Deployment and testing for mission-critical workloads on Azure
The deployment and testing of the mission critical environment is a crucial piece of the overall reference architecture. The individual application stamps are deployed using infrastructure as code from a source code repository. Updates to the infrastructure, and the application on top, should be deployed with zero downtime to the application. A DevOps continuous integration pipeline is recommended to retrieve the source code from the repository and deploy the individual stamps in Azure.
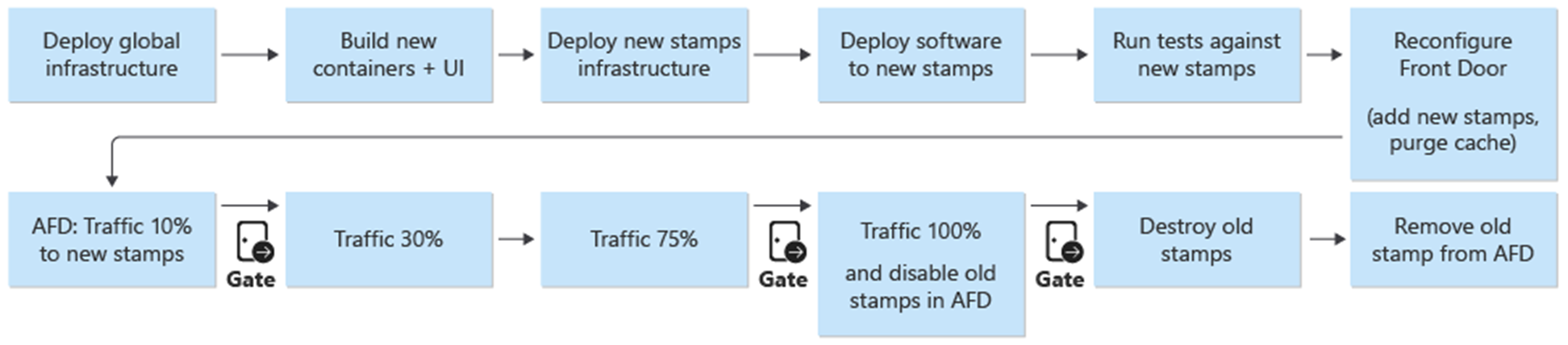
Deployment and updates are the central process in the architecture. Infrastructure and application related updates should be deployed to fully independent stamps. Only the global infrastructure components in the architecture are shared across the stamps. Existing stamps in the infrastructure aren't touched. Infrastructure updates are deployed to these new stamps. Likewise, the new application versions are deployed to these new stamps.
The new stamps are added to Azure Front Door. Traffic is gradually moved over to the new stamps. When traffic is served from the new stamps without issue, the previous stamps are deleted.
Penetration, chaos, and stress testing are recommended for the deployed environment. Proactive testing of the infrastructure discovers weaknesses and how the deployed application behaves if there's a failure.
Deployment
The deployment of the infrastructure in the reference architecture is dependent upon the following processes and components:
DevOps - The source code from GitHub and pipelines for the infrastructure.
Zero downtime updates - Updates and upgrades are deployed to the environment with zero downtime to the deployed application.
Environments - Short-lived and permanent environments used for the architecture.
Shared and dedicated resources - Azure resources that are dedicated and shared to the stamps and overall infrastructure.
For more information, see Deployment and testing for mission-critical workloads on Azure: Design considerations
Deployment: DevOps
The DevOps components provide the source code repository and CI/CD pipelines for deployment of the infrastructure and updates. GitHub and Azure Pipelines were chosen as the components.
GitHub - Contains the source code repositories for the application and infrastructure.
Azure Pipelines - The pipelines used by the architecture for all build, test, and release tasks.
An extra component in the design used for the deployment is build agents. Microsoft Hosted build agents are used as part of Azure Pipelines to deploy the infrastructure and updates. The use of Microsoft Hosted build agents removes the management burden for developers to maintain and update the build agent.
For more information about Azure Pipelines, see What is Azure Pipelines?.

For more information, see Deployment and testing for mission-critical workloads on Azure: Infrastructure-as-Code deployments
Deployment: Zero downtime updates
The zero-downtime update strategy in the reference architecture is central to the overall mission critical application. The methodology of replace instead of upgrade of the stamps ensures a fresh installation of the application into an infrastructure stamp. The reference architecture utilizes a blue/green approach and allows for separate test and development environments.
There are two main components of the reference architecture:
Infrastructure - Azure services and resources. Deployed with Terraform and its associated configuration.
Application - The hosted service or application that serves users. Based on Docker containers and npm built artifacts in HTML and JavaScript for the single-page application (SPA) UI.
In many systems, there's an assumption that application updates are more frequent than infrastructure updates. As a result, different update procedures are developed for each. With a public cloud infrastructure, changes can happen at a faster pace. One deployment process for application updates and infrastructure updates was chosen. One approach ensures infrastructure and application updates are always in sync. This approach allows for:
One consistent process - Fewer chances for mistakes if infrastructure and application updates are mixed together in a release, intentionally or not.
Enables Blue/Green deployment - Every update is deployed using a gradual migration of traffic to the new release.
Easier deployment and debugging of the application - The entire stamp never hosts multiple versions of the application side-by-side.
Simple rollback - Traffic can be switched back to the stamps that run the previous version if errors or issues are encountered.
Elimination of manual changes and configuration drift - Every environment is a fresh deployment.
For more information, see Deployment and testing for mission-critical workloads on Azure: Ephemeral blue/green deployments
Branching strategy
The foundation of the update strategy is the use of branches within the Git repository. The reference architecture uses three types of branches:
| Branch | Description |
|---|---|
feature/* and fix/* |
The entry points for any change. Developers create these branches and should be given a descriptive name, like feature/catalog-update or fix/worker-timeout-bug. When changes are ready to be merged, a pull request (PR) against the main branch is created. At least one reviewer must approve all pull requests. With limited exceptions, every change that is proposed in a PR must run through the end-to-end (E2E) validation pipeline. Developers should use the E2E pipeline to test and debug changes to a complete environment. |
main |
The continuously forward moving and stable branch. Mostly used for integration testing. Changes to main are made only through pull requests. A branch policy prohibits direct writes. Nightly releases against the permanent integration (int) environment are automatically executed from the main branch. The main branch is considered stable. It should be safe to assume that at any given time, a release can be created from it. |
release/* |
Release branches are only created from the main branch. The branches follow the format release/2021.7.X. Branch policies are used so that only repo administrators are allowed to create release/* branches. Only these branches are used to deploy to the prod environment. |
For more information, see Deployment and testing for mission-critical workloads on Azure: Branching strategy
Hotfixes
When a hotfix is required urgently because of a bug or other issue and can't go through the regular release process, a hotfix path is available. Critical security updates and fixes to the user experience that weren't discovered during initial testing are considered valid examples of hotfixes.
The hotfix must be created in a new fix branch and then merged into main using a regular PR. Instead of creating a new release branch, the hotfix is "cherry-picked" into an existing release branch. This branch is already deployed to the prod environment. The CI/CD pipeline that originally deployed the release branch with all the tests is executed again and deploys the hotfix as part of the pipeline.
To avoid major issues, it's important that the hotfix contains a few isolated commits that can easily be cherry-picked and integrated into the release branch. If isolated commits can't be cherry-picked to integrate into the release branch, it's an indication that the change doesn't qualify as a hotfix. Deploy the change as a full new release. Combine it with a rollback to a former stable version until the new release can be deployed.
Deployment: Environments
The reference architecture uses two types of environments for the infrastructure:
Short-lived - The E2E validation pipeline is used to deploy short-lived environments. Short-lived environments are used for pure validation or debugging environments for developers. Validation environments can be created from the
feature/*branch, subjected to tests, and then destroyed if all tests were successful. Debugging environments are deployed in the same way as validation, but aren't destroyed immediately. These environments shouldn't exist for more than a few days and should be deleted when the corresponding PR of the feature branch is merged.Permanent - In the permanent environments there are
integration (int)andproduction (prod)versions. These environments live continuously and aren't destroyed. The environments use fixed domain names likeint.mission-critical.app. In a real world implementation of the reference architecture, astaging(preprod) environment should be added. Thestagingenvironment is used to deploy and validatereleasebranches with the same update process asprod(Blue/Green deployment).Integration (int) - The
intversion is deployed nightly from themainbranch with the same process asprod. The switchover of traffic is faster than the previous release unit. Instead of gradually switching traffic over multiple days, as inprod, the process forintcompletes within a few minutes or hours. This faster switchover ensures the updated environment is ready by the next morning. Old stamps are automatically deleted if all tests in the pipeline are successful.Production (prod) - The
prodversion is only deployed fromrelease/*branches. The traffic switchover uses more granular steps. A manual approval gate is between each step. Each release creates new regional stamps and deploys the new application version to the stamps. Existing stamps aren't touched in the process. The most important consideration forprodis that it should be "always on". No planned or unplanned downtime should ever occur. The only exception is foundational changes to the database layer. A planned maintenance window might be needed.
Deployment: Shared and dedicated resources
The permanent environments (int and prod) within the reference architecture have different types of resources depending on if they're shared with the entire infrastructure or dedicated to an individual stamp. Resources can be dedicated to a particular release and exist only until the next release unit takes over.
Release units
A release unit is several regional stamps per specific release version. Stamps contain all the resources that aren't shared with the other stamps. These resources are virtual networks, Azure Kubernetes Service cluster, Event Hubs, and Azure Key Vault. Azure Cosmos DB and ACR are configured with Terraform data sources.
Globally shared resources
All resources shared between release units are defined in an independent Terraform template. These resources are Front Door, Azure Cosmos DB, Container registry (ACR), and the Log Analytics workspaces and other monitoring-related resources. These resources are deployed before the first regional stamp of a release unit is deployed. The resources are referenced in the Terraform templates for the stamps.
Front Door
While Front Door is a globally shared resource across stamps, its configuration is slightly different than the other global resources. Front Door must be reconfigured after a new stamp is deployed. Front Door must be reconfigured to gradually switch over traffic to the new stamps.
The backend configuration of Front Door can't be directly defined in the Terraform template. The configuration is inserted with Terraform variables. The variable values are constructed before the Terraform deployment is started.
The individual component configuration for the Front Door deployment is defined as:
Frontend - Session affinity is configured to ensure users don't switch between different UI versions during a single session.
Origins - Front Door is configured with two types of origin groups:
An origin group for static storage that serves the UI. The group contains the website storage accounts from all currently active release units. Different weights can be assigned to the origins from different release units to gradually move traffic to a newer unit. Each origin from a release unit should have the same weight assigned.
An origin group for the API, which is hosted on Azure Kubernetes Service. If there are release units with different API versions, then an API origin group exists for each release unit. If all release units offer the same compatible API, all origins are added to the same group and assigned different weights.
Routing rules - There are two types of routing rules:
A routing rule for the UI that is linked to the UI storage origin group.
A routing rule for each API currently supported by the origins. For example:
/api/1.0/*and/api/2.0/*.
If a release introduces a new version of the backend APIs, the changes reflect in the UI that is deployed as part of the release. A specific release of the UI always calls a specific version of the API URL. Users served by a UI version automatically use the respective backend API. Specific routing rules are needed for different instances of the API version. These rules are linked to the corresponding origin groups. If a new API wasn't introduced, all API related routing rules link to the single origin group. In this case, it doesn't matter if a user is served the UI from a different release than the API.
Deployment: Deployment process
A blue/green deployment is the goal of the deployment process. A new release from a release/* branch is deployed into the prod environment. User traffic is gradually shifted to the stamps for the new release.
As a first step in the deployment process of a new version, the infrastructure for the new release unit is deployed with Terraform. Execution of the infrastructure deployment pipeline deploys the new infrastructure from a selected release branch. In parallel to the infrastructure provisioning, the container images are built or imported and pushed to the globally shared container registry (ACR). When the previous processes are completed, the application is deployed to the stamps. From the implementation viewpoint, it's one pipeline with multiple dependent stages. The same pipeline can be re-executed for hotfix deployments.
After the new release unit is deployed and validated, the new unit is added to Front Door to receive user traffic.
A switch/parameter that distinguishes between releases that do and don't introduce a new API version should be planned for. Based on if the release introduces a new API version, a new origin group with the API backends must be created. Alternatively, new API backends can be added to an existing origin group. New UI storage accounts are added to the corresponding existing origin group. Weights for new origins should be set according to the desired traffic split. A new routing rule as described previously must be created that corresponds to the appropriate origin group.
As a part of the addition of the new release unit, the weights of the new origins should be set to the desired minimum user traffic. If no issues are detected, the amount of user traffic should be increased to the new origin group over a period of time. To adjust the weight parameters, the same deployment steps should be executed again with the desired values.
Release unit teardown
As part of the deployment pipeline for a release unit, there's a destroy stage that removes all stamps once a release unit is no longer needed. All traffic is moved to a new release version. This stage includes the removal of release unit references from Front Door. This removal is critical to enable the release of a new version at a later date. Front Door must point to a single release unit in order to be prepared for the next release in the future.
Checklists
As part of the release cadence, a pre and post release checklist should be used. The following example is of items that should be in any checklist at a minimum.
Pre-release checklist - Before starting a release, check the following:
Ensure the latest state of the
mainbranch was successfully deployed to and tested in theintenvironment.Update the changelog file through a PR against the
mainbranch.Create a
release/branch from themainbranch.
Post-release checklist - Before old stamps are destroyed and their references are removed from Front Door, check that:
Clusters are no longer receiving incoming traffic.
Event Hubs and other message queues don't contain any unprocessed messages.
Deployment: Limitations and risks of the update strategy
The update strategy described in this reference architecture has some limitations and risks that should be mentioned:
Higher cost - When releasing updates, many of the infrastructure components are active twice for the release period.
Front Door complexity - The update process in Front Door is complex to implement and maintain. The ability to execute effective blue/green deployments with zero downtime is dependent on it working properly.
Small changes time consuming - The update process results in a longer release process for small changes. This limitation can be partially mitigated with the hotfix process described in the previous section.
Deployment: Application data forward compatibility considerations
The update strategy can support multiple versions of an API and work components executing concurrently. Because Azure Cosmos DB is shared between two or more versions, there's a possibility that data elements changed by one version might not always match the version of the API or workers consuming it. The API layers and workers must implement forward compatibility design. Earlier versions of the API or worker components processes data inserted by a later API or worker component version. It ignores parts it doesn't understand.
Testing
The reference architecture contains different tests used at different stages within the testing implementation.
These tests include:
Unit tests - These tests validate that the business logic of the application works as expected. The reference architecture contains a sample suite of unit tests executed automatically before every container build by Azure Pipelines. If any test fails, the pipeline stops. Build and deployment stops. The developer must fix the issue before the pipeline can be executed again.
Load tests - These tests help to evaluate the capacity, scalability, and potential bottlenecks for a given workload or stack. The reference implementation contains a user load generator to create synthetic load patterns that can be used to simulate real traffic. The load generator can also be used independently of the reference implementation.
Smoke tests - These tests identify if the infrastructure and workload are available and act as expected. Smoke tests are executed as part of every deployment.
UI tests - These tests validate that the user interface was deployed and works as expected. The current implementation only captures screenshots of several pages after deployment without any actual testing.
Failure injection tests - These tests can be automated or executed manually. Automated testing in the architecture integrates Azure Chaos Studio as part of the deployment pipelines.
For more information, see Deployment and testing for mission-critical workloads on Azure: Continuous validation and testing
Testing: Frameworks
The online reference implementation existing testing capabilities and frameworks whenever possible.
| Framework | Test | Description |
|---|---|---|
| NUnit | Unit | This framework is used for unit testing the .NET Core portion of the implementation. Azure Pipelines executes unit tests automatically before container builds. |
| JMeter with Azure Load Testing | Load | Azure Load Testing is a managed service used to execute Apache JMeter load test definitions. |
| Locust | Load | Locust is an open-source load testing framework written in Python. |
| Playwright | UI and Smoke | Playwright is an open source Node.js library to automate Chromium, Firefox, and WebKit with a single API. The Playwright test definition can also be used independently of the reference implementation. |
| Azure Chaos Studio | Failure injection | The reference implementation uses Azure Chaos Studio as an optional step in the E2E validation pipeline to inject failures for resiliency validation. |
Testing: Failure Injection testing and Chaos Engineering
Distributed applications should be resilient to service and component outages. Failure Injection testing (also known as Fault Injection or Chaos Engineering) is the practice of subjecting applications and services to real-world stresses and failures.
Resilience is a property of an entire system and injecting faults helps to find issues in the application. Addressing these issues helps to validate application resiliency to unreliable conditions, missing dependencies and other errors.
Manual and automatic tests can be executed against the infrastructure to find faults and issues in the implementation.
Automatic
The reference architecture integrates Azure Chaos Studio to deploy and run a set of Azure Chaos Studio experiments to inject various faults at the stamp level. Chaos experiments can be executed as an optional part of the E2E deployment pipeline. When the tests are executed, the optional load test is always executed in parallel. The load test is used to create load on the cluster to validate the effect of the injected faults.
Manual
Manual failure injection testing should be done in an E2E validation environment. This environment ensures full representative tests without risk of interference from other environments. Most of the failures generated with the tests can be observed directly in the Application Insights Live metrics view. The remaining failures are available in the Failures view and corresponding log tables. Other failures require deeper debugging such as the use of kubectl to observe the behavior inside of Azure Kubernetes Service.
Two examples of failure injection tests performed against the reference architecture are:
DNS (Domain Name Service) - based failure injection - A test case that can simulate multiple issues. DNS resolution failures due to either the failure of a DNS server or Azure DNS. DNS based testing can help simulate general connections issues between a client and a service, for example when the BackgroundProcessor can't connect to the Event Hubs.
In single-host scenarios, you can modify the local
hostsfile to overwrite DNS resolution. In a larger environment with multiple dynamic servers like AKS, ahostsfile isn't feasible. Azure Private DNS Zones can be used as an alternative to test failure scenarios.Azure Event Hubs and Azure Cosmos DB are two of the Azure services used within the reference implementation that can be used to inject DNS-based failures. Event Hubs DNS resolution can be manipulated with an Azure Private DNS zone tied to the virtual network of one of the stamps. Azure Cosmos DB is a globally replicated service with specific regional endpoints. Manipulation of the DNS records for those endpoints can simulate a failure for a specific region and test the failover of clients.
Firewall blocking - Most Azure services support firewall access restrictions based on virtual networks and/or IP addresses. In the reference infrastructure, these restrictions are used to restrict access to Azure Cosmos DB or Event Hubs. A simple procedure is to remove existing Allow rules or adding new Block rules. This procedure can simulate firewall misconfigurations or service outages.
The following example services in the reference implementation can be tested with a firewall test:
Service Result Key Vault When access to Key Vault is blocked, the most direct effect was the failure of new pods to spawn. The Key Vault CSI driver that fetches secrets on pod startup can't perform its tasks and prevents the pod from starting. Corresponding error messages can be observed with kubectl describe po CatalogService-deploy-my-new-pod -n workload. Existing pods continue to work, although the same error message is observed. The results of the periodic update check for secrets generate the error message. Though untested, executing a deployment doesn't work while Key Vault is inaccessible. Terraform and Azure CLI tasks within the pipeline run makes requests to Key Vault.Event Hubs When access to Event Hubs is blocked, new messages sent by the CatalogService and HealthService fail. Retrievals of messages by the BackgroundProcess slowly fail, with total failure within a few minutes. Azure Cosmos DB Removal of the existing firewall policy for a virtual network results in the Health Service to begin to fail with minimum lag. This procedure only simulates a specific case, an entire Azure Cosmos DB outage. Most failure cases that occur on a regional level are mitigated automatically with transparent failover of the client to a different Azure Cosmos DB region. The DNS-based failure injection testing described previously is a more meaningful test for Azure Cosmos DB. Container registry (ACR) When the access to ACR is blocked, the creation of new pods that are pulled and cached previously on an AKS node continue to work. The creation still works due to the K8s deployment flag pullPolicy=IfNotPresent. Nodes can't spawn a new pod and fails immediately withErrImagePullerrors if the node doesn't pull and cache an image before the block.kubectl describe poddisplays the corresponding403 Forbiddenmessage.AKS ingress Load Balancer The alteration of the inbound rules for HTTP(S)(ports 80 and 443) in the AKS managed Network Security Group (NSG) to Deny results in user or health probe traffic fail to reach the cluster. The test of this failure is difficult to pinpoint the root cause, which was simulated as blockage between the network path of Front Door and a regional stamp. Front Door immediately detects this failure and takes the stamp out of rotation.