Azure Managed Redis (preview) Architecture
Azure Managed Redis (preview) runs on the Redis Enterprise stack, which offers significant advantages over the community edition of Redis. The following information provides greater detail about how Azure Managed Redis is architected, including information that can be useful to power users.
Important
Azure Managed Redis is currently in PREVIEW. See the Supplemental Terms of Use for Microsoft Azure Previews for legal terms that apply to Azure features that are in beta, preview, or otherwise not yet released into general availability.
Comparison with Azure Cache for Redis
The Basic, Standard, and Premium tiers of Azure Cache for Redis were built on the community edition of Redis. This version of Redis has several significant limitations, including being single-threaded by design. This reduces performance significantly and makes scaling less efficient as more vCPUs aren't fully utilized by the service. A typical Azure Cache for Redis instance uses an architecture like this:
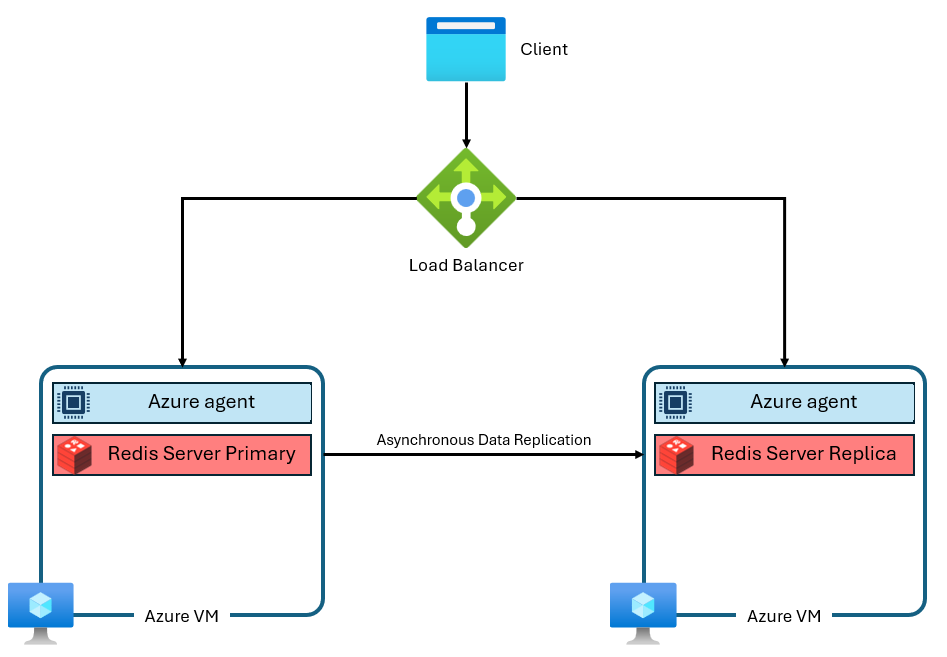
Notice that two VMs are used--a primary and a replica. These VMs are also called "nodes." The primary node holds the main Redis process and accepts all writes. Replication is conducted asynchronously to the replica node to provide a back-up copy during maintenance, scaling, or unexpected failure. Each node is only capable of running a single Redis server process due to the single-threaded design of community Redis.
Architectural Improvements of Azure Managed Redis
Azure Managed Redis uses a more advanced architecture that looks something like this:
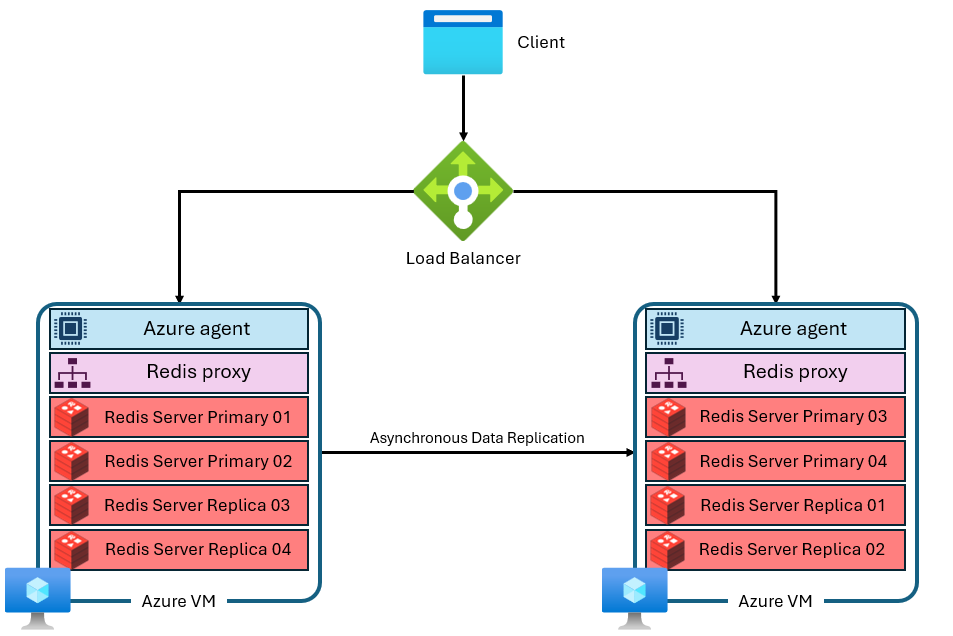
There are several differences:
- Each virtual machine (or "node") runs multiple Redis server processes (called "shards") in parallel. Multiple shards allow for more efficient utilization of vCPUs on each virtual machine and higher performance.
- Not all of the primary Redis shards are on the same VM/node. Instead, primary and replica shards are distributed across both nodes. Because primary shards use more CPU resources than replica shards, this approach enables more primary shards to be run in parallel.
- Each node has a high-performance proxy process to manage the shards, handle connection management, and trigger self-healing.
This architecture enables both higher performance and also advanced features like active geo-replication
Clustering
Because Redis Enterprise is able to use multiple shards per node, each Azure Managed Redis instance is internally configured to use clustering, across all tiers and SKUs. That includes smaller instances that are only set up to use a single shard. Clustering is a way to divide the data in the Redis instance across the multiple Redis processes, also called "sharding." Azure Managed Redis offers two cluster policies that determine which protocol is available to Redis clients for connecting to the cache instance.
Cluster policies
Azure Managed Redis offers two choices for clustering policy: OSS and Enterprise. OSS cluster policy is recommended for most applications because it supports higher maximum throughput, but there are advantages and disadvantages to each version.
The OSS clustering policy implements the same Redis Cluster API as community edition Redis. The Redis Cluster API allows the Redis client to connect directly to shards on each Redis node, minimizing latency and optimizing network throughput, allowing throughput to scale near-linearly as the number of shards and vCPUs increases. The OSS clustering policy generally provides the best latency and throughput performance. The OSS cluster policy, however, requires your client library to support the Redis Cluster API. Today, almost all Redis clients support the Redis Cluster API, but compatibility might be an issue for older client versions or specialized libraries. OSS clustering policy also can't be used with the RediSearch module.
The Enterprise clustering policy is a simpler configuration that utilizes a single endpoint for all client connections. Using the Enterprise clustering policy routes all requests to a single Redis node that is then used as a proxy, internally routing requests to the correct node in the cluster. The advantage of this approach is that it makes Azure Managed Redis look nonclustered to users. That means that Redis client libraries don’t need to support Redis Clustering to gain some of the performance advantages of Redis Enterprise, boosting backwards compatibility and making the connection simpler. The downside is that the single node proxy can be a bottleneck, in either compute utilization or network throughput. The Enterprise clustering policy is the only one that can be used with the RediSearch module. While the Enterprise cluster policy makes an Azure Managed Redis instance appear to be nonclustered to users, it still has some limitations with Multi-key commands.
Scaling out or adding nodes
The core Redis Enterprise software is capable of either scaling up (by using larger VMs) or scaling out (by adding more nodes/VMs). Ultimately, either scaling action accomplishes the same thing--adding more memory, more vCPUs, and more shards. Because of this redundancy, Azure Managed Redis doesn't offer the ability to control the specific number of nodes used in each configuration. This implementation detail is abstracted for the user to avoid confusion, complexity, and suboptimal configurations. Instead, each SKU is designed with a node configuration to maximize vCPUs and memory. Some SKUs of Azure Managed Redis use just two nodes, while some use more.
Multi-key commands
Because Azure Managed Redis instances are designed with a clustered configuration, you might see CROSSSLOT exceptions on commands that operate on multiple keys. Behavior varies depending on the clustering policy used. If you use the OSS clustering policy, multi-key commands require all keys to be mapped to the same hash slot.
You might also see CROSSSLOT errors with Enterprise clustering policy. Only the following multi-key commands are allowed across slots with Enterprise clustering: DEL, MSET, MGET, EXISTS, UNLINK, and TOUCH.
In Active-Active databases, multi-key write commands (DEL, MSET, UNLINK) can only be run on keys that are in the same slot. However, the following multi-key commands are allowed across slots in Active-Active databases: MGET, EXISTS, and TOUCH. For more information, see Database clustering.
Sharding configuration
Each SKU of Azure Managed Redis is configured to run a specific number of Redis server processes, shards in parallel. The relationship between throughput performance, the number of shards, and number of vCPUs available on each instance is complicated. Adding shards generally increases performance as Redis operations can be run in parallel. However, if shards aren't able to run commands because no vCPUs are available to execute commands, performance can actually drop. The following table shows the sharding configuration for each Azure Managed Redis SKU. These shards are mapped to optimize the usage of each vCPU while reserving vCPU cycles for Redis Enterprise proxy, management agent, and OS system tasks which also affect performance.
Note
The number of shards and vCPUs used on each SKU can change over time as performance is optimized by the Azure Managed Redis team.
| Tiers | Flash Optimized | Memory Optimized | Balanced | Compute Optimized |
|---|---|---|---|---|
| Size (GB) | vCPUs/primary shards | vCPUs/primary shards | vCPUs/primary shards | vCPUs/primary shards |
| 0.5 | - | - | 2/2 | - |
| 1 | - | - | 2/2 | - |
| 3 | - | - | 2/2 | 4/2 |
| 6 | - | - | 2/2 | 4/2 |
| 12 | - | 2/2 | 4/2 | 8/6 |
| 24 | - | 4/2 | 8/6 | 16/12 |
| 60 | - | 8/6 | 16/12 | 32/24 |
| 120 | - | 16/12 | 32/24 | 64/48 |
| 180 | - | 24/24 | 48/48 | 96/96 |
| 240 | 8/6 | 32/24 | 64/48 | 128/96 |
| 360 | - | 48/48 | 96/96 | 192/192 |
| 480 | 16/12 | 64/48 | 128/96 | 256/192 |
| 720 | 24/24 | 96/96 | 192/192 | 384/384 |
| 960 | 32/24 | 128/192 | 256/192 | - |
| 1440 | 48/48 | 192/192 | - | - |
| 1920 | 64/48 | 256/192 | - | - |
| 4500 | 144/96 | - | - | - |
Running without high availability mode enabled
It's possible to run without high availability (HA) mode enabled. This means that your Redis instance doesn't have replication enabled and doesn't have access to the availability SLA. We don't recommend running in non-HA mode outside of dev/test scenarios. You can't disable high availability in an instance that was already created. You can enable high availability in an instance that doesn't have it, however. Because an instance running without high availability uses fewer VMs/nodes, vCPUs aren't able to be utilized as efficiently, so performance might be lower.
Reserved memory
On each Azure Managed Redis Instance, approximately 20% of the available memory is reserved as a buffer for noncache operations, such as replication during failover and active geo-replication buffer. This buffer helps improve cache performance and prevent memory starvation.
Scaling down
Scaling down is not currently supported on Azure Managed redis. For more information, see Prerequisites/limitations of scaling Azure Managed Redis.
Flash Optimized tier
The Flash Optimized tier utilizes both NVMe Flash storage and RAM. Because Flash storage is lower cost, using the Flash Optimized tier allows you to trade off some performance for price efficiency.
On Flash Optimized instances, 20% of the cache space is on RAM, while the other 80% uses Flash storage. All of the keys are stored on RAM, while the values can be stored either in Flash storage or RAM. The Redis software intelligently determines the location of the values. Hot values that are accessed frequently are stored on RAM, while Cold values that are less commonly used are kept on Flash. Before data is read or written, it must be moved to RAM, becoming Hot data.
Because Redis optimizes for the best performance, the instance first fills up the available RAM before adding items to Flash storage. Filling RAM first has a few implications for performance:
- Better performance and lower latency can occur when testing with low memory usage. Testing with a full cache instance can yield lower performance because only RAM is being used in the low memory usage testing phase.
- As you write more data to the cache, the proportion of data in RAM compared to Flash storage decreases, typically causing latency and throughput performance to decrease as well.
Workloads well-suited for the Flash Optimized tier
Workloads that are likely to run well on the Flash Optimized tier often have the following characteristics:
- Read heavy, with a high ratio of read commands to write commands.
- Access is focused on a subset of keys that are used much more frequently than the rest of the dataset.
- Relatively large values in comparison to key names. (Because key names are always stored in RAM, large values can become a bottleneck for memory growth.)
Workloads that aren't well-suited for the Flash Optimized tier
Some workloads have access characteristics that are less optimized for the design of the Flash Optimized tier:
- Write heavy workloads.
- Random or uniform data access patterns across most of the dataset.
- Long key names with relatively small value sizes.