What is conversation transcription multichannel diarization? (preview)
Note
This feature is currently in public preview. This preview is provided without a service-level agreement, and is not recommended for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Conversation transcription multichannel diarization is a speech to text solution that provides real-time or asynchronous transcription of any meeting. This feature combines speech recognition, speaker identification, and sentence attribution to determine who said what, and when, in a meeting.
Important
Conversation transcription multichannel diarization (preview) is retiring on March 28, 2025. For more information about migrating to other speech to text features, see Migrate away from conversation transcription multichannel diarization.
Migrate away from conversation transcription multichannel diarization
Conversation transcription multichannel diarization (preview) is retiring on March 28, 2025.
To continue using speech to text with diarization, use the following features instead:
- Real-time speech to text with diarization
- Fast transcription with diarization
- Batch transcription with diarization
These speech to text features only support diarization for single-channel audio. Multichannel audio that you used with conversation transcription multichannel diarization isn't supported.
Key features
You might find the following features of conversation transcription useful:
- Timestamps: Each speaker utterance has a timestamp, so that you can easily find when a phrase was said.
- Readable transcripts: Transcripts have formatting and punctuation added automatically to ensure the text closely matches what was being said.
- User profiles: User profiles are generated by collecting user voice samples and sending them to signature generation.
- Speaker identification: Speakers are identified by using user profiles, and a speaker identifier is assigned to each.
- Multi-speaker diarization: Determine who said what by synthesizing the audio stream with each speaker identifier.
- Real-time transcription: Provide live transcripts of who is saying what, and when, while the meeting is happening.
- Asynchronous transcription: Provide transcripts with higher accuracy by using a multichannel audio stream.
Note
Although conversation transcription doesn't put a limit on the number of speakers in the room, it's optimized for 2-10 speakers per session.
Use cases
To make meetings inclusive for everyone, such as participants who are deaf and hard of hearing, it's important to have transcription in real-time. Conversation transcription in real-time mode takes meeting audio and determines who is saying what, allowing all meeting participants to follow the transcript and participate in the meeting, without a delay.
Meeting participants can focus on the meeting and leave note-taking to conversation transcription. Participants can actively engage in the meeting and quickly follow up on next steps, using the transcript instead of taking notes and potentially missing something during the meeting.
How it works
The following diagram shows a high-level overview of how the feature works.
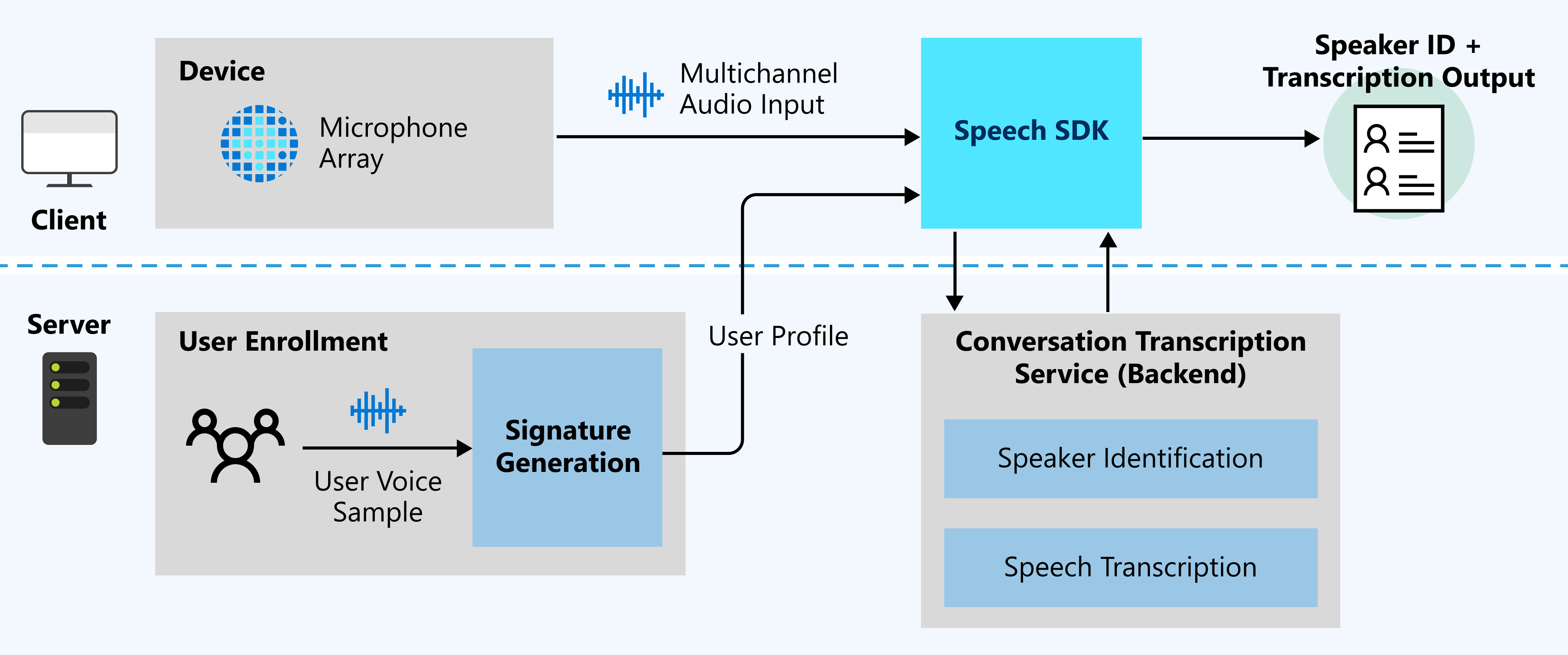
Expected inputs
Conversation transcription uses two types of inputs:
- Multi-channel audio stream: For specification and design details, see Microphone array recommendations.
- User voice samples: Conversation transcription needs user profiles in advance of the conversation for speaker identification. Collect audio recordings from each user, and then send the recordings to the signature generation service to validate the audio and generate user profiles.
User voice samples for voice signatures are required for speaker identification. Speakers who don't have voice samples are recognized as unidentified. Unidentified speakers can still be differentiated when the DifferentiateGuestSpeakers property is enabled (see the following example). The transcription output then shows speakers as, for example, Guest_0 and Guest_1, instead of recognizing them as preenrolled specific speaker names.
config.SetProperty("DifferentiateGuestSpeakers", "true");
Real-time or asynchronous
The following sections provide more detail about transcription modes you can choose.
Real-time
Audio data is processed live to return the speaker identifier and transcript. Select this mode if your transcription solution requirement is to provide meeting participants a live transcript view of their ongoing meeting. For example, building an application to make meetings more accessible to participants with hearing loss or deafness is an ideal use case for real-time transcription.
Asynchronous
Audio data is batch processed to return the speaker identifier and transcript. Select this mode if your transcription solution requirement is to provide higher accuracy, without the live transcript view. For example, if you want to build an application to allow meeting participants to easily catch up on missed meetings, then use the asynchronous transcription mode to get high-accuracy transcription results.
Real-time plus asynchronous
Audio data is processed live to return the speaker identifier and transcript, and, in addition, requests a high-accuracy transcript through asynchronous processing. Select this mode if your application has a need for real-time transcription, and also requires a higher accuracy transcript for use after the meeting occurred.
Language and region support
Currently, conversation transcription supports all speech to text languages in the following regions: centralus, eastasia, eastus, westeurope.