Transactional replication with Azure SQL Managed Instance
Applies to: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Transactional replication is a feature of Azure SQL Managed Instance and SQL Server that enables you to replicate data from a table in Azure SQL Managed Instance or a SQL Server instance, to tables placed on remote databases. This feature allows you to synchronize multiple tables in different databases.
Overview
You can use transactional replication to push changes made in an Azure SQL managed instance to:
- A SQL Server database (on-premises or on an Azure Virtual Machine)
- A database in Azure SQL Database
- An instance database in Azure SQL Managed Instance
Note
To use all the features of Azure SQL Managed Instance, you must use the latest versions of SQL Server Management Studio (SSMS) and SQL Server Data Tools (SSDT).
Components
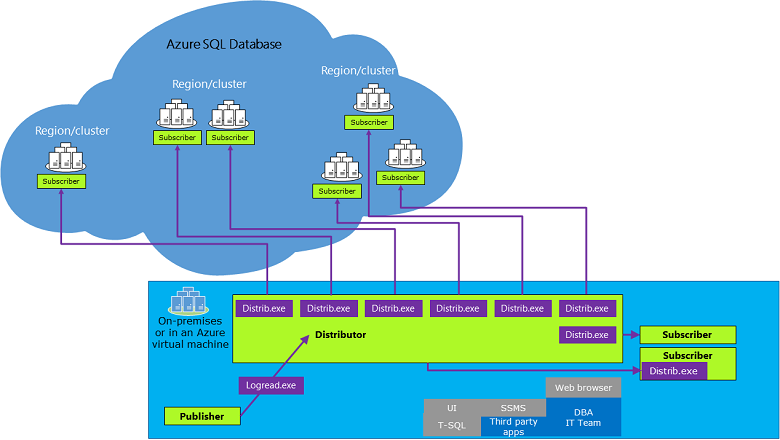
The key components in transactional replication are the Publisher, Distributor, and Subscriber, as shown in the following picture:
| Role | Azure SQL Database | Azure SQL Managed Instance |
|---|---|---|
| Publisher | No | Yes |
| Distributor | No | Yes |
| Pull subscriber | No | Yes |
| Push subscriber | Yes | Yes |
The Publisher publishes changes made on some tables (articles) by sending the updates to the Distributor. The publisher can be an Azure SQL managed instance or a SQL Server instance.
The Distributor collects changes in the articles from a Publisher and distributes them to the Subscribers. The Distributor can be either an Azure SQL managed instance or a SQL Server instance (any version as long it's equal to or higher than the Publisher version).
The Subscriber receives changes made on the Publisher. A SQL Server instance and Azure SQL managed instance can both be push and pull subscribers, though a pull subscription isn't supported when the distributor is an Azure SQL managed instance and the subscriber isn't. A database in Azure SQL Database can only be a push subscriber.
Azure SQL Managed Instance can support being a Subscriber from the following versions of SQL Server:
- SQL Server 2016 and later versions
- SQL Server 2014 RTM CU10 (12.0.4427.24) or SP1 CU3 (12.0.2556.4)
- SQL Server 2012 SP2 CU8 (11.0.5634.1) or SP3 (11.0.6020.0) or SP4 (11.0.7001.0)
Note
For other versions of SQL Server that do not support publishing to objects in Azure, you can use the republishing data method to move data to newer versions of SQL Server.
Attempting to configure replication using an older version can result in error MSSQL_REPL20084 (The process could not connect to Subscriber), and MSSQL_REPL40532 (Cannot open server <name> requested by the login. The login failed).
Types of replication
There are different types of replication:
| Replication | Azure SQL Database | Azure SQL Managed Instance |
|---|---|---|
| Standard transactional | Yes (only as subscriber) | Yes |
| Snapshot | Yes (only as subscriber) | Yes |
| Merge replication | No | No |
| Peer-to-peer | No | No |
| Bidirectional | No | Yes |
| Updatable subscriptions | No | No |
Supportability matrix
The transactional replication supportability matrix for Azure SQL Managed Instance is the same as the one for SQL Server.
| Publisher | Distributor | Subscriber |
|---|---|---|
| SQL Server 2022 | SQL Server 2022 | SQL Server 2022 SQL Server 2019 SQL Server 2017 |
| SQL Server 2019 | SQL Server 2022 SQL Server 2019 |
SQL Server 2022 SQL Server 2019 SQL Server 2017 SQL Server 2016 |
| SQL Server 2017 | SQL Server 2022 SQL Server 2019 SQL Server 2017 |
SQL Server 2022 SQL Server 2019 SQL Server 2017 SQL Server 2016 SQL Server 2014 |
| SQL Server 2016 | SQL Server 2022 SQL Server 2019 SQL Server 2017 SQL Server 2016 |
SQL Server 2019 SQL Server 2017 SQL Server 2016 SQL Server 2014 SQL Server 2012 |
| SQL Server 2014 | SQL Server 2022 SQL Server 2019 SQL Server 2017 SQL Server 2016 SQL Server 2014 |
SQL Server 2017 SQL Server 2016 SQL Server 2014 SQL Server 2012 SQL Server 2008 R2 SQL Server 2008 |
| SQL Server 2012 | SQL Server 2022 SQL Server 2019 SQL Server 2017 SQL Server 2016 SQL Server 2014 SQL Server 2012 |
SQL Server 2016 SQL Server 2014 SQL Server 2012 SQL Server 2008 R2 SQL Server 2008 |
| SQL Server 2008 R2 SQL Server 2008 |
SQL Server 2022 SQL Server 2019 SQL Server 2017 SQL Server 2016 SQL Server 2014 SQL Server 2012 SQL Server 2008 R2 SQL Server 2008 |
SQL Server 2014 SQL Server 2012 SQL Server 2008 R2 SQL Server 2008 |
When to use
Transactional replication is useful in the following scenarios:
- Publish changes made in one or more tables in a database and distribute them to one or many databases in a SQL Server instance or Azure SQL Database that subscribed for the changes.
- Keep several distributed databases in synchronized state.
- Migrate databases from one SQL Server instance or Azure SQL Managed Instance to another database by continuously publishing the changes.
Compare Data Sync with transactional replication
| Category | Data Sync | Transactional replication |
|---|---|---|
| Advantages | - Active-active support - Bi-directional between on-premises and Azure SQL Database |
- Lower latency - Transactional consistency - Reuse existing topology after migration |
| Disadvantages | - No transactional consistency - Higher performance impact |
- Can't publish from Azure SQL Database - High maintenance cost |
Common configurations
In general, the publisher and the distributor must be either in the cloud or on-premises. The following configurations are supported:
Publisher with local Distributor on SQL Managed Instance
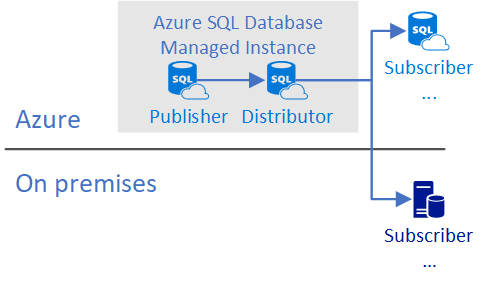
Publisher and distributor are configured within a single SQL managed instance and distributing changes to another SQL managed instance, SQL Database, or SQL Server instance.
Publisher with remote distributor on SQL Managed Instance
In this configuration, one SQL managed instance publishes changes to a distributor placed on another SQL managed instance that can serve many source SQL managed instances and distribute changes to one or many targets on Azure SQL Database, Azure SQL Managed Instance, or SQL Server.
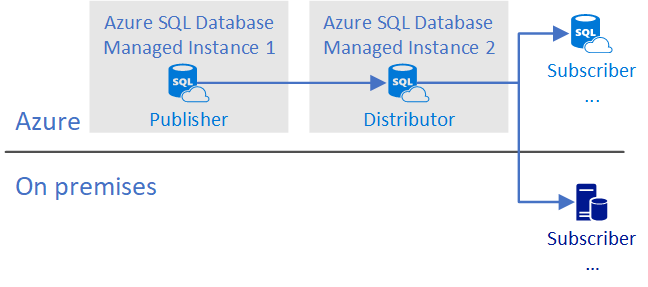
Publisher and distributor are configured on two managed instances. There are some constraints with this configuration:
- Both managed instances are on the same vNet.
- Both managed instances are in the same location.
On-premises Publisher/Distributor with remote subscriber
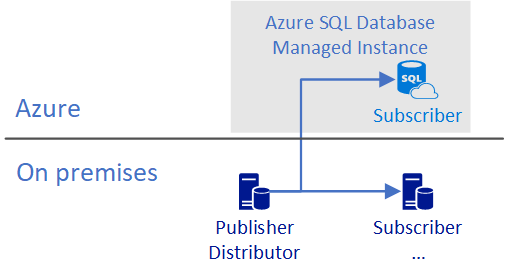
In this configuration, a database in Azure SQL Database or Azure SQL Managed Instance is a subscriber. This configuration supports migration from on-premises to Azure. If a subscriber is a database in Azure SQL Database, it must be in push mode.
Requirements
- Use SQL Authentication for connectivity between replication participants.
- Use an Azure Storage Account share for the working directory used by replication.
- Open TCP outbound port 445 in the subnet security rules to access the Azure file share.
- Open TCP outbound port 1433 when the SQL managed instance is the Publisher/Distributor, and the Subscriber isn't. You may also need to change the SQL managed instance NSG outbound security rule for
allow_linkedserver_outboundfor the port 1433 Destination Service tag fromvirtualnetworktointernet. - Place both the publisher and distributor in the cloud, or both on-premises.
- Configure VPN peering between the virtual networks of replication participants if the virtual networks are different.
Note
You may encounter error 53 when connecting to an Azure Storage File if the outbound network security group (NSG) port 445 is blocked when the distributor is an Azure SQL Managed Instance database and the subscriber is on-premises. Update the vNet NSG to resolve this issue.
Security
Login replAgentUser
For purposes of transactional replication, a SQL managed instance has a pre-created login(s) with the name replAgentUser. This login is a member of the sysadmin server role and is used by replication agents that need to connect to a SQL managed instance participating in transactional replication setup.
If transactional replication is not used, the login replAgentUser can be disabled. It can be re-enabled later if you decide to start using transactional replication.
Limitations
Transactional replication has some limitations that are specific to Azure SQL Managed Instance. Learn more about these limitations in this section.
Snapshot files aren't deleted from Azure Storage Account
Azure SQL Managed Instance is using user configured Azure Storage Account for snapshot files used for transactional replication. Unlike SQL Server in the on-premises environment, Azure SQL Managed Instance isn't deleting snapshot files from Azure Storage Account. Once files are no longer needed, you should delete them. This can be done via Azure Storage interface on Azure portal, Microsoft Azure Storage Explorer, or via command line clients (Azure PowerShell or CLI) or Azure Storage Management REST API.
Here's an example of how you can delete file and how you can delete an empty folder.
az storage file delete-batch --source <file_path> --account-key <account_key> --account-name <account_name>
az storage directory delete --name <directory_name> --share-name <share_name> --account-key <account_key> --account-name <account_name>
Number of distribution agents running continuously
Number of distribution agents configured to run continuously is limited to 30 on Azure SQL Managed Instance. To have more distribution agents they need to be running either on demand or with a defined schedule. Schedule can be defined with daily frequency and occurrence on every 10 seconds (or more), so even though it's not continuous, you still can have distributor that's introducing latency that's only several seconds. When large number of distributors is needed, it's recommended to use scheduled and not continuous configuration.
With failover groups
Using transactional replication with instances that are in a failover group is supported. However, if you configure replication before adding your SQL managed instance into a failover group, replication pauses when you start to create your failover group, and replication monitor shows a status of Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. Replication resumes once the failover group is created successfully.
If a publisher or distributor SQL managed instance is in a failover group, the SQL managed instance administrator must clean up all publications on the old primary and reconfigure them on the new primary after a failover occurs. The following activities are needed in this scenario:
Stop all replication jobs running on the database, if there are any.
Drop subscription metadata from publisher by running the following script on publisher database. Replace the
<name of publication>and<name of subscriber>values:EXEC sp_dropsubscription @publication = '<name of publication>', @article = 'all', @subscriber = '<name of subscriber>'Drop subscription metadata from the subscriber. Run the following script on the subscription database on the subscriber SQL managed instance. Replace the
<full DNS of publisher>value. For example,example.ac2d23028af5.database.windows.net:EXEC sp_subscription_cleanup @publisher = N'<full DNS of publisher>', @publisher_db = N'<publisher database>', @publication = N'<name of publication>';Forcefully drop all replication objects from publisher by running the following script in the published database:
EXEC sp_removedbreplication;Forcefully drop old distributor from the original primary SQL managed instance (if failing back over to an old primary that used to have a distributor). Run the following script on the
masterdatabase in the old distributor SQL managed instance:EXEC sp_dropdistributor 1, 1;
If a subscriber SQL managed instance is in a failover group, the publication should be configured to connect to the failover group listener endpoint for the subscriber SQL managed instance. In the event of a failover, subsequent action by the SQL managed instance administrator depends on the type of failover that occurred:
- For a failover with no data loss, replication will continue working after failover.
- For a failover with data loss, replication works as well. It replicates the lost changes again.
- For a failover with data loss, but the data loss is outside of the distribution database retention period, the SQL managed instance administrator needs to reinitialize the subscription database.
Troubleshoot common issues
Transaction log and Transactional Replication
In usual circumstances, transaction log is used for recording changes of the data within a database. Changes are recorded in the transaction log, and that makes the log storage consumption to grow. There's also an automatic process that allows safe truncation of the transaction log, and this process reduces the used storage space for the log. When publishing for Transactional Replication is configured, transaction log truncation is prevented until changes in the log are processed by the log reader job. In some circumstances, processing of the transaction log is effectively blocked, and that state can lead to filling up entire storage reserved for transaction log. When there's no free space for transaction log, and there's no more space for transaction log to grow, we have full transaction log. In this state, the database can no longer process any write workload, and effectively becomes read-only database.
Disabled log reader agent
Sometimes Transactional Replication publication is configured for a database, but log reader agent isn't configured to run. In that case, changes are accumulating in the transaction log, and they aren't being processed. This leads to constant growth of transactional log, and eventually to the full transaction log. User should make sure that log reader job exists and is active. Alternative would be to disable Transactional Replication, if it's not needed.
Log reader agent query timeouts
Sometimes, log reader job can't make effective progress due to repeated query timeouts. A way to fix query timeouts is to increase the query timeout setting for the log reader agent job.
Increasing query timeout for log reader job can be done with SSMS. In the object explorer, under SQL Server Agent, find the job you'd like to modify. First stop it, and then open its properties. Find step 2 and edit it. Append the command value with -QueryTimeout <timeout_in_seconds>. For the query timeout value try 21600 or higher. Finally, start the job again.
Log storage size reached max limit of 2 TB
When transaction log storage size reaches max limit, which is 2 TB, log physically can't grow more than that. In this case, the only available mitigation is marking all transactions that are to be replicated as processed, to allow transaction log to be truncated. This effectively means that remaining transactions in the log will not be replicated, and you need to reinitialize the replication.
Note
After performing mitigation you will need to reinitialize the replication, which means replicating entire data set again. This is size of data operation, and might be long running, depending on the amount of data that should be replicated.
To perform the mitigation, first you need to stop the log reader agent on the distributor. Then you should run the sp_repldone stored procedure with reset flag set to 1 on the publisher database, to allow transaction log truncation. This command should look like this EXEC sp_repldone @xactid = NULL, @xact_seqno = NULL, @numtrans = 0, @time = 0, @reset = 1. After this, you'll need to reinitialize the replication.
Next steps
For more information about configuring transactional replication, see the following tutorials:
- Configure replication between a SQL Managed Instance publisher and subscriber.
- Configure replication between a SQL Managed Instance publisher, SQL Managed Instance distributor, and SQL Server subscriber.
- Create a publication.
- Create a push subscription by using the server name as the subscriber (for example
N'azuresqldbdns.database.windows.net), and the database in Azure SQL Database name as the destination database (for example,Adventureworks).