Azure OpenAI Evaluation (Preview)
The evaluation of large language models is a critical step in measuring their performance across various tasks and dimensions. This is especially important for fine-tuned models, where assessing the performance gains (or losses) from training is crucial. Thorough evaluations can help your understanding of how different versions of the model may impact your application or scenario.
Azure OpenAI evaluation enables developers to create evaluation runs to test against expected input/output pairs, assessing the model’s performance across key metrics such as accuracy, reliability, and overall performance.
Evaluations support
Regional availability
- East US2
- North Central US
- Sweden Central
- Switzerland West
Supported deployment types
- Standard
- Provisioned
Evaluation pipeline
Test data
You need to assemble a ground truth dataset that you want to test against. Dataset creation is typically an iterative process that ensures your evaluations remain relevant to your scenarios over time. This ground truth dataset is typically handcrafted and represents the expected behavior from your model. The dataset is also labeled and includes the expected answers.
Note
Some evaluation tests like Sentiment and valid JSON or XML do not require ground truth data.
Your data source needs to be in JSONL format. Below are two examples of the JSONL evaluation datasets:
Evaluation format
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
When you upload and select your evaluation file a preview of the first three lines will be returned:


You can choose any existing previously uploaded datasets, or upload a new dataset.
Generate responses (optional)
The prompt you use in your evaluation should match the prompt you plan to use in production. These prompts provide the instructions for the model to follow. Similar to the playground experiences, you can create multiple inputs to include few-shot examples in your prompt. For more information, see prompt engineering techniques for details on some advanced techniques in prompt design and prompt engineering.
You can reference your input data within the prompts by using the {{input.column_name}} format, where column_name corresponds to the names of the columns in your input file.
Outputs generated during the evaluation will be referenced in subsequent steps using the {{sample.output_text}} format.
Note
You need to use double curly braces to make sure you reference to your data correctly.
Model deployment
As part of creating evaluations you'll pick which models to use when generating responses (optional) as well as which models to use when grading models with specific testing criteria.
In Azure OpenAI you'll be assigning specific model deployments to use as part of your evaluations. You can compare multiple deployments by creating a separate evaluation configuration for each model. This enables you to define specific prompts for each evaluation, providing better control over the variations required by different models.
You can evaluate either a base or a fine-tuned model deployment. The deployments available in your list depend on those you created within your Azure OpenAI resource. If you can't find the desired deployment, you can create a new one from the Azure OpenAI Evaluation page.
Testing criteria
Testing criteria is used to assess the effectiveness of each output generated by the target model. These tests compare the input data with the output data to ensure consistency. You have the flexibility to configure different criteria to test and measure the quality and relevance of the output at different levels.

Getting started
Select the Azure OpenAI Evaluation (PREVIEW) within Azure AI Foundry portal. To see this view as an option may need to first select an existing Azure OpenAI resource in a supported region.
Select New evaluation
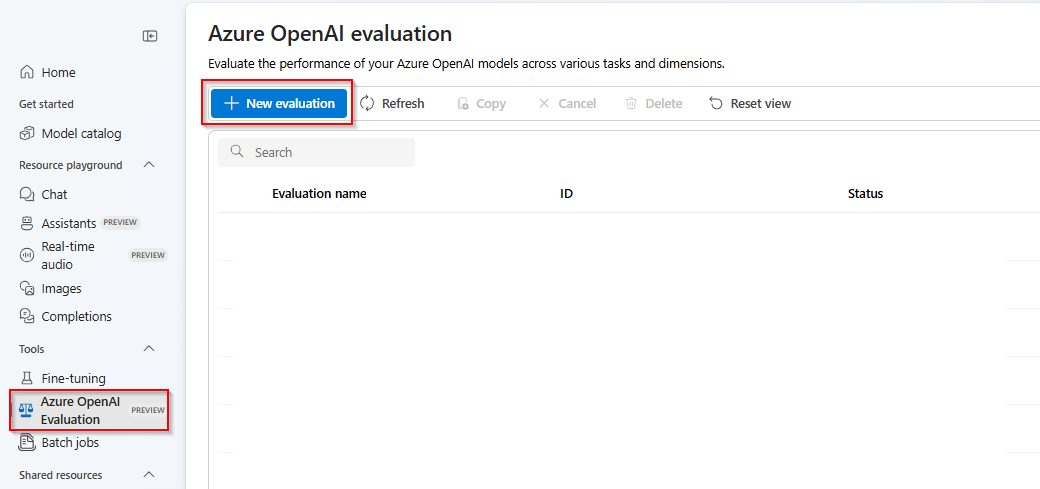
Enter a name of your evaluation. By default a random name is automatically generated unless you edit and replace it. > select Upload new dataset.
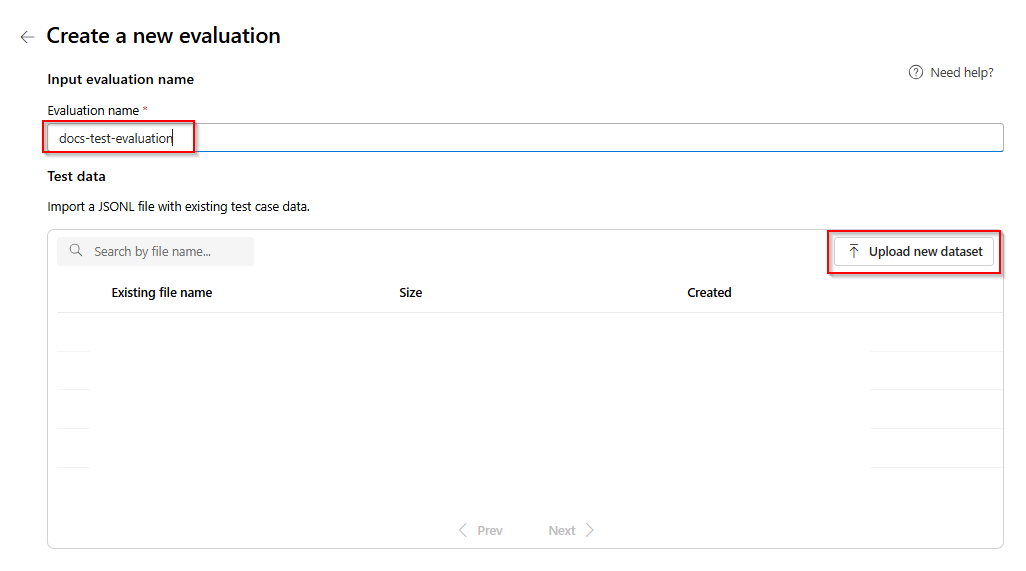
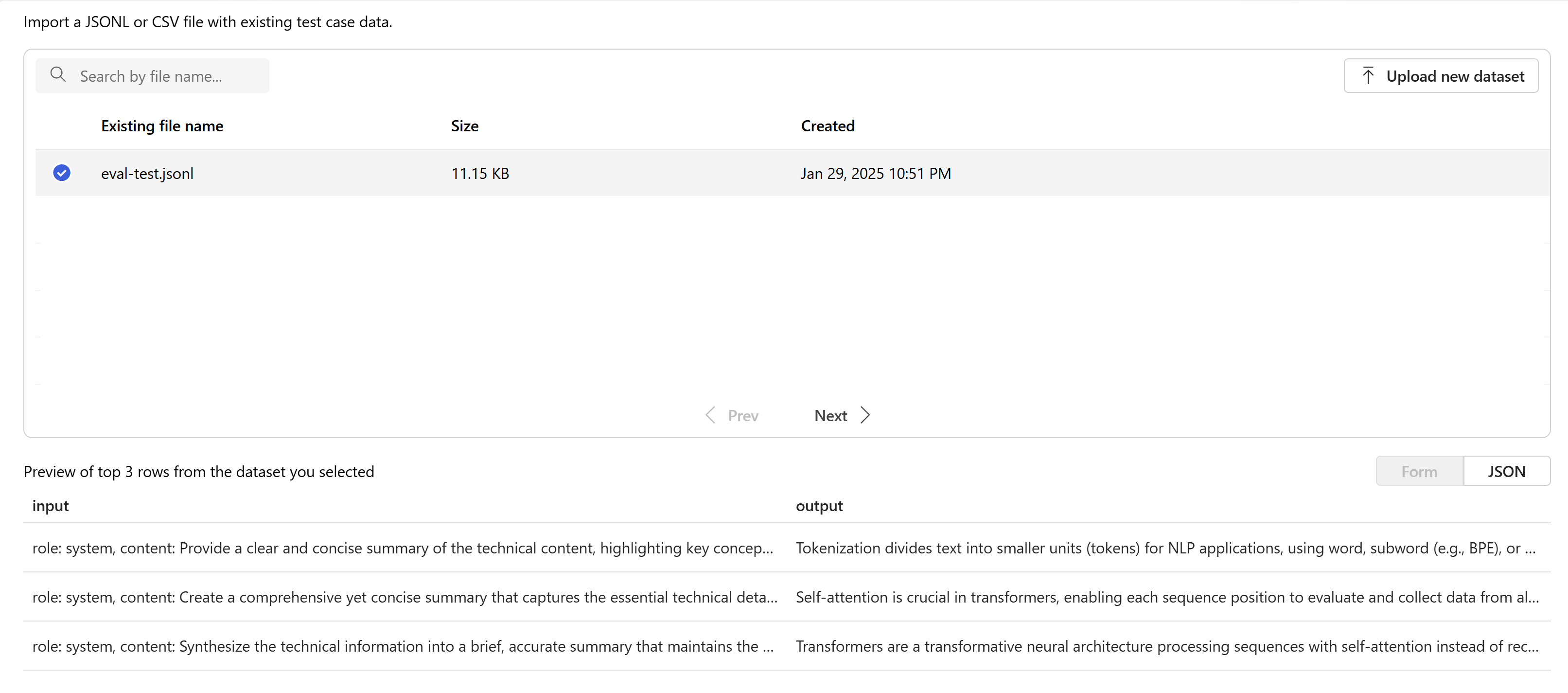
Select your evaluation which will be in
.jsonlformat. If you need a sample test file you can save these 10 lines to a file calledeval-test.jsonl:{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}You'll see the first three lines of the file as a preview:
Select the toggle for Generate responses. Select
{{item.input}}from the dropdown. This will inject the input fields from our evaluation file into individual prompts for a new model run that we want to able to compare against our evaluation dataset. The model will take that input and generate its own unique outputs which in this case will be stored in a variable called{{sample.output_text}}. We'll then use that sample output text later as part of our testing criteria. Alternatively you could provide your own custom system message and individual message examples manually.Select which model you want to generate responses based on your evaluation. If you don't have a model you can create one. For the purpose of this example we're using a standard deployment of
gpt-4o-mini.
The settings/sprocket symbol controls the basic parameters that are passed to the model. Only the following parameters are supported at this time:




- Temperature
- Maximum length
- Top P
Maximum length is currently capped at 2048 regardless of what model you select.
Select Add testing criteria select Add.
Select Semantic Similarity > Under Compare add
{{item.output}}under With add{{sample.output_text}}. This will take the original reference output from your evaluation.jsonlfile and compare it against the output that will be generated by giving the model prompts based on your{{item.input}}.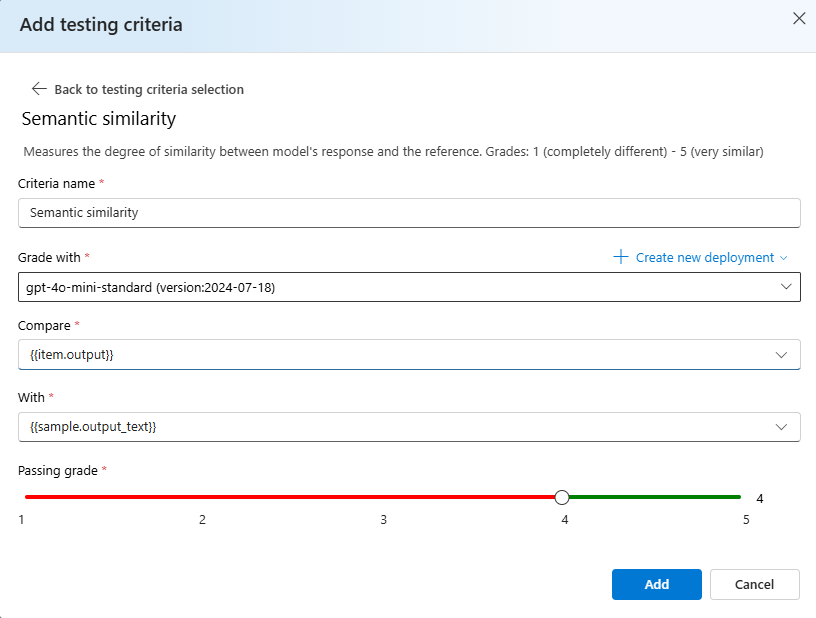
Select Add > at this point you can either add additional testing criteria or you select Create to initiate the evaluation job run.
Once you select Create you'll be taken to a status page for your evaluation job.
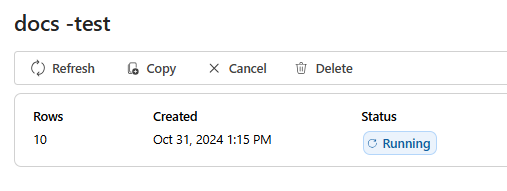
Once your evaluation job has created you can select the job to view the full details of the job:
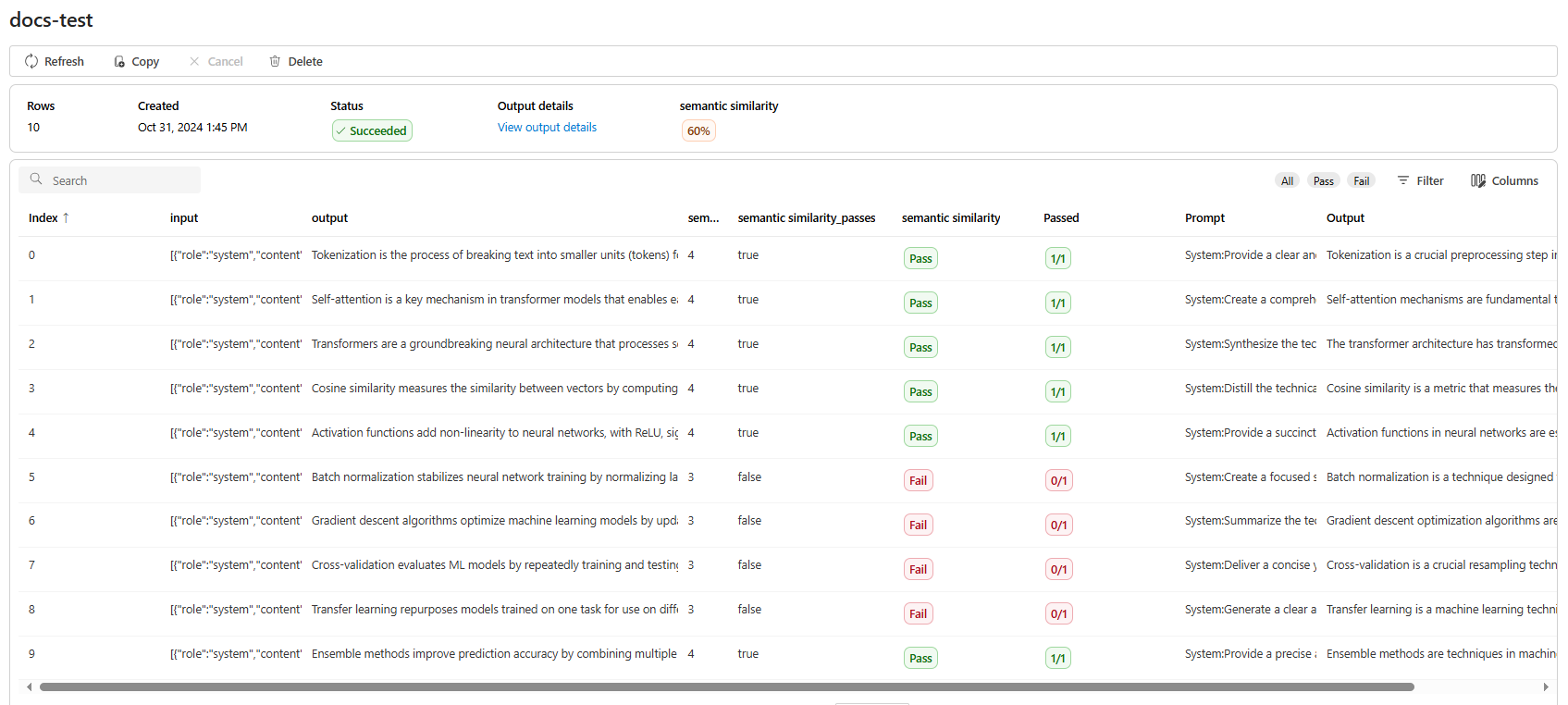
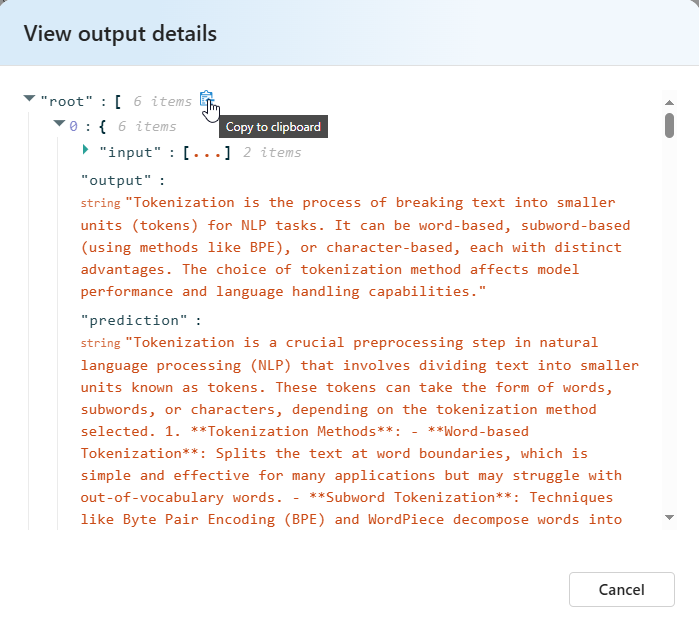
For semantic similarity View output details contains a JSON representation that you can copy/paste of your passing tests.




Testing criteria details
Azure OpenAI Evaluation offers multiple testing criteria options. The section below provides additional details on each option.
Factuality
Assesses the factual accuracy of a submitted answer by comparing it against an expert answer.
Factuality evaluates the factual accuracy of a submitted answer by comparing it to an expert answer. Utilizing a detailed chain-of-thought (CoT) prompt, the grader determines whether the submitted answer is consistent with, a subset of, a superset of, or in conflict with the expert answer. It disregards differences in style, grammar, or punctuation, focusing solely on factual content. Factuality can be useful in many scenarios including but not limited to content verification and educational tools ensuring the accuracy of answers provided by AI.

You can view the prompt text that is used as part of this testing criteria by selecting the dropdown next to the prompt. The current prompt text is:
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
Semantic similarity
Measures the degree of similarity between model's response and the reference. Grades: 1 (completely different) - 5 (very similar).

Sentiment
Attempts to identify the emotional tone of the output.

You can view the prompt text that is used as part of this testing criteria by selecting the dropdown next to the prompt. The current prompt text is:
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
String check
Verifies if the output matches the expected string exactly.

String check performs various binary operations on two string variables allowing for diverse evaluation criteria. It helps with verifying various string relationships, including equality, containment, and specific patterns. This evaluator allows for case-sensitive or case-insensitive comparisons. It also provides specified grades for true or false results, allowing customized evaluation outcomes based on the comparison result. Here's the type of operations supported:
equals: Checks if the output string is exactly equal to the evaluation string.contains: Checks if the evaluation string is a substring of output string.starts-with: Checks if the output string starts with the evaluation string.ends-with: Checks if the output string ends with the evaluation string.
Note
When setting certain parameters in your testing criteria, you have the option to choose between the variable and the template. Select variable if you want to refer to a column in your input data. Choose template if you want to provide a fixed string.
Valid JSON or XML
Verifies if the output is valid JSON or XML.

Matches schema
Ensures the output follows the specified structure.

Criteria match
Assess if model's response matches your criteria. Grade: Pass or Fail.

You can view the prompt text that is used as part of this testing criteria by selecting the dropdown next to the prompt. The current prompt text is:
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
Text quality
Evaluate quality of text by comparing to reference text.

Summary:
- BLEU Score: Evaluates the quality of generated text by comparing it against one or more high-quality reference translations using the BLEU score.
- ROUGE Score: Evaluates the quality of generated text by comparing it to reference summaries using ROUGE scores.
- Cosine: Also referred to as cosine similarity measures how closely two text embeddings—such as model outputs and reference texts—align in meaning, helping assess the semantic similarity between them. This is done by measuring their distance in vector space.
Details:
BLEU (BiLingual Evaluation Understudy) score is commonly used in natural language processing (NLP) and machine translation. It's widely used in text summarization and text generation use cases. It evaluates how closely the generated text matches the reference text. The BLEU score ranges from 0 to 1, with higher scores indicating better quality.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a set of metrics used to evaluate automatic summarization and machine translation. It measures the overlap between generated text and reference summaries. ROUGE focuses on recall-oriented measures to assess how well the generated text covers the reference text. The ROUGE score provides various metrics, including: • ROUGE-1: Overlap of unigrams (single words) between generated and reference text. • ROUGE-2: Overlap of bigrams (two consecutive words) between generated and reference text. • ROUGE-3: Overlap of trigrams (three consecutive words) between generated and reference text. • ROUGE-4: Overlap of four-grams (four consecutive words) between generated and reference text. • ROUGE-5: Overlap of five-grams (five consecutive words) between generated and reference text. • ROUGE-L: Overlap of L-grams (L consecutive words) between generated and reference text. Text summarization and document comparison are among optimal use cases for ROUGE, particularly in scenarios where text coherence and relevance are critical.
Cosine similarity measures how closely two text embeddings—such as model outputs and reference texts—align in meaning, helping assess the semantic similarity between them. Same as other model-based evaluators, you need to provide a model deployment using for evaluation.
Important
Only embedding models are supported for this evaluator:
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
Custom prompt
Uses the model to classify the output into a set of specified labels. This evaluator uses a custom prompt that you'll need to define.
