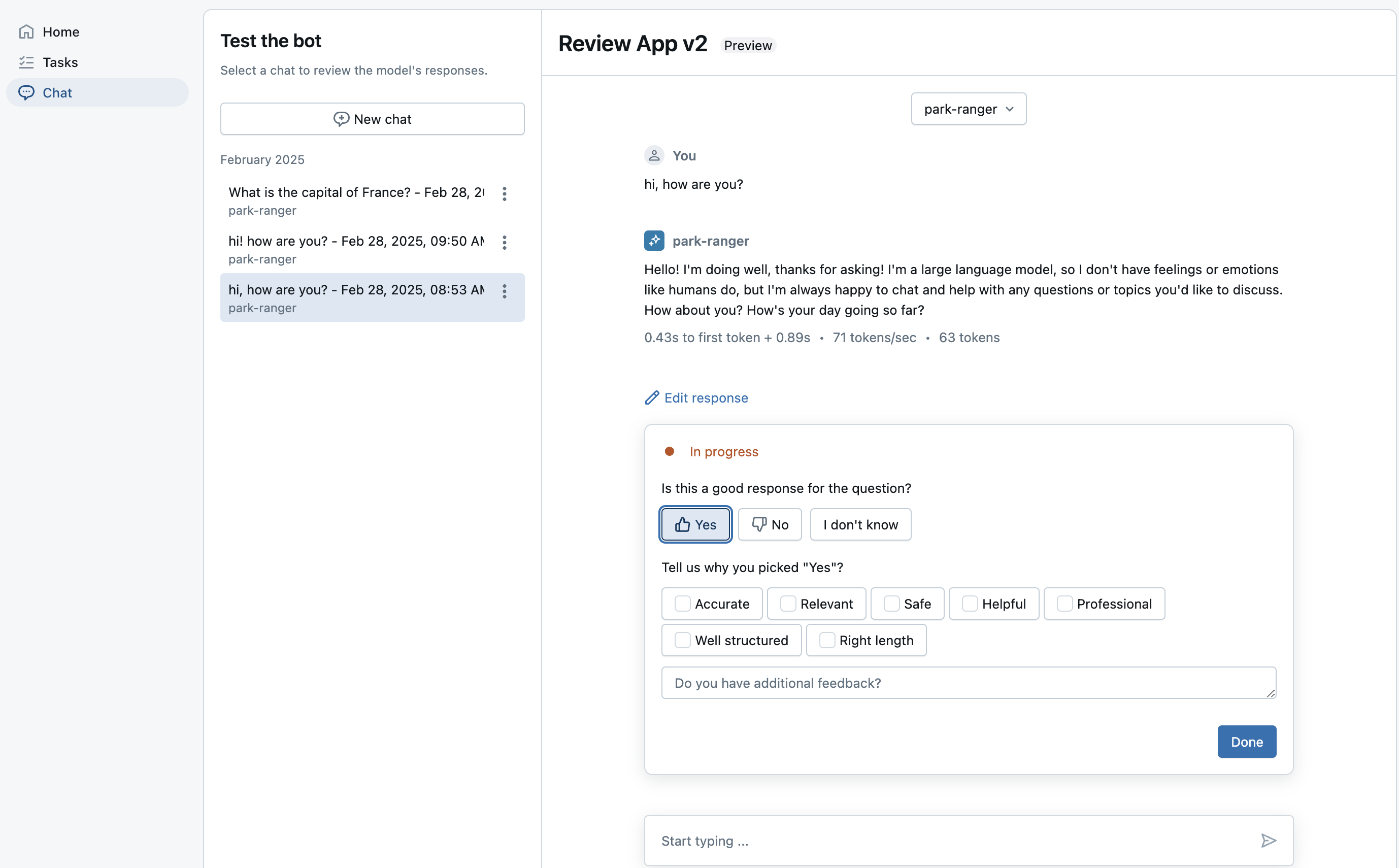
Chat with the bot and provide feedback
The Review App also has a Chat tab, which allows your SME to chat with the bot and give feedback for new questions they might ask. These interactions and feedback are saved in inference tables
Assessments and labels
When a SME labels a trace, Assessments are written to the trace under the Trace.info.assessments field. Assessments can have two types:
expectation: Labels that represent what a correct trace should have. For example:expected_factscan be used as anexpectationlabel, representing the facts that should be present in an ideal response. Theseexpectationlabels can be synced back to an evaluation dataset so they can be used withmlflow.evaluate().feedback: Labels that represent simple feedback on a trace, like "thumbs up" and "thumbs down", or free-form comments.Assessments of typefeedbackare not used with evaluation datasets as they are a human evaluation of a particular MLFLow Trace. These assessments can be read withmlflow.search_traces().
Datasets
This section will explain how you can:
- Create a dataset and use it for evaluation, without a SME.
- Request a labeling session from a SME to curate a better evaluation dataset.
Create a Dataset
The following example creates a Dataset and inserts evaluations. To seed the dataset with synthetic evaluations, see Synthesize evaluation sets.
from databricks.agents import datasets
import mlflow
# The following call creates an empty dataset. To delete a dataset, use datasets.delete_dataset(uc_table_name).
dataset = datasets.create_dataset("cat.schema.my_managed_dataset")
# Optionally, insert evaluations.
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the capital of France?"}]},
"guidelines": ["The response must be in English", "The response must be clear, coherent, and concise"],
}]
dataset.insert(eval_set)
The data from this dataset is backed by a Unity Catalog Delta Table and is visible in the Catalog Explorer.
Note
Named guidelines (using a dictionary) are currently not supported in a labeling session.
Using a dataset for evaluation
The following example reads the dataset from unity catalog, using the evaluation dataset to evaluate a simple system prompt agent.
import mlflow
from mlflow.deployments import get_deploy_client
# Define a very simple system-prompt agent to test against our evaluation set.
@mlflow.trace(span_type="AGENT")
def llama3_agent(request):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
*request["messages"]
]
}
)
evals = spark.read.table("cat.schema.my_managed_dataset")
mlflow.evaluate(
data=evals,
model=llama3_agent,
model_type="databricks-agent"
)
Create a labeling session and send for review
The following example creates a LabelingSession from the dataset above using ReviewApp.create_labeling_session, configuring the session
to collect guidelines and expected_facts from SMEs using the ReviewApp.label_schemas field. You can also create custom label schemas with ReviewApp.create_label_schema
Note
- When creating a labeling session, assigned users are:
- Given WRITE permission to the MLFlow experiment.
- Given QUERY permission to any model serving endpoints associated with the review app.
- When adding a dataset to a labeling session, assigned users are given SELECT permission to the delta tables of the datasets used to seed the labeling session.
from databricks.agents import review_app
import mlflow
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# You can use the following code to remove any existing agents.
# for agent in list(my_app.agents):
# my_app.remove_agent(agent.agent_name)
# Add the llama3 70b model serving endpoint for labeling. You should replace this with your own model serving endpoint for your
# own agent.
# NOTE: An agent is required when labeling an evaluation dataset.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
# Create a labeling session and collect guidelines and/or expected-facts from SMEs.
# Note: Each assigned user is given QUERY access to the serving endpoint above and write access.
# to the MLFlow experiment.
my_session = my_app.create_labeling_session(
name="my_session",
agent="llama-70b",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas = [review_app.label_schemas.GUIDELINES, review_app.label_schemas.EXPECTED_FACTS]
)
# Add the records from the dataset to the labeling session.
# Note: Each assigned user above is given SELECT access to the UC delta table.
my_session.add_dataset("cat.schema.my_managed_dataset")
# Share the following URL with your SMEs for them to bookmark. For the given review app linked to an experiment, this URL never changes.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the Review App
# URL above to keep a permanent URL.
print(my_session.url)
At this point, you can send the URLs above to your SMEs.
While your SME is labeling, you can view the status of the labeling with the following code:
mlflow.search_traces(run_id=my_session.mlflow_run_id)
Sync labeling session expectations back to the dataset
After the SME has completed labeling, you can sync the expectation labels back to the dataset with LabelingSession.sync_expectations. Examples of labels with the type expectation include GUIDELINES, EXPECTED_FACTS, or your own custom label schema that has a type expectation.
my_session.sync_expectations(to_dataset="cat.schema.my_managed_dataset")
display(spark.read.table("cat.schema.my_managed_dataset"))
You can now use this evaluation dataset:
eval_results = mlflow.evaluate(
model=llama3_agent,
data=dataset.to_df(),
model_type="databricks-agent"
)
Collect feedback on traces from your SMEs
Label traces
This section will show you how to collect labels on MLFlow trace objects that can come from:
- an MLFlow experiment or run
- an inference table
- any MLFlow python Trace object
From an MLFlow experiment or run
In this example we will create a set of traces from a Llama 3 Agent to be labeled by your SMEs.
import mlflow
from mlflow.deployments import get_deploy_client
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Create a trace to be labeled.
with mlflow.start_run(run_name="llama3") as run:
run_id = run.info.run_id
llama3_agent([{"content": "What is databricks?", "role": "user"}])
llama3_agent([{"content": "How do I set up a SQL Warehouse?", "role": "user"}])
You can get labels for the trace and create a labeling session from them. This example sets up a labeling session with a single label schema to collect "formality" feedback on the Agent response. The labels from the SME are stored as an Assessment on the MLFlow Trace.
For more types of schema inputs, see databricks-agents SDK.
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# Use the run_id from above.
traces = mlflow.search_traces(run_id=run_id)
formality_label_schema = my_app.create_label_schema(
name="formal",
# Type can be "expectation" or "feedback".
type="feedback",
title="Is the response formal?",
input=review_app.label_schemas.InputCategorical(options=["Yes", "No"]),
instruction="Please provide a rationale below.",
enable_comment=True
)
my_session = my_app.create_labeling_session(
name="my_session",
# NOTE: An `agent` is not required. If you do provide an Agent, your SME can ask follow up questions in a converstion and create new questions in the labeling session.
assigned_users=["email1@company.com", "email2@company.com"],
# More than one label schema can be provided and the SME will be able to provide information for each one.
# We use only the "formal" schema defined above for simplicity.
label_schemas=["formal"]
)
# NOTE: This will copy the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
# Share the following URL with your SMEs for them to bookmark. For the given review app, linked to an experiment, this URL will never change.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the Review App
# URL above to keep a permanent URL.
print(my_session.url)
Once the SME has finished labeling, the resulting traces and assessments will be part of the run that is associated with the labeling session.
mlflow.search_traces(run_id=my_session.mlflow_run_id)
You can now use these assessments to improve your model or update the evaluation dataset.
Label traces from an inference table
This example shows how to add traces directly from the inference table (request payload logs) into a labeling session.
# CHANGE TO YOUR PAYLOAD REQUEST LOGS TABLE
PAYLOAD_REQUEST_LOGS_TABLE = "catalog.schema.my_agent_payload_request_logs"
traces = spark.table(PAYLOAD_REQUEST_LOGS_TABLE).select("trace").limit(3).toPandas()
my_session = my_app.create_labeling_session(
name="my_session",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas=[review_app.label_schemas.EXPECTED_FACTS]
)
# NOTE: This will copy the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
print(my_session.url)
Example notebook
The following example notebook illustrates the different ways to use datasets and labeling sessions in Mosaic AI Agent Evaluation.