Lessons learned
- Ensure all the parties involved understand the difference between High Availability (HA) and Disaster Recovery (DR): a common pitfall is to confuse the two concepts and mismatch the solutions associated with them.
- Discuss with the business stakeholders about their expectations regarding the following aspects to define the recovery point objectives (RPOs) and recovery time objectives (RTOs):
- How much downtime they can tolerate, keeping in mind that usually, the faster the recovery, the higher the cost.
- The type of incidents they want to be protected from, mentioning the related likelihood of such event. For example, the probability of a server going down is higher than a natural disaster that impacts all the datacenters across a region.
- What impact does the system being unavailable has on their business?
- The operational expenses (OPEX) budget for the solution moving forward.
- Consider what degraded service options your end-users can accept. These may include:
- Still having access to visualization dashboards even without the most up-to-date data that is, if the ingestion pipelines don't work, end-users still have access to their data.
- Having read access but no write access.
- Your target RTO and RPO metrics can define what disaster recovery strategy you choose to implement:
- Active/Active.
- Active/Passive.
- Active/Redeploy on disaster.
- Consider your own composite service level objective (SLO) to factor in the tolerable downtimes.
- Ensure you understand all the components that might affect the availability of your systems, such as:
- Identity management.
- Networking topology.
- Secret/key management.
- Data sources.
- Automation/job scheduler.
- Source repository and deployment pipelines (GitHub, Azure DevOps).
- Early detection of outages is also a way to decrease RTO and RPO values significantly. Here are a few aspects that should be covered:
- Define what an outage is and how it maps to Microsoft's definition of an outage. The Microsoft definition is available on the Azure service-level agreement (SLA) page at the product or service level.
- An efficient monitoring and alerting system with accountable teams to review those metrics and alerts in a timely manner helps meet the goal.
- Regarding subscription design, the additional infrastructure for disaster recovery can be stored in the original subscription. platform as a service (PaaS) services like Azure Data Lake Storage Gen2 or Azure Data Factory typically have native features that allow fail over to secondary instances in other regions while staying contained in the original subscription. Some customers might want to consider having a dedicated resource group for resources used only in DR scenarios for cost purposes.
- It should be noted that subscription limits may act as a constraint for this approach.
- Other constraints may include the design complexity and management controls to ensure the DR resource groups aren't used for business-as-usual (BAU) workflows.
- Design the DR workflow based on a solution's criticality and dependencies. For example, don't try to rebuild an Azure Analysis Services instance before your data warehouse is up and running, as it triggers an error. Leave development labs later in the process, recover core enterprise solutions first.
- Try to identify recovery tasks that can be parallelized across solutions, reducing the total RTO.
- If Azure Data Factory is used within a solution, don't forget to include Self-Hosted integration runtimes in the scope. Azure Site Recovery is ideal for those machines.
- Manual operations should be automated as much as possible to avoid human errors, especially when under pressure. It's recommended to:
- Adopt resource provisioning through Bicep, ARM templates or PowerShell scripts.
- Adopt versioning of source code and resource configuration.
- Use CI/CD release pipelines rather than click-ops.
- As you have a plan for failover, you should consider procedures to fallback to the primary instances.
- Define clear indicators and metrics to validate that the failover has been success and solutions are up and running or that the situation is back to normal (also known as primary functional).
- Decide if your service-level agreements (SLAs) should remain the same after a failover or if you allow for degraded service.
- This decision will greatly depend on the business service process being supported. For example, the failover for a room-booking system will look much different than a core operational system.
- An RTO/RPO definition should be based on specific user scenarios rather than at the infrastructure level. Doing so will give you more granularity on what processes and components should be recovered first if there's an outage or disaster.
- Ensure you include capacity checks in the target region before moving forward with a failover: If there's a major disaster, be mindful that many customers will try to failover to the same paired region at the same time, which can cause delays or contention in provisioning the resources.
- If these risks are unacceptable, either an Active/Active or Active/Passive DR strategy should be considered.
- A Disaster Recovery plan should be created and maintained to document the recovery process and the action owners. Also, consider that people might be on leave, so be sure to include secondary contacts.
- Regular disaster recovery drills should be performed to validate the DR plan workflow, that it meets the required RTO/RPO, and to train the responsible teams.
- Data and configuration backups should also be regularly tested to ensure they are "fit for purpose" to support any recovery activities.
- Early collaboration with teams responsible for networking, identity, and resource provisioning will enable agreement on the most optimal solution regarding:
- How to redirect users and traffic from your primary to your secondary site. Concepts such as DNS redirection or the use of specific tooling like Azure Traffic Manager can be evaluated.
- How to provide access and rights to the secondary site in a timely and secure manner.
- During a disaster, effective communication between the many parties involved is key to the efficient and rapid execution of the plan. Teams may include:
- Decision makers.
- Incident response team.
- Affected internal users and teams.
- External teams.
- Orchestration of the different resources at the right time will ensure efficiency in the disaster recovery plan execution.
Considerations
Antipatterns
- Copy/paste this article series This article series is intended to provide guidance to customers looking for the next level of detail for an Azure-specific DR process. As such, it's based upon the generic Microsoft IP and reference architectures rather than any single customer-specific Azure implementation.
While the detail provided will help support a solid foundational understanding, customers must apply their own specific context, implementation, and requirements before obtaining a "fit for purpose" DR strategy and process.
Treating DR as a tech-only process Business stakeholders play a critical role in defining the requirements for DR and completing the business validation steps required to confirm a service recovery. Ensuring that Business stakeholders are engaged across all DR activities will provide a DR process that is "fit for purpose", represents business value, and is executable.
"Set and forget" DR plans Azure is constantly evolving, as are individual customer's use of various components and services. A "fit for purpose" DR process must evolve with them. Either via the software development life cycle (SDLC) process or periodic reviews, customers should regularly revisit their DR plan. The goal is to ensure the validity of the service recovery plan and that any deltas across components, services or solutions have been accounted for.
Paper-based assessments While the end-to-end simulation of a DR event will be difficult across a modern data eco-system, efforts should be made to get as close as possible to a complete simulation across affected components. Regularly scheduled drills will build the "muscle memory" required by the organization to be able to execute the DR plan with confidence.
Relying on Microsoft to do it all Within the Microsoft Azure services, there's a clear division of responsibility, anchored by the cloud service tier used:
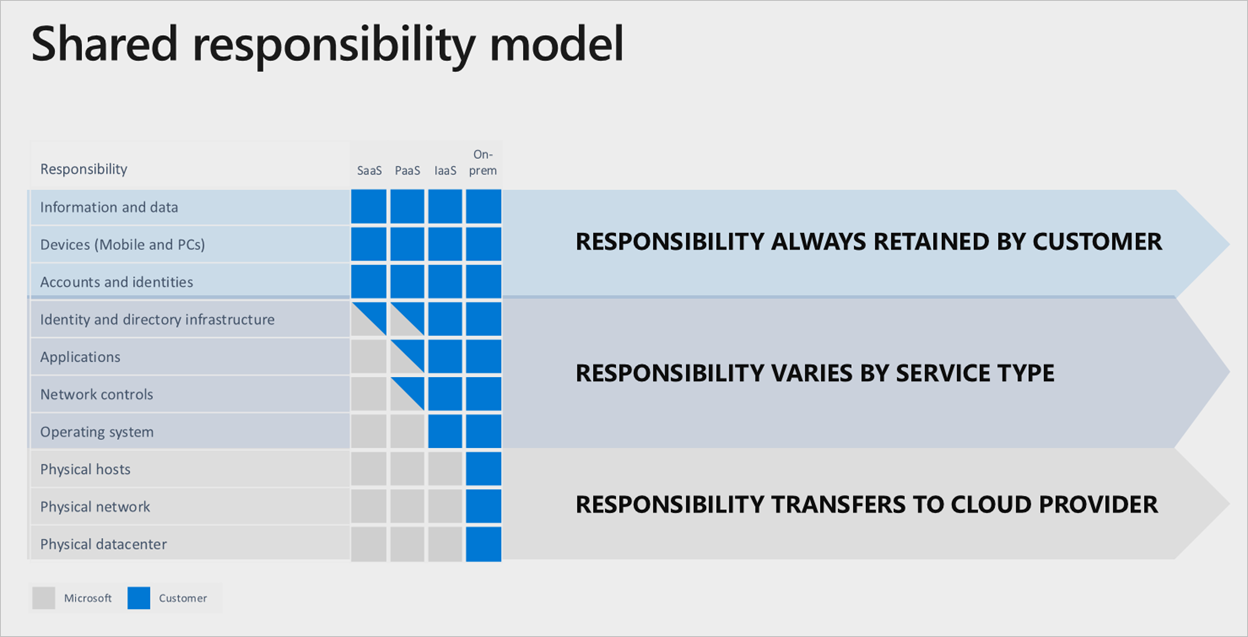 Even if a full software as a service (SaaS) stack is used, the customer will still retain the responsibility to ensure the accounts, identities, and data is correct/up-to-date, along with the devices used to interact with the Azure services.
Even if a full software as a service (SaaS) stack is used, the customer will still retain the responsibility to ensure the accounts, identities, and data is correct/up-to-date, along with the devices used to interact with the Azure services.
Event scope and strategy
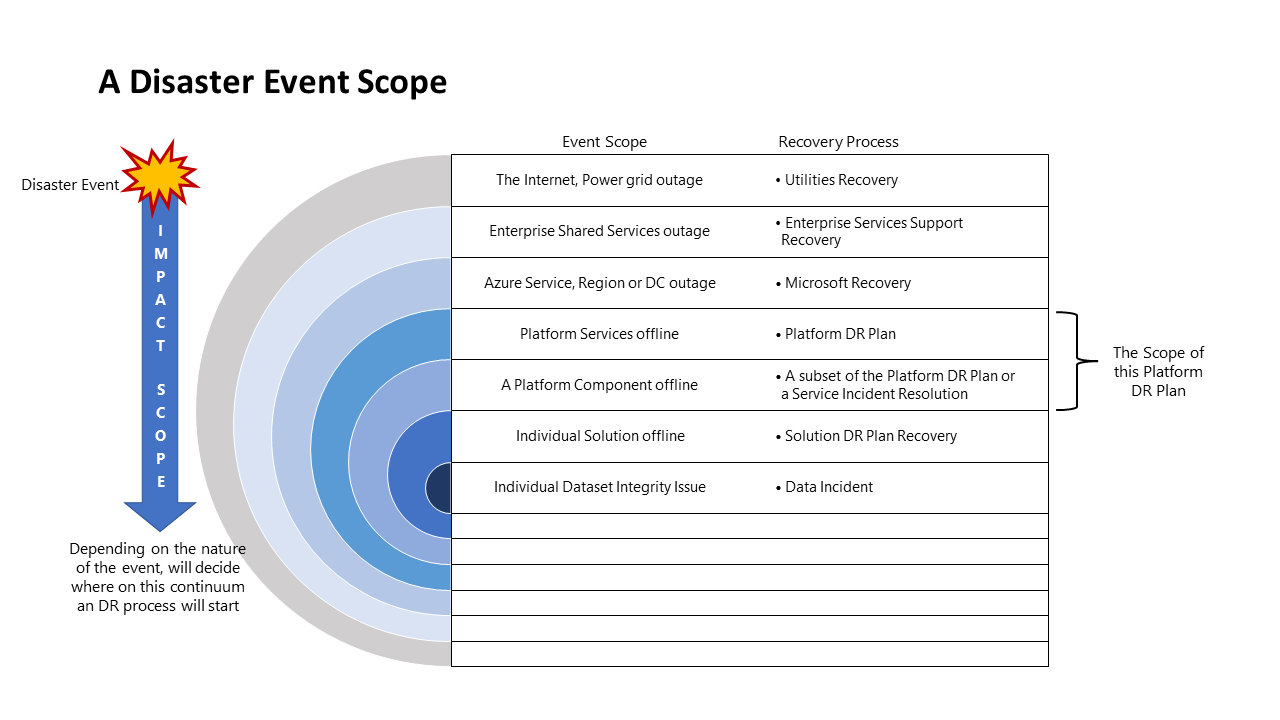
Disaster event scope
Different events will have a different scope of impact and, therefore, a different response. The following diagram illustrates this for a disaster event:
Disaster strategy options
There are four high-level options for a disaster recovery strategy:
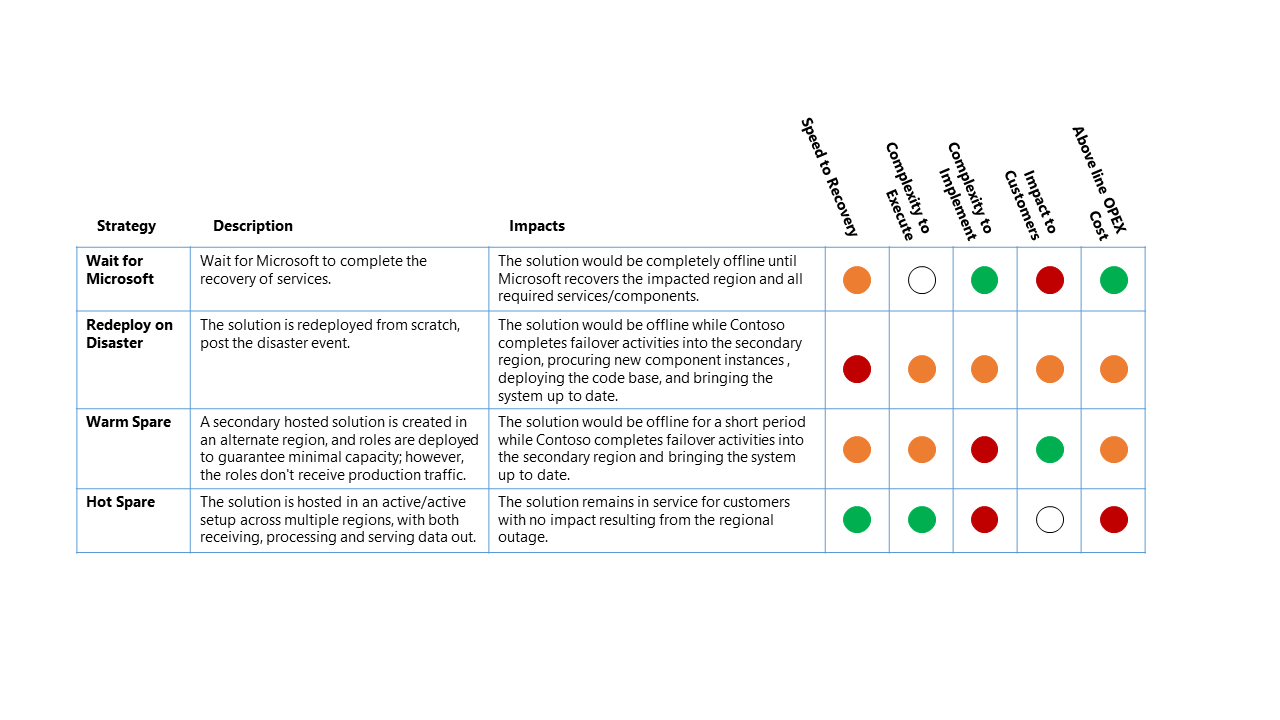
- Wait for Microsoft - As the name suggests, the solution is offline until the complete recovery of services in the affected region by Microsoft. Once recovered, the solution is validated by the customer and then brought up-to-date for service recovery.
- Redeploy on Disaster - The solution is redeployed manually into an available region from scratch, post-disaster event.
- Warm Spare (Active/Passive) - A secondary hosted solution is created in an alternate region, and components are deployed to guarantee minimal capacity; however, the components don't receive production traffic. The secondary services in the alternative region may be "turned off" or running at a lower performance level until such time as a DR event is occurs.
- Hot Spare (Active/Active) - The solution is hosted in an active/active setup across multiple regions. The secondary hosted solution receives, processes, and serves data as part of the larger system.
DR strategy impacts
While the operating cost attributed to the higher levels of service resiliency often dominates the Key Design Decision (KDD) for a DR strategy. There are other important considerations.
Note
Cost Optimization is one of the five pillars of architectural excellence with the Azure Well-Architected Framework. Its goal is to reduce unnecessary expenses and improve operational efficiencies.
The DR scenario for this worked example is a complete Azure regional outage that directly impacts the primary region that hosts the Contoso Data Platform.
For this outage scenario, the relative impact on the four high-level DR Strategies are:
Classification Key
- Recovery time objective (RTO): The expected elapsed time from the disaster event to platform service recovery.
- Complexity to execute: The complexity for the organization to execute the recovery activities.
- Complexity to implement: The complexity for the organization to implement the DR strategy.
- Impact to customers: The direct impact to customers of the data platform service from the DR strategy.
- Above line OPEX cost: The extra cost expected from implementing this strategy like increased monthly billing for Azure for additional components and additional resources required to support.
Note
The above table should be read as a comparison between the options - a strategy that has a green indicator is better for that classification than another strategy with a yellow or red indicator.
Next steps
- Mission-critical workload
- Well-Architected Framework recommendations for designing a disaster recovery strategy