How to use native document summarization (preview)
Important
- Azure AI Language public preview releases provide early access to features that are in active development.
- Features, approaches, and processes may change, before General Availability (GA), based on user feedback.
Azure AI Language is a cloud-based service that applies Natural Language Processing (NLP) features to text-based data. Document summarization uses natural language processing to generate extractive (salient sentence extraction) or abstractive (contextual word extraction) summaries for documents. Both AbstractiveSummarization and ExtractiveSummarization APIs support native document processing. A native document refers to the file format used to create the original document such as Microsoft Word (docx) or a portable document file (pdf). Native document support eliminates the need for text preprocessing before using Azure AI Language resource capabilities. The native document support capability enables you to send API requests asynchronously, using an HTTP POST request body to send your data and HTTP GET request query string to retrieve the status results. Your processed documents are located in your Azure Blob Storage target container.
Supported document formats
Applications use native file formats to create, save, or open native documents. Currently PII and Document summarization capabilities supports the following native document formats:
| File type | File extension | Description |
|---|---|---|
| Text | .txt |
An unformatted text document. |
| Adobe PDF | .pdf |
A portable document file formatted document. |
| Microsoft Word | .docx |
A Microsoft Word document file. |
Input guidelines
Supported file formats
| Type | support and limitations |
|---|---|
| PDFs | Fully scanned PDFs aren't supported. |
| Text within images | Digital images with embedded text aren't supported. |
| Digital tables | Tables in scanned documents aren't supported. |
Document Size
| Attribute | Input limit |
|---|---|
| Total number of documents per request | ≤ 20 |
| Total content size per request | ≤ 10 MB |
Include native documents with an HTTP request
Let's get started:
For this project, we use the cURL command line tool to make REST API calls.
Note
The cURL package is preinstalled on most Windows 10 and Windows 11 and most macOS and Linux distributions. You can check the package version with the following commands: Windows:
curl.exe -VmacOScurl -VLinux:curl --versionIf cURL isn't installed, here are installation links for your platform:
An active Azure account. If you don't have one, you can create a free account.
An Azure Blob Storage account. You also need to create containers in your Azure Blob Storage account for your source and target files:
- Source container. This container is where you upload your native files for analysis (required).
- Target container. This container is where your analyzed files are stored (required).
A single-service Language resource (not a multi-service Azure AI services resource):
Complete the Language resource project and instance details fields as follows:
Subscription. Select one of your available Azure subscriptions.
Resource Group. You can create a new resource group or add your resource to a preexisting resource group that shares the same lifecycle, permissions, and policies.
Resource Region. Choose Global unless your business or application requires a specific region. If you're planning on using a system-assigned managed identity for authentication, choose a geographic region like West US.
Name. Enter the name you chose for your resource. The name you choose must be unique within Azure.
Pricing tier. You can use the free pricing tier (
Free F0) to try the service, and upgrade later to a paid tier for production.Select Review + Create.
Review the service terms and select Create to deploy your resource.
After your resource successfully deploys, select Go to resource.
Retrieve your key and language service endpoint
Requests to the Language service require a read-only key and custom endpoint to authenticate access.
If you created a new resource, after it deploys, select Go to resource. If you have an existing language service resource, navigate directly to your resource page.
In the left rail, under Resource Management, select Keys and Endpoint.
You can copy and paste your
keyand yourlanguage service instance endpointinto the code samples to authenticate your request to the Language service. Only one key is necessary to make an API call.
Create Azure Blob Storage containers
Create containers in your Azure Blob Storage account for source and target files.
- Source container. This container is where you upload your native files for analysis (required).
- Target container. This container is where your analyzed files are stored (required).
Authentication
Your Language resource needs granted access to your storage account before it can create, read, or delete blobs. There are two primary methods you can use to grant access to your storage data:
Shared access signature (SAS) tokens. User delegation SAS tokens are secured with Microsoft Entra credentials. SAS tokens provide secure, delegated access to resources in your Azure storage account.
Managed identity role-based access control (RBAC). Managed identities for Azure resources are service principals that create a Microsoft Entra identity and specific permissions for Azure managed resources.
For this project, we authenticate access to the source location and target location URLs with Shared Access Signature (SAS) tokens appended as query strings. Each token is assigned to a specific blob (file).

- Your source container or blob must designate read and list access.
- Your target container or blob must designate write and list access.
The extractive summarization API uses natural language processing techniques to locate key sentences in an unstructured text document. These sentences collectively convey the main idea of the document.
Extractive summarization returns a rank score as a part of the system response along with extracted sentences and their position in the original documents. A rank score is an indicator of how relevant a sentence is determined to be, to the main idea of a document. The model gives a score between 0 and 1 (inclusive) to each sentence and returns the highest scored sentences per request. For example, if you request a three-sentence summary, the service returns the three highest scored sentences.
There's another feature in Azure AI Language, key phrase extraction, that can extract key information. To decide between key phrase extraction and extractive summarization, here are helpful considerations:
- Key phrase extraction returns phrases while extractive summarization returns sentences.
- Extractive summarization returns sentences together with a rank score, and top ranked sentences are returned per request.
- Extractive summarization also returns the following positional information:
- Offset: The start position of each extracted sentence.
- Length: The length of each extracted sentence.
Determine how to process the data (optional)
Submitting data
You submit documents to the API as strings of text. Analysis is performed upon receipt of the request. Because the API is asynchronous, there might be a delay between sending an API request, and receiving the results.
When you use this feature, the API results are available for 24 hours from the time the request was ingested, and is indicated in the response. After this time period, the results are purged and are no longer available for retrieval.
Getting text summarization results
When you get results from language detection, you can stream the results to an application or save the output to a file on the local system.
Here's an example of content you might submit for summarization, which is extracted using the Microsoft blog article A holistic representation toward integrative AI. This article is only an example. The API can accept longer input text. For more information, see data and service limits.
"At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality. In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there's magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multi-sensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks."
The text summarization API request is processed upon receipt of the request by creating a job for the API backend. If the job succeeded, the output of the API is returned. The output is available for retrieval for 24 hours. After this time, the output is purged. Due to multilingual and emoji support, the response might contain text offsets. For more information, see how to process offsets.
When you use the preceding example, the API might return these summarized sentences:
Extractive summarization:
- "At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding."
- "We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages."
- "The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today."
Abstractive summarization:
- "Microsoft is taking a more holistic, human-centric approach to learning and understanding. We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. Over the past five years, we have achieved human performance on benchmarks in."
Try text extractive summarization
You can use text extractive summarization to get summaries of articles, papers, or documents. To see an example, see the quickstart article.
You can use the sentenceCount parameter to guide how many sentences are returned, with 3 being the default. The range is from 1 to 20.
You can also use the sortby parameter to specify in what order the extracted sentences are returned - either Offset or Rank, with Offset being the default.
| parameter value | Description |
|---|---|
| Rank | Order sentences according to their relevance to the input document, as decided by the service. |
| Offset | Keeps the original order in which the sentences appear in the input document. |
Try text abstractive summarization
The following example gets you started with text abstractive summarization:
- Copy the following command into a text editor. The BASH example uses the
\line continuation character. If your console or terminal uses a different line continuation character, use that character instead.
curl -i -X POST https://<your-language-resource-endpoint>/language/analyze-text/jobs?api-version=2023-04-01 \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>" \
-d \
'
{
"displayName": "Text Abstractive Summarization Task Example",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en",
"text": "At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality. In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there's magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multi-sensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks."
}
]
},
"tasks": [
{
"kind": "AbstractiveSummarization",
"taskName": "Text Abstractive Summarization Task 1",
}
]
}
'
Make the following changes in the command where needed:
- Replace the value
your-language-resource-keywith your key. - Replace the first part of the request URL
your-language-resource-endpointwith your endpoint URL.
- Replace the value
Open a command prompt window (for example: BASH).
Paste the command from the text editor into the command prompt window, then run the command.
Get the
operation-locationfrom the response header. The value looks similar to the following URL:
https://<your-language-resource-endpoint>/language/analyze-text/jobs/12345678-1234-1234-1234-12345678?api-version=2022-10-01-preview
- To get the results of the request, use the following cURL command. Be sure to replace
<my-job-id>with the numerical ID value you received from the previousoperation-locationresponse header:
curl -X GET https://<your-language-resource-endpoint>/language/analyze-text/jobs/<my-job-id>?api-version=2022-10-01-preview \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>"
Abstractive text summarization example JSON response
{
"jobId": "cd6418fe-db86-4350-aec1-f0d7c91442a6",
"lastUpdateDateTime": "2022-09-08T16:45:14Z",
"createdDateTime": "2022-09-08T16:44:53Z",
"expirationDateTime": "2022-09-09T16:44:53Z",
"status": "succeeded",
"errors": [],
"displayName": "Text Abstractive Summarization Task Example",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "AbstractiveSummarizationLROResults",
"taskName": "Text Abstractive Summarization Task 1",
"lastUpdateDateTime": "2022-09-08T16:45:14.0717206Z",
"status": "succeeded",
"results": {
"documents": [
{
"summaries": [
{
"text": "Microsoft is taking a more holistic, human-centric approach to AI. We've developed a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We've achieved human performance on benchmarks in conversational speech recognition, machine translation, ...... and image captions.",
"contexts": [
{
"offset": 0,
"length": 247
}
]
}
],
"id": "1"
}
],
"errors": [],
"modelVersion": "latest"
}
}
]
}
}
| parameter | Description |
|---|---|
-X POST <endpoint> |
Specifies your Language resource endpoint for accessing the API. |
--header Content-Type: application/json |
The content type for sending JSON data. |
--header "Ocp-Apim-Subscription-Key:<key> |
Specifies the Language resource key for accessing the API. |
-data |
The JSON file containing the data you want to pass with your request. |
The following cURL commands are executed from a BASH shell. Edit these commands with your own resource name, resource key, and JSON values. Try analyzing native documents by selecting the Personally Identifiable Information (PII) or Document Summarization code sample project:
Summarization sample document
For this project, you need a source document uploaded to your source container. You can download our Microsoft Word sample document or Adobe PDF for this quickstart. The source language is English.
Build the POST request
Using your preferred editor or IDE, create a new directory for your app named
native-document.Create a new json file called document-summarization.json in your native-document directory.
Copy and paste the Document Summarization request sample into your
document-summarization.jsonfile. Replace{your-source-container-SAS-URL}and{your-target-container-SAS-URL}with values from your Azure portal Storage account containers instance:
Request sample
{
"tasks": [
{
"kind": "ExtractiveSummarization",
"parameters": {
"sentenceCount": 6
}
}
],
"analysisInput": {
"documents": [
{
"source": {
"location": "{your-source-blob-SAS-URL}"
},
"targets": {
"location": "{your-target-container-SAS-URL}"
}
}
]
}
}
Run the POST request
Before you run the POST request, replace {your-language-resource-endpoint} and {your-key} with the endpoint value from your Azure portal Language resource instance.
Important
Remember to remove the key from your code when you're done, and never post it publicly. For production, use a secure way of storing and accessing your credentials like Azure Key Vault. For more information, see Azure AI services security.
PowerShell
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" -i -X POST --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
command prompt / terminal
curl -v -X POST "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
Sample response:
HTTP/1.1 202 Accepted
Content-Length: 0
operation-location: https://{your-language-resource-endpoint}/language/analyze-documents/jobs/f1cc29ff-9738-42ea-afa5-98d2d3cabf94?api-version=2024-11-15-preview
apim-request-id: e7d6fa0c-0efd-416a-8b1e-1cd9287f5f81
x-ms-region: West US 2
Date: Thu, 25 Jan 2024 15:12:32 GMT
POST response (jobId)
You receive a 202 (Success) response that includes a read-only Operation-Location header. The value of this header contains a jobId that can be queried to get the status of the asynchronous operation and retrieve the results using a GET request:
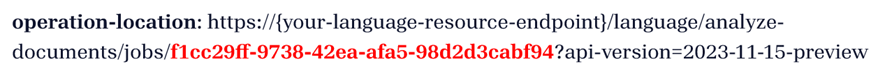
Get analyze results (GET request)
After your successful POST request, poll the operation-location header returned in the POST request to view the processed data.
Here's the structure of the GET request:
GET {cognitive-service-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-previewBefore you run the command, make these changes:
Replace {jobId} with the Operation-Location header from the POST response.
Replace {your-language-resource-endpoint} and {your-key} with the values from your Language service instance in the Azure portal.
Get request
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" -i -X GET --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
curl -v -X GET "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
Examine the response
You receive a 200 (Success) response with JSON output. The status field indicates the result of the operation. If the operation isn't complete, the value of status is "running" or "notStarted", and you should call the API again, either manually or through a script. We recommend an interval of one second or more between calls.
Sample response
{
"jobId": "f1cc29ff-9738-42ea-afa5-98d2d3cabf94",
"lastUpdatedDateTime": "2024-01-24T13:17:58Z",
"createdDateTime": "2024-01-24T13:17:47Z",
"expirationDateTime": "2024-01-25T13:17:47Z",
"status": "succeeded",
"errors": [],
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "ExtractiveSummarizationLROResults",
"lastUpdateDateTime": "2024-01-24T13:17:58.33934Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "doc_0",
"source": {
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-input/input.pdf"
},
"targets": [
{
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-output/df6611a3-fe74-44f8-b8d4-58ac7491cb13/ExtractiveSummarization-0001/input.result.json"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2023-02-01-preview"
}
}
]
}
}
Upon successful completion:
- The analyzed documents can be found in your target container.
- The successful POST method returns a
202 Acceptedresponse code indicating that the service created the batch request. - The POST request also returned response headers including
Operation-Locationthat provides a value used in subsequent GET requests.
Clean up resources
If you want to clean up and remove an Azure AI services subscription, you can delete the resource or resource group. Deleting the resource group also deletes any other resources associated with it.