SQL Server 2012 Data Quality Services (DQS) for Testing Teams
AUTHORS:
Raj Kamal, Test Consultant (rajkamal@microsoft.com)
Gunjan Jain, Associate Test Consultant (gunjain@microsoft.com)
Getting Started
Testing activities have sadly become more of verifying that every “t” is crossed and every “i" is dotted, while they should ideally be focusing on ascertaining the viability of the word thus formed. Within testing itself, data is an important spoke in the wheel – without good test data you are not really testing all the conditions for failure and it will take you off-guard at later point when it happens in production.
Quality of data is critical to Quality of Service (QoS) provided by applications. Having Bad or Incomplete data sometime can be more damaging than having no data at all. Poor data quality can seriously hinder or damage the efficiency and effectiveness of organizations and businesses. If not identified and corrected early on, defective data can contaminate all downstream systems and information assets which will have a strong cascading effect. The growing awareness of such repercussions has led to major public initiatives like the “Data Quality Act” in the USA and the “European 2003/98” directive of the European Parliament. Enterprises must present data that meet very stringent data quality levels, especially in the light of recent compliance regulations standards.
If we wait until wrong decisions are made by customers relying on the bad or inaccurate data - we are in trouble. Data quality is often overlooked and yet there is no well-defined testing process or that provides guidance around ways to improve, maintain and monitor the data quality in any data-centric project. However the bad times are now over and with our own SQL Server 2012 DQS we can turn the tables around. This artifact will show you how.
But before we go down any further, we want to take this opportunity to make it very clear that this work is not to talk/evangelize SQL Server 2012 DQS features but to exhibit how they can be leveraged by QA/Test team making use of exciting customer assisting knowledge discovery from data, domain values
In its latest avatar, Microsoft SQL Server 2012 takes on the onus of ensuring the following:
- Knowledge Management, which involves creating and maintaining a Data Quality Knowledge Base (DQKB), is including supporting ‘knowledge discovery’ – an automated computer-assisted acquisition of knowledge from a data source sample, that is reused for performing various data quality operations, such as data cleansing and matching.
- Data Quality Projects, which enable correcting, standardizing and matching source data according to domain values, rules and reference data associated with a designated.
- Administration with regards to monitoring the current and past DQ processes and defining the various parameters governing the overall DQ activities in server. The main concept behind DQS is a rapid, easy-to-deploy, and easy-to-use data quality system that can be set up and used practically in minutes. DQS is applicable across different scenarios by providing.
The main concept behind DQS is a rapid, easy-to-deploy, and easy-to-use data quality system that can be set up and used practically in minutes. DQS is applicable across different scenarios by providing customers with capabilities that help improve the quality of their data. Data is usually generated by multiple systems and parties across organizational and geographic boundaries and often contains inaccurate, incomplete or stale data elements
The following (Table-1) scenarios are the data quality problems addressed by DQS in SQL Server "SQL Server 2012" that are typical candidates for Test Scenarios for data centric project.
Data Quality Issue |
Description |
||||||||||||||||||||
Completeness |
Is all the required information available? Are data values missing, or in an unusable state? In some cases, missing data is irrelevant, but when the information that is missing is critical to a specific business process, completeness becomes an issue. |
||||||||||||||||||||
Conformity |
Are there expectations that data values conform to specified formats? If so, do all the values conform to these formats? Maintaining conformance to specific formats is important in data representation, presentation, aggregate reporting, search, and establishing key relationships. |
||||||||||||||||||||
Consistency |
Do values represent the same meaning? |
||||||||||||||||||||
Accuracy |
Do data objects accurately represent the “real-world” values they are expected to model? Incorrect spellings of product or person names, addresses, and even untimely or not current data can impact operational and analytical applications. |
||||||||||||||||||||
Validity |
Do data values fall within acceptable ranges? |
||||||||||||||||||||
Duplication |
Are there multiple, unnecessary representations of the same data objects within your data set? The inability to maintain a single representation for each entity across your systems poses numerous vulnerabilities and risks. Duplicates are measured as a percentage of the overall number of records. There can be duplicate individuals, companies, addresses, product lines, invoices and so on. The following example depicts duplicate records existing in a data set:
|
* Sourced from DQS FAQs
The DQS knowledge base approach enables the organization, through its data experts; to efficiently capture and refine the data quality related knowledge in a Data Quality Knowledge Base (DQKB).
So that brings us to DQKB, what exactly is this thing? Well, DQS is a knowledge-driven solution, and in its heart resides the DQKB. A DQKB stores all the knowledge related to some specific type of data sources, and is maintained by the organization’s data expert (often referred to as a data steward). For example, one DQKB can handle information on an organization’s customer database, while another can handle employees’ database.
The DQKB contains data domains that relate to the data source (for example: name, city, state, zip code, ID). For each data domain, the DQKB stores all identified terms, spelling errors, validation and business rules, and reference data that can be used to perform data quality actions on the data source.
Test Teams & DQS: The ‘π’ Matrix
Indeed, with all above, we can actually help communities like the Test Teams do great stuff on data quality. Elaborated are the ways and means for accelerated adoption of SQL Server 2012 DQS in testing life cycle. We are particularly looking at adoption of DQS in a more pronounced way within the testing community, largely due to their active involvement in quality assurance tasks pertaining to data quality as well as the bouquet of features SQL Server 2012 brings to the table for the same.
The ‘π’ Matrix is nothing but a Phase V/s Issue Matrix (hence ‘PI’) indicating various states a project can be in depending on the amount of Data Quality issues encountered and the stage in the Test Execution Cycle.

As indicated in the above diagram, we have four sets of teams with respect to their state of data quality in projects. The Superstars, to begin with, are already a lot which is basking in the glory of a job well done – it is this state the other three need to aim for.
The Flyers on the other hand, are having an ideal platform to move to the Superstars category should they continue to focus attention on Data Quality. The usual bane in this situation is that of complacency or other forms which all eventually lead to a lack of focus on Data Quality – this is what ideally forms the mantra for teams in this quadrant; continue their focus on Data Quality.
The teams tagged in Traps are primarily projects where bugs have piled up in the early stages of testing itself arising out of bad data quality. Since Traps are observed at early stages of test execution cycle, by providing a renewed focus on Data Quality checks, these can be effectively countered. Negligence can otherwise pretty much move them into the Nightmare quadrant. It would be worthwhile to identify a few ways in which Traps can gradually move into Superstars.
- Since DQ issues are observed at early stages in test execution which result into bugs stacks, immediate cleansing of the data is advised before aggravating the damage – this is essentially the ‘damage control’ part.
- Client should be informed about the data quality (if data is provided by the client) and should also be informed about the risk of having faulty data in the system. This is the ‘alerting’ part of the steps.
-It should be kept in mind that if DQ issues are not fixed until the UAT phase, client satisfaction will take a beating and this will have a direct impact on the rapport of the company
-Lastly, due to data issues, many bugs can remain uncovered. It is suggested that DQ implementation should be part of test planning once data issues are observed in PoC phase to avoid major pitfalls later.
The last quadrant talks of ‘The Nightmares’ which pretty much signal a project gone awry due to data quality issues. In these cases, DQ issues are observed very late in the test execution cycle.
- Once you are in Nightmare, please understand, it is almost impossible to move into Superstar quadrant. It is clearly because of lack of DQ implementation at early stages that the project has taken a beating.
- One should take a lesson from the failure and learn to religiously add DQ implementation right from the planning phase of the next release including DQ implementation as part of the scope, design and testing. Measuring & monitoring DQ on daily/weekly basis and taking actions against important DQ issues to fix them early has already been suggested.
- Teams assume that Data quality is only important for Business Intelligence and Data Warehousing projects and we are not applicable
Data Quality Testing – Why it’s not popular?
- Lot of emphasis goes on testing UI and the code / logic / business rules but data is treated as a second class citizen
- DQ until recently didn’t get its due attention and hence was ignored and unfashionable
- Lack of Testing Tools to do it (Well, just wait, now there is one)
- Lack of skillset (our Testers are traditionally trained in testing APIs or functional aspects of applications more than the data flowing through it)
- Even if teams wants to do it, there is no good guidance/documentation around it
- The effort required to test data quality is often underestimated
DQS Test Planning
Prerequisites:
1. SQL Server 2012 RC0 – DQSInstaller.exe should be available.
Please refer installation instructions from DQS Forum.
2. Sample Database (Refer next page for the sample DB used in this document.) By sample DB we mean here is the database required to be cleansed. It could be your client data or sample of client data.
In this document, the objective is to demonstrate how DQS can be used by Test team as a weapon in their arsenal to uncover DQ issues more proactively.
This document will be covering the basic and typical data issues like valid data, standard, duplicate data, and spell check.
For ease of understanding and to reduce the complexity, we have created 2 sample Databases with different data quality issues intentionally added which are shown below in tables.

Sample DB -1 having following DQ Requirements from Business/Customer
1. As per business requirement, Gender should be either male or female. Any other value is not acceptable.
2. Age should be between 21 and 30.
3. Duplicate rows

Sample DB -2 where data has following issues
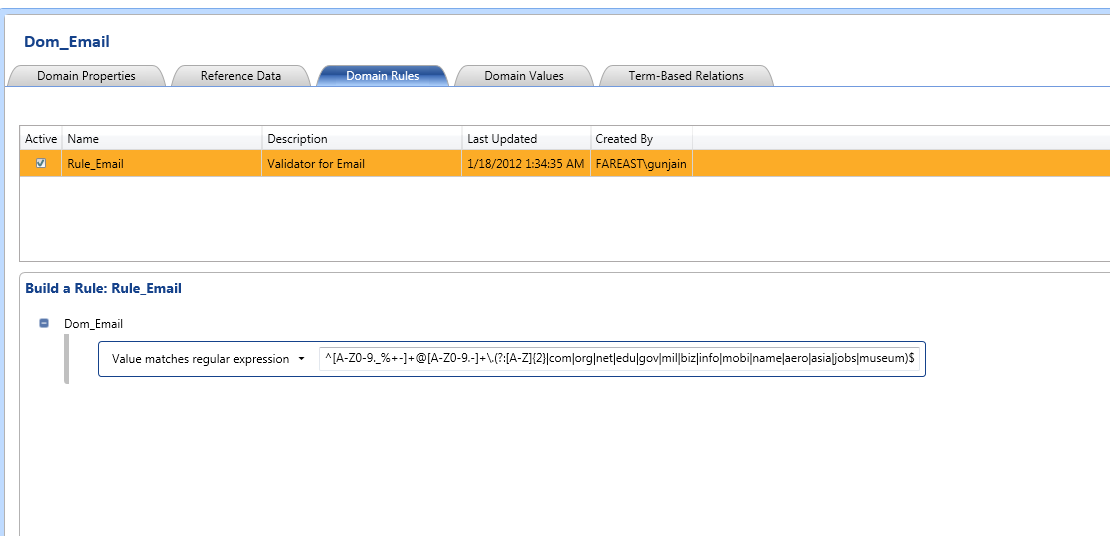
1. As per business requirement, Email should be mentioned in the proper format.
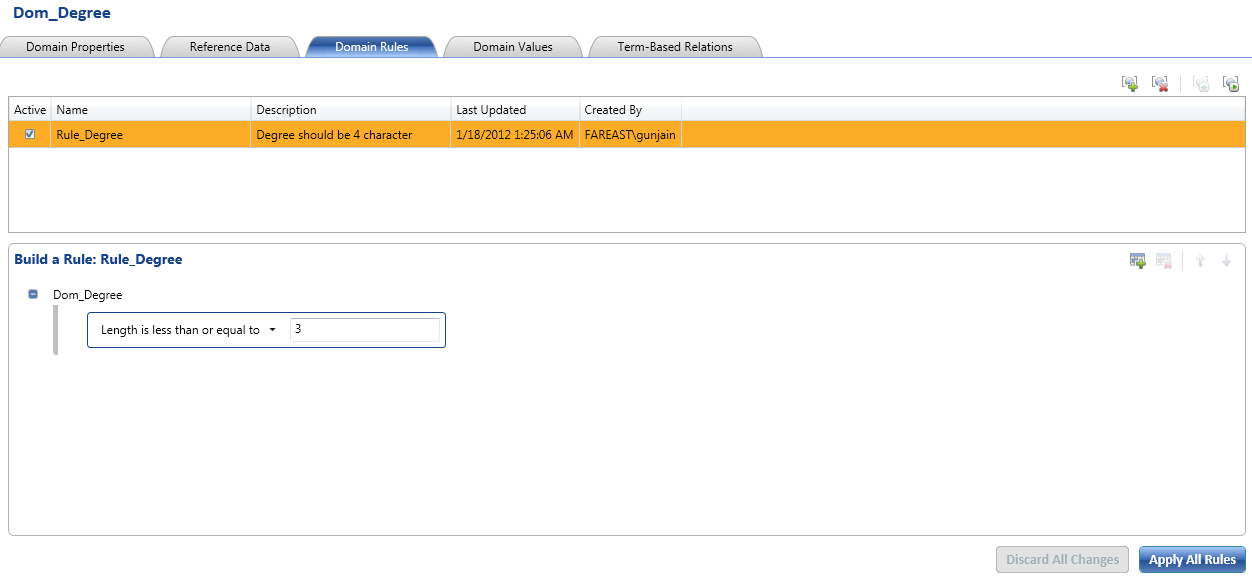
2. Degree should be of 3 characters only.
3. Null values should be identified
By using above 2 sample Databases, we would be showing a full life cycle of how DQS cleanse the data.
Now we Show how a test team can use SQL Server 2012 DQS to test such kind of DQ requirements. You can mention if this activity is done as a project team then that would be ideal and test can focus on defining DQ rules and running them but if DQ requirements are not part of the scope, QA team can itself define knowledge base and do it on their own and show the value to the customer.
Steps to be followed for cleansing the data using DQS
1. Creating Knowledge base– not a core testing team’s activity but test team can do if project team is not adopting Denali DQS formally
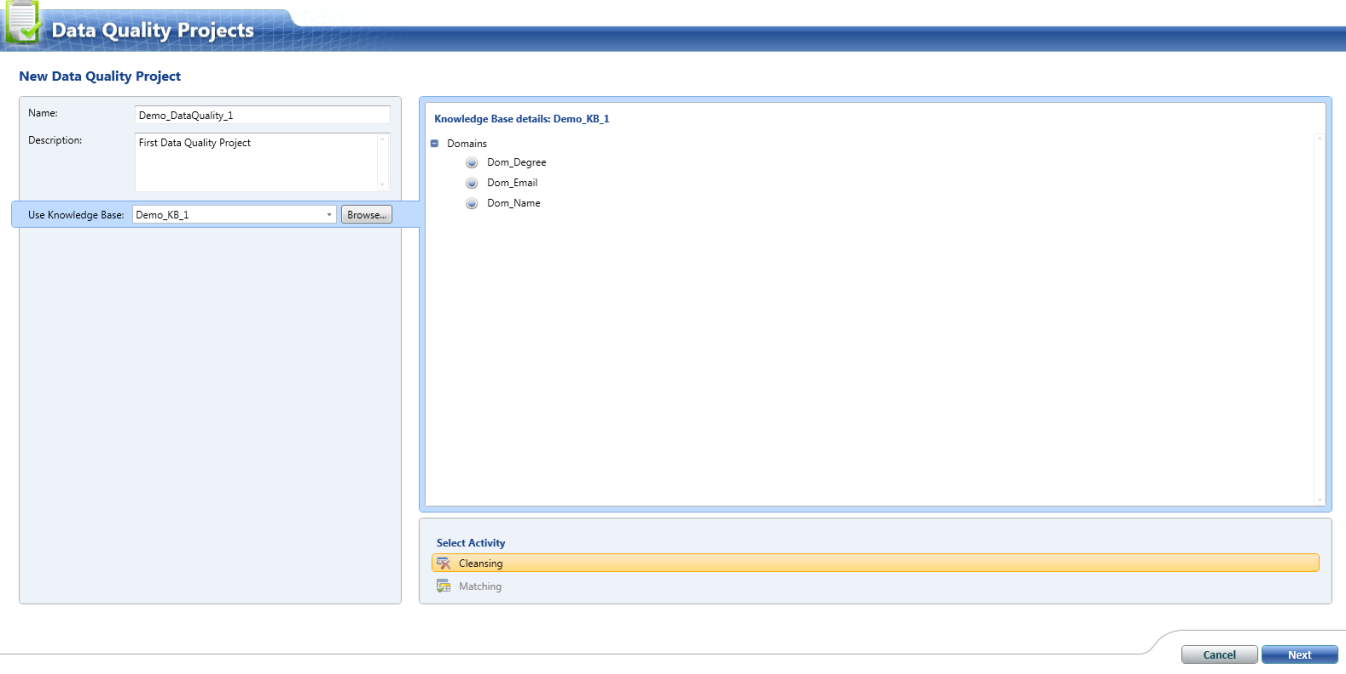
2. Creating the data quality project
3. Executing the data quality project

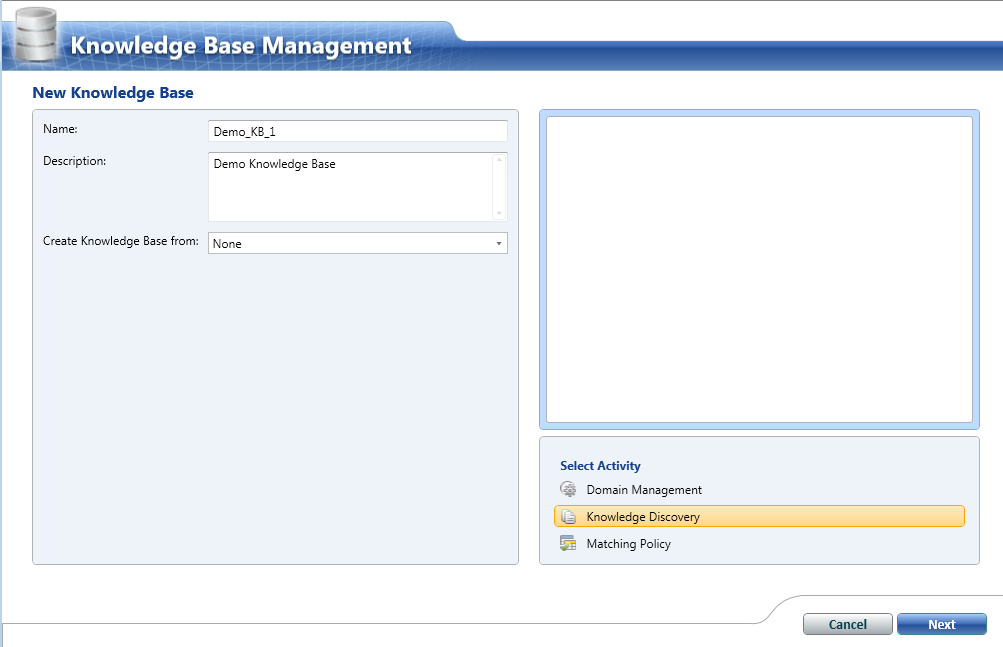

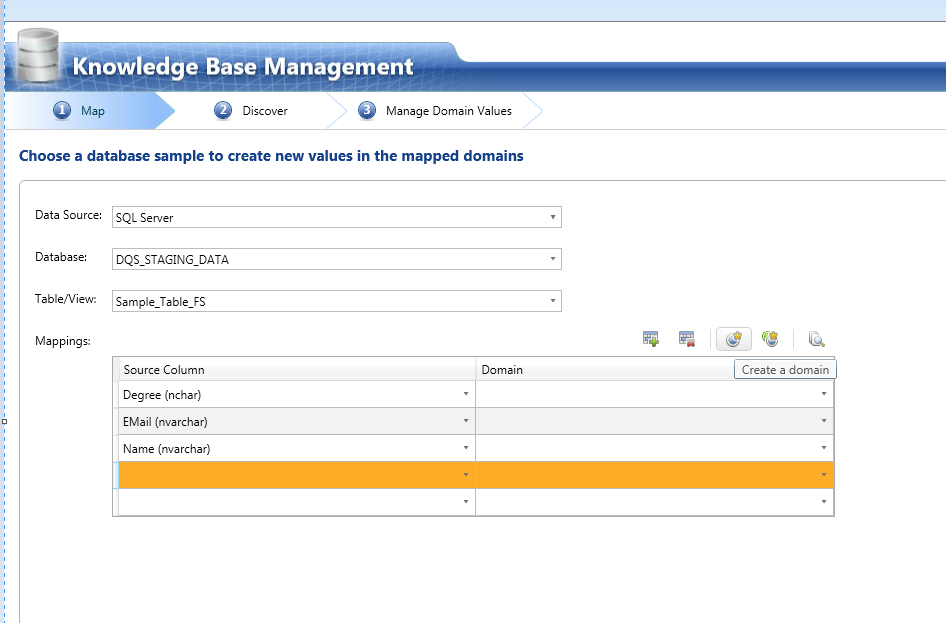

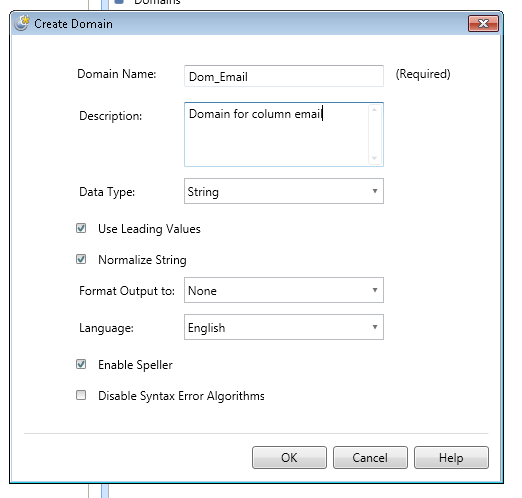


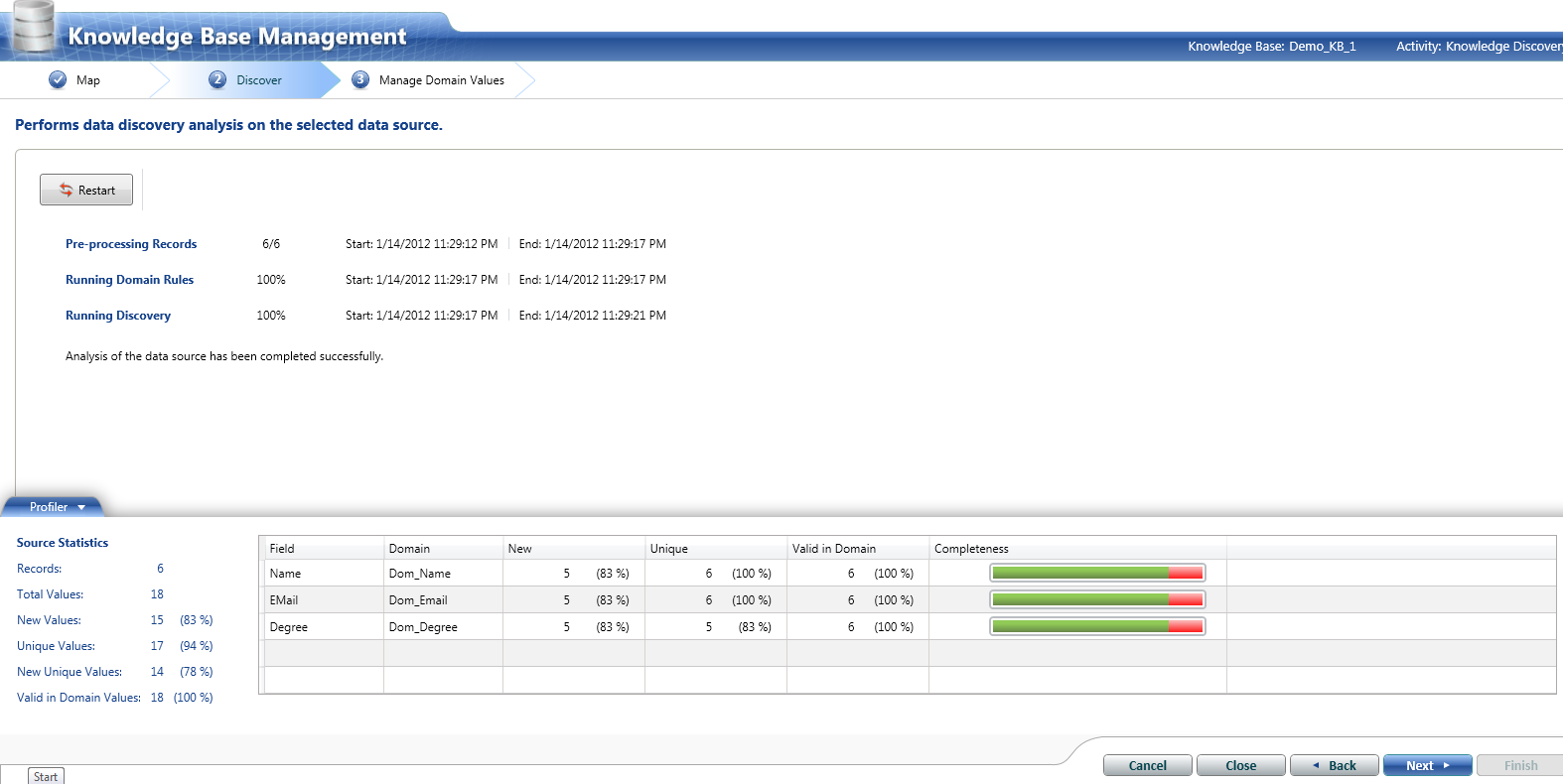

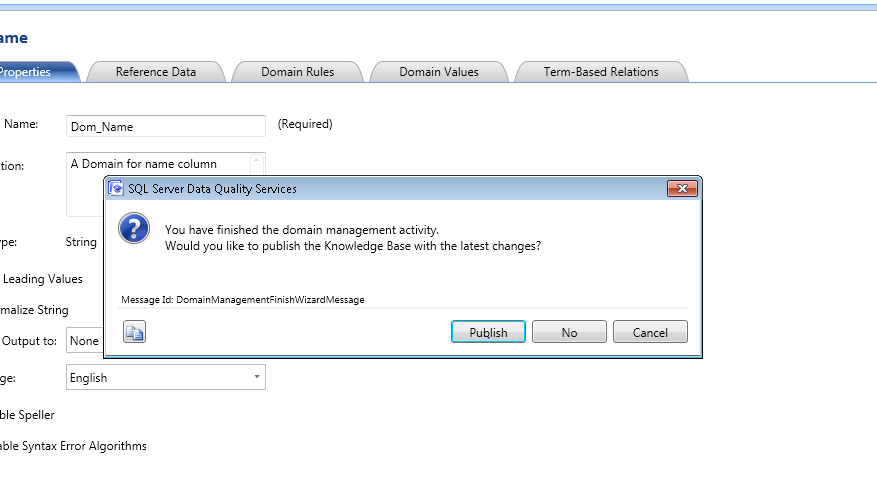
Here, we are done with creating a knowledge base. On the similar steps, user can explore more options provided by DQS client while creating the knowledge base.
We create the knowledge base for Sample_DB_1. Following the same steps as shown above, KB can be created for Sample_DB_2. We won’t be showing the same steps but following screenshot shows the analysis result for Sample_DB_2.
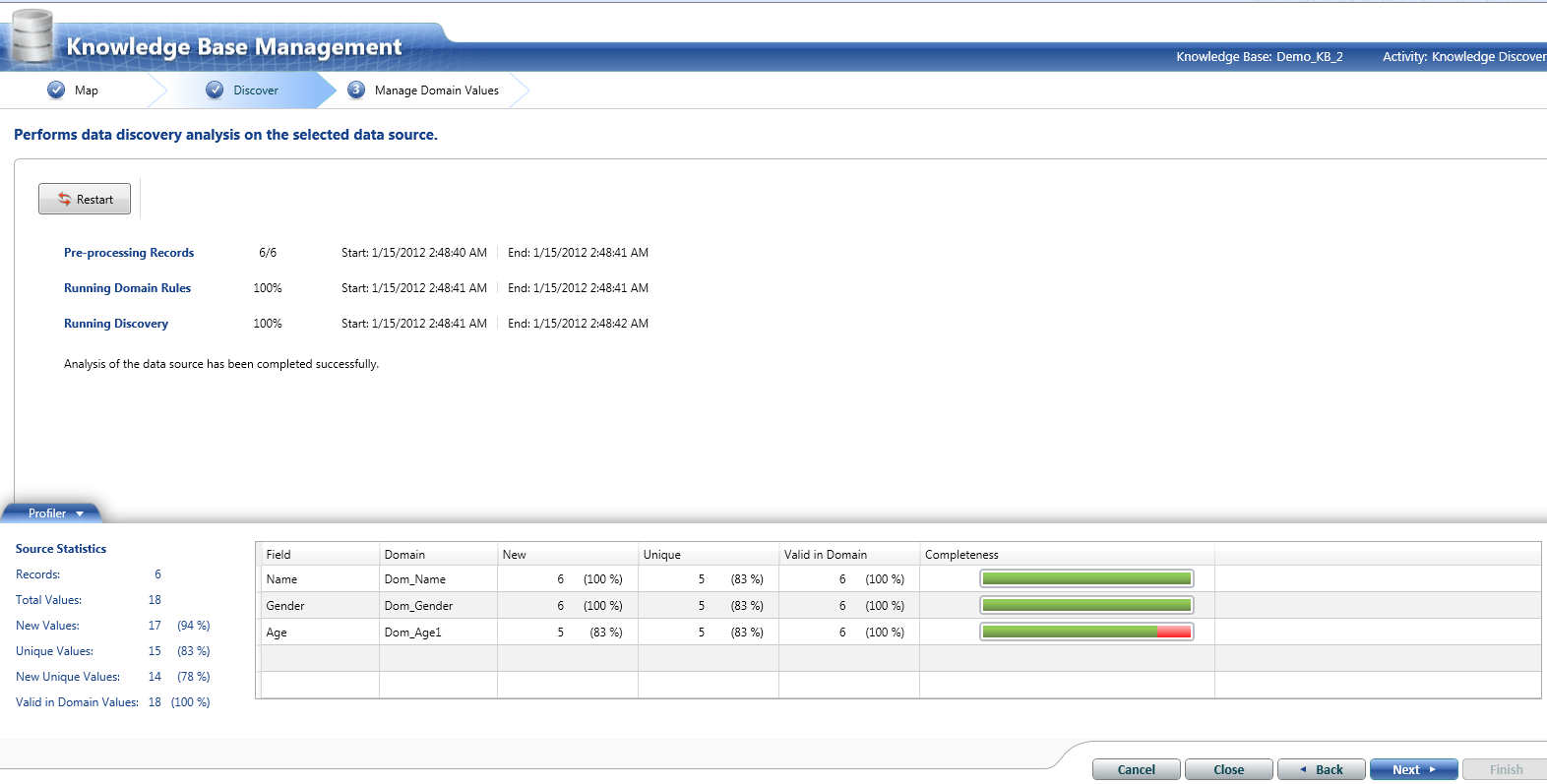
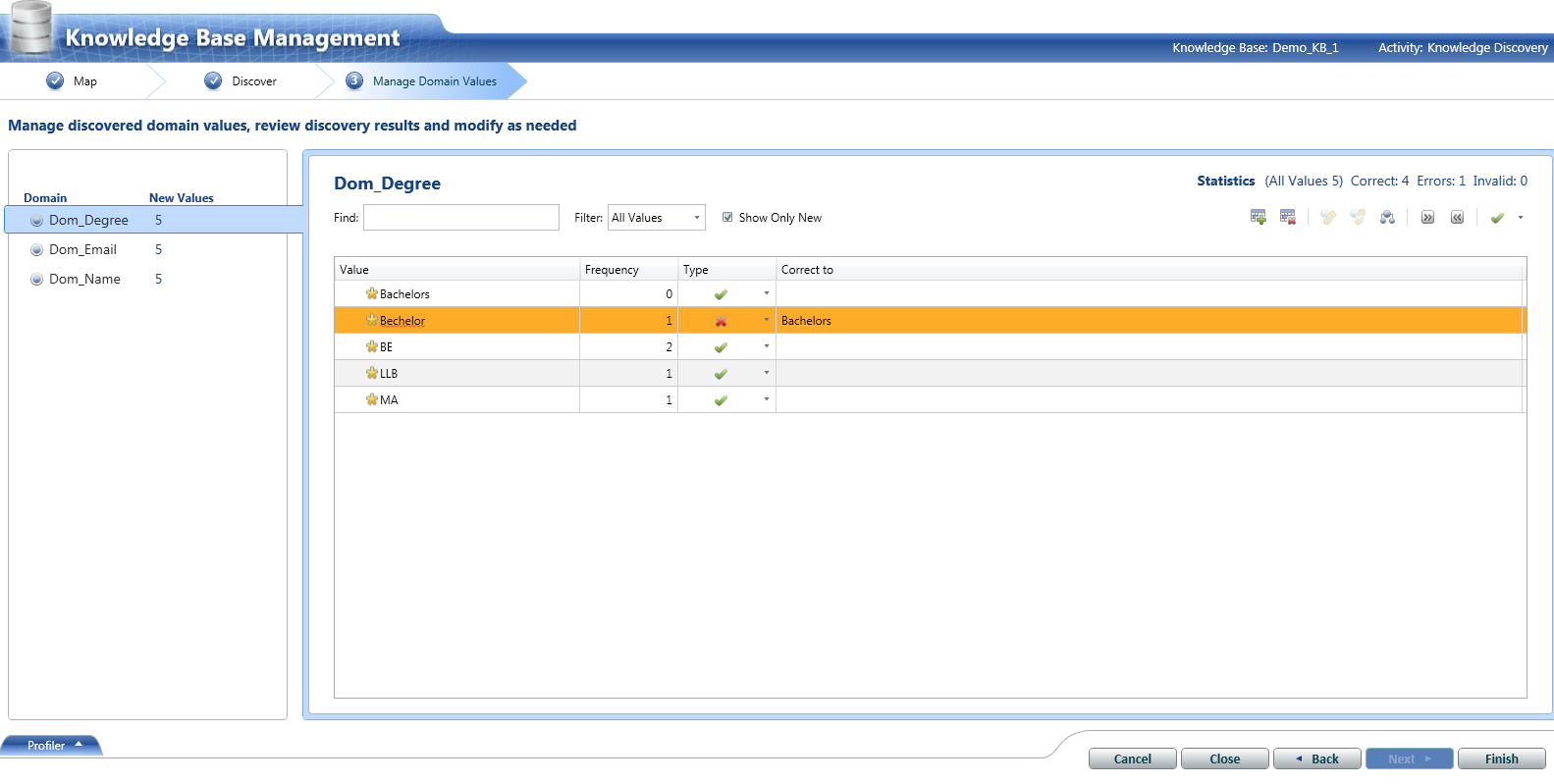
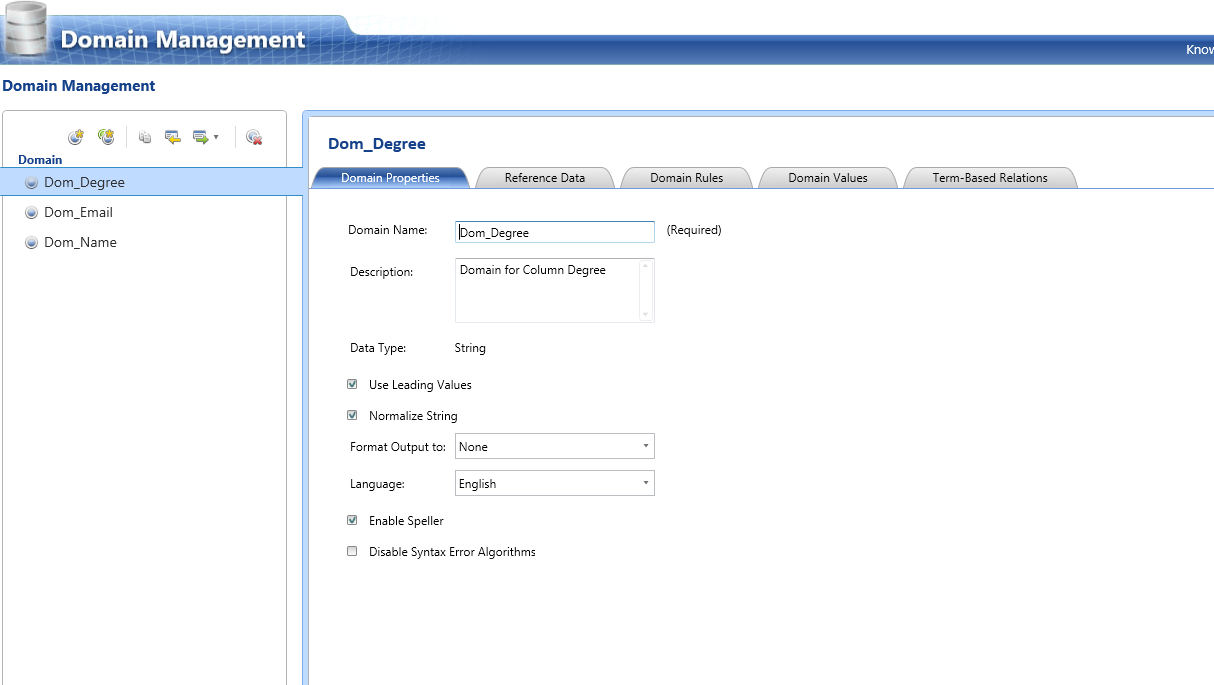
Step:-2 Creating the Domain Management. We will modify the existing domain rules to include the business related rules.







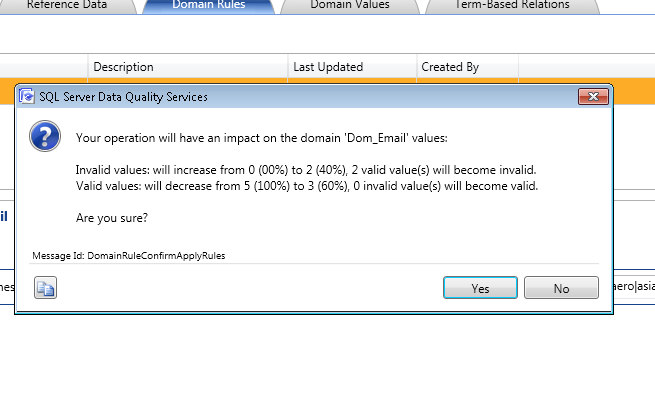


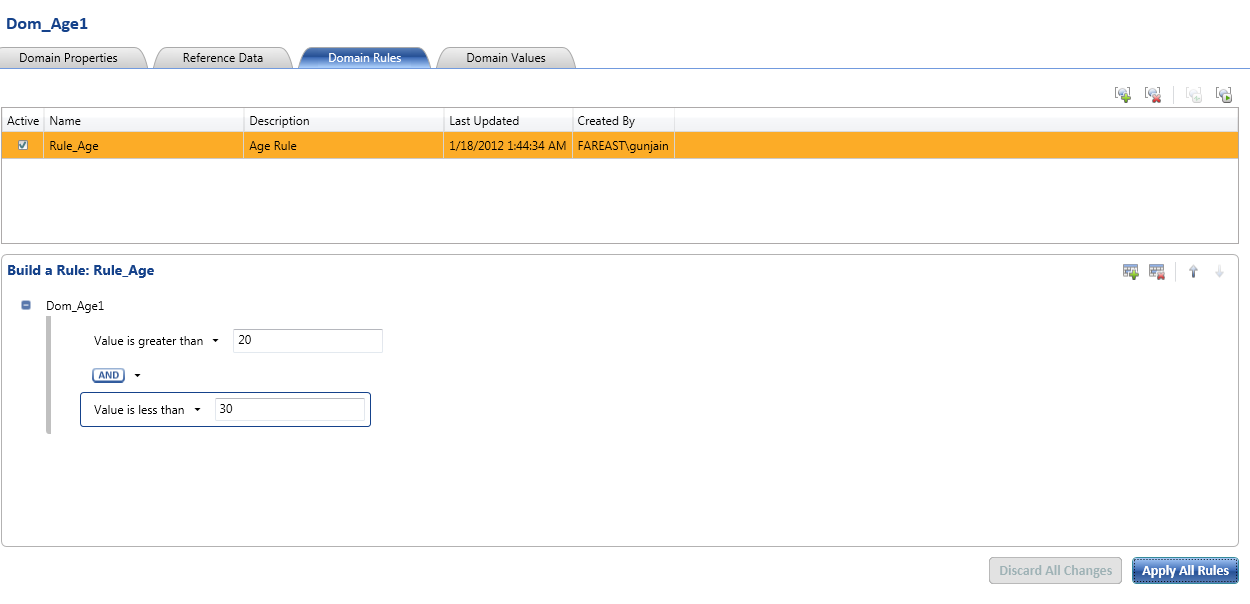




{kind=link}
{kind=link}
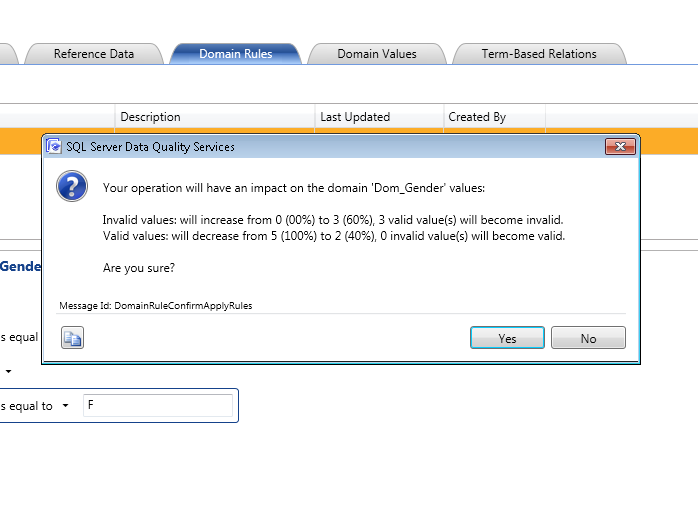

During above activity, we have created knowledge base and designed rules on the basis of which data would be cleansed in the next steps. We have created no. of test scenarios using DQS Rules and now we are in a good state to go and run them.
Following issues have been taken care of:
1. Format – Applied on Email Column
2. Null values
3. Valid – Applied on Age Column
4. Consistent – Applied on Gender Column
For above activity of creating knowledge base and domain rules, we have used a sample database Now, for test execution phase, we can execute the above created rules on the actual database which is nothing but the extended form of the sample data. Let’s start with Test Execution now…
DQS Test Execution


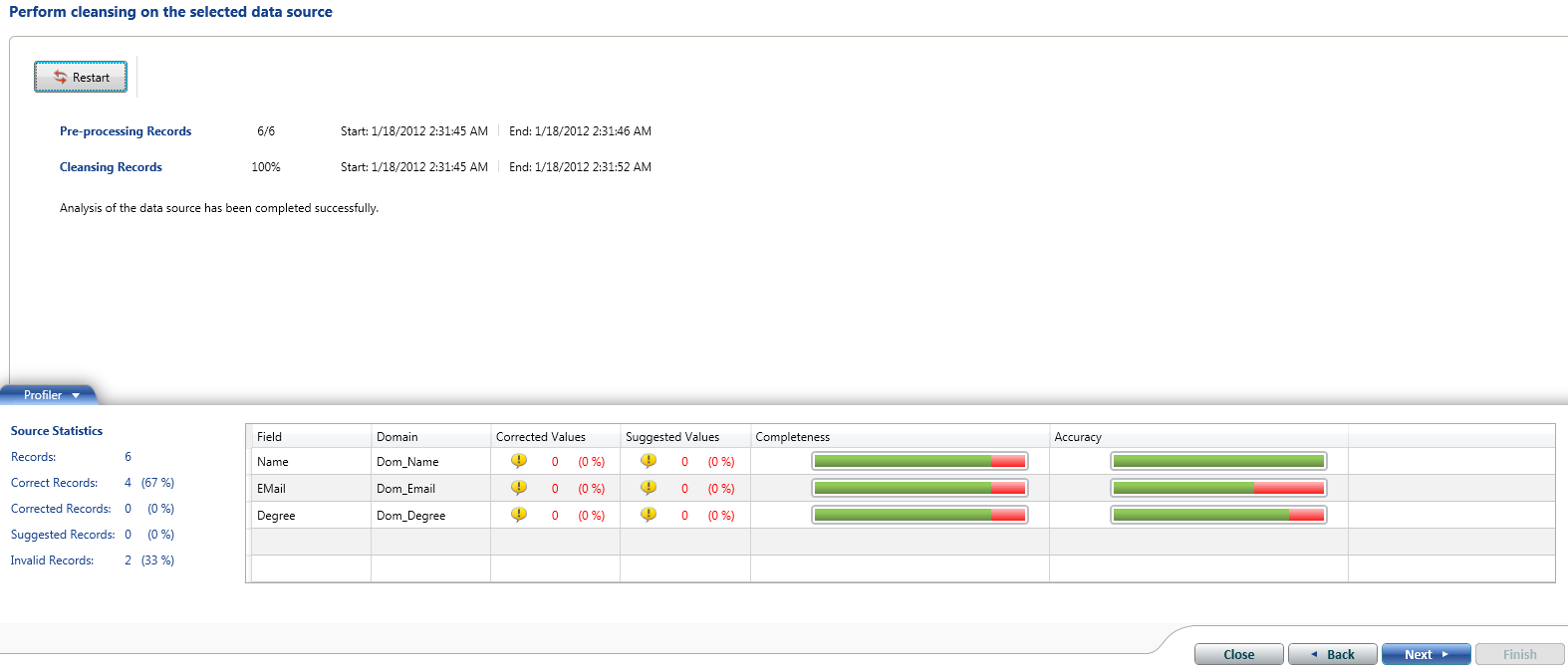

We are good now. We have executed all rules on the data. Ignore the green bar above. Concentrate on red. Those are the issues we are looking for.
During Bug Tracking and Fixing, we will see how some of the errors can be fixed through DQS itself and we can log those issues in the bug tracker.
This is the charm of DQS. You fix or bugs and export them for further testing. Instead of manually going back to SQL and fixing them. Let’s see how we do that.
Bug Tracking and Fixing
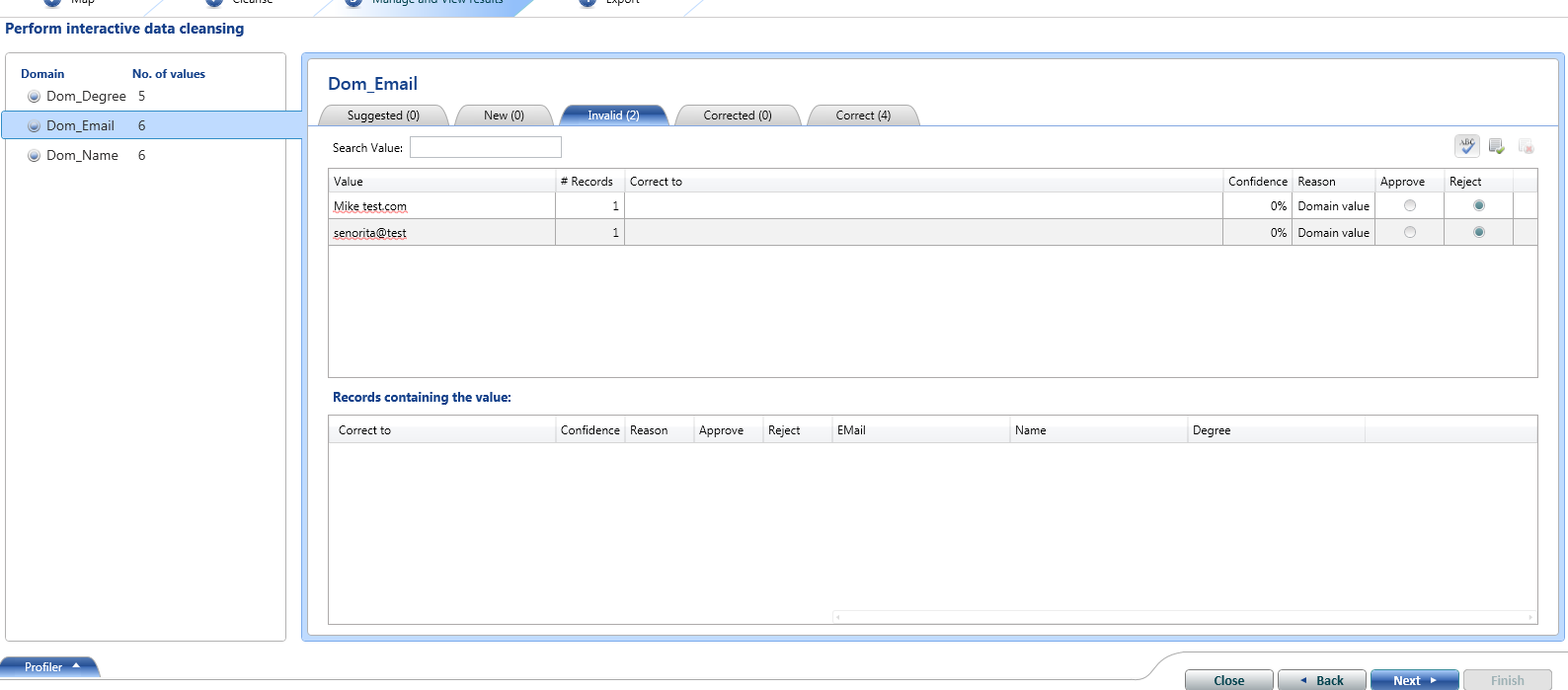

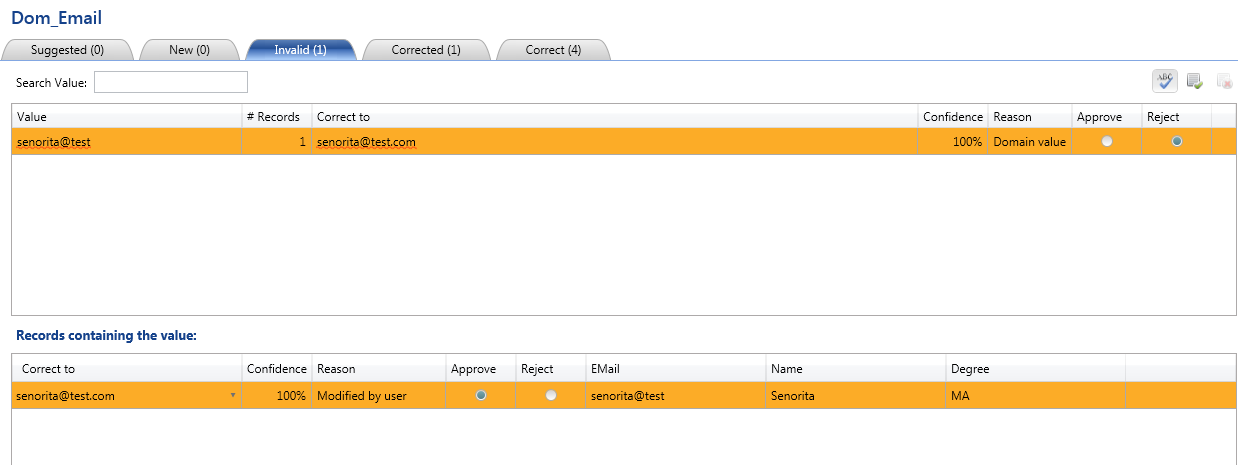


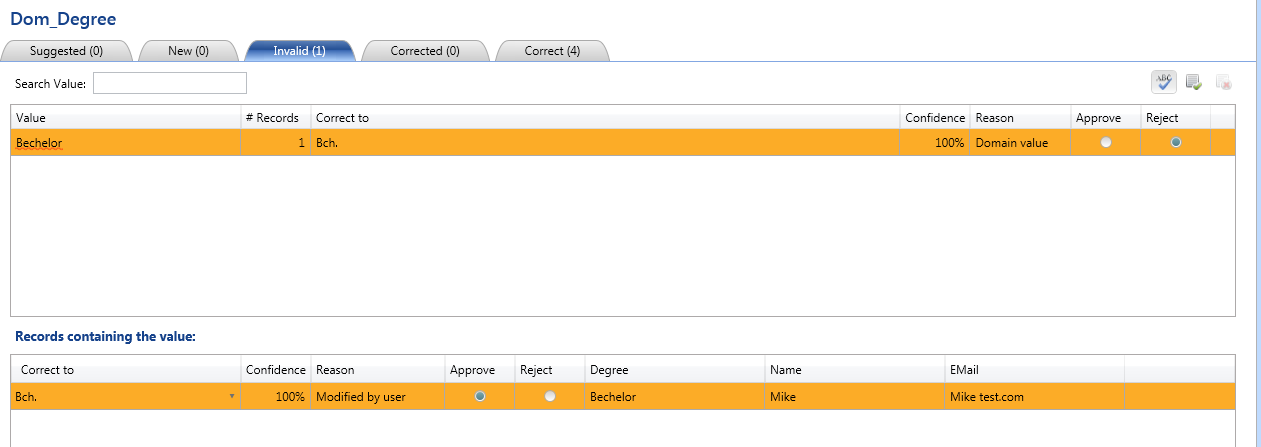
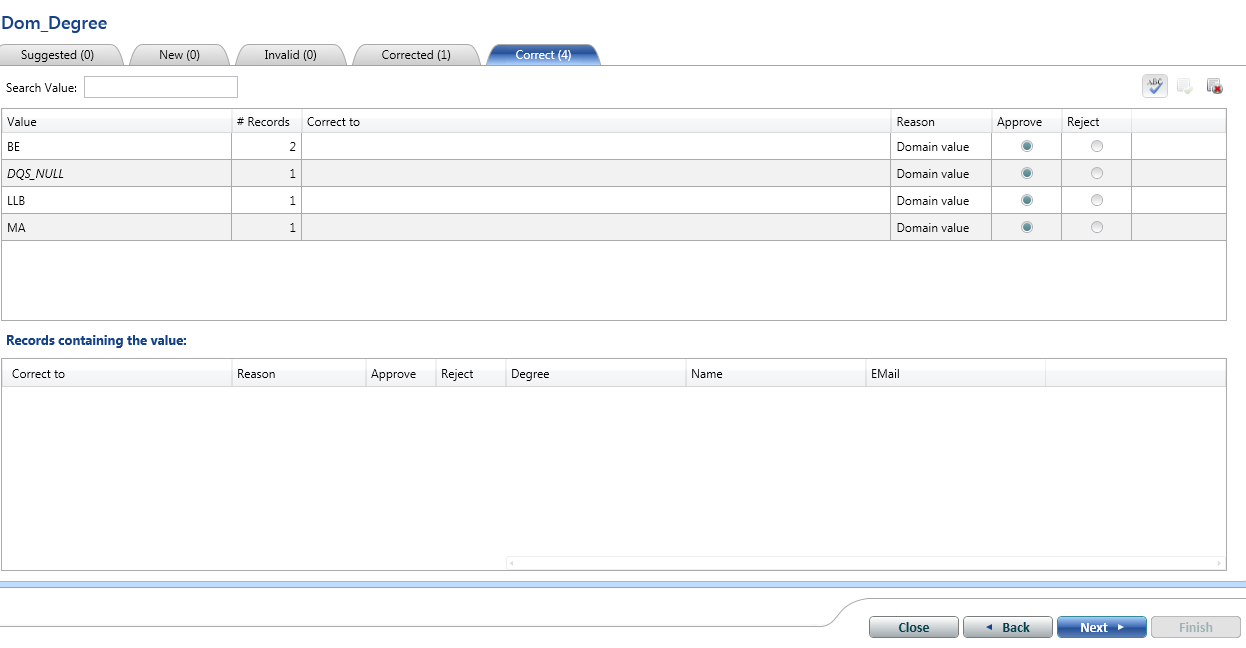

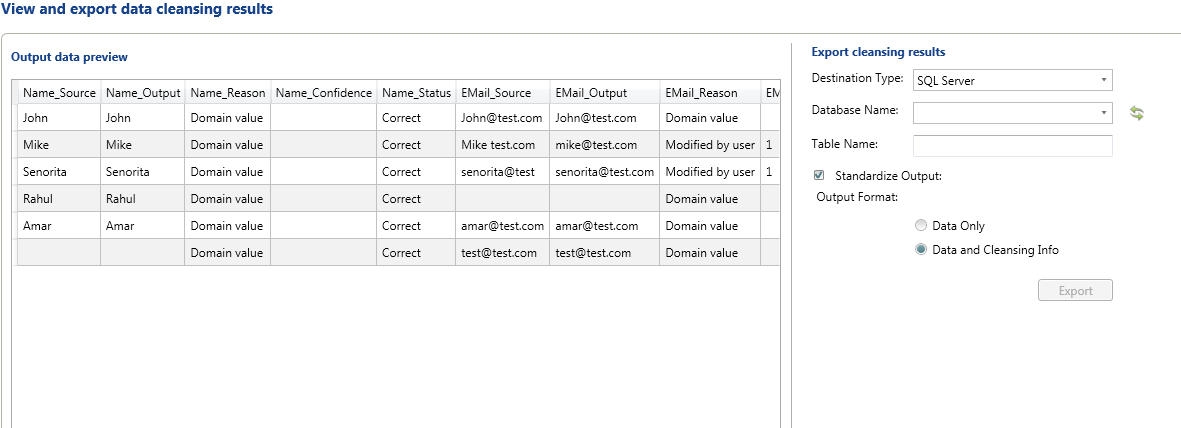



Same process we will apply on the other KB we had created and get the cleansed data exported in the SQL Server DB.
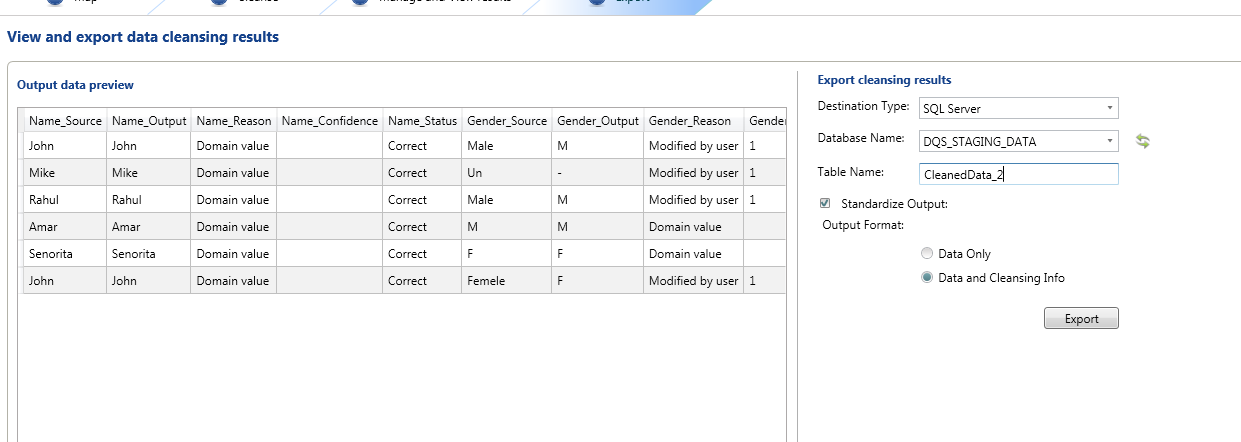

Benefits/Takeaways
Be in a position to evangelize DQS value proposition to Enterprises (including IT teams) in the field to reduce huge cost associated with DQ issues and the pressing need to implement and adopt SQL Server 2012 DQS especially as part of their SDLC to make more informed decisions.
Understand that SQL Server 2012 DQS can be used as an effective tool that can be instrumental in verifying and improving the Data quality of a Data Warehousing / BI / Data-centric project. DQS can help not only Business Users and Data Stewards, but also the IT teams especially the QA and Testing discipline which in the industry are for long craving for such a tool.
Learn that DQS as a verification/validation practice can help ‘prevent’ DQ issues proactively rather than ‘correcting’ it when it’s too late and costly. In addition, automating the process would enable live unattended monitoring that will notify the stakeholders about potential issues that must be given highest attention.
DQS can become consultant’s/IT professional’s good friend as Visual Studio by providing them the ability to better assist the customers in understanding, identifying and correcting issues related to their data.
Conclusion
Enterprises and IT departments worldwide are craving for a framework and approach that can help them prevent Data Quality issues and Denali Data Quality Services (DQS) offer the capabilities that we aim to package and promote in a fashion that makes it easy for the industry in faster adoption and realizing its true potential. Not just for BI or Data warehousing projects, DQS based verification and validation has a strong potential in data-centric projects where data is pivotal for customer to make important and informed decisions.
We wholeheartedly believe that Denali DQS has the potential to be a powerful tool that can help IT teams & consultants (especially QA and Testers) in addition to business user like Data Stewards to detect and prevent DQ issues by effectively leveraging the DQS features and building automated DQ frameworks on top of it.
It is the need of the hour to evangelize the tool in this light when we go to the field and present the learning shared in this session to our customers and partners, who have little knowledge of the potential our tool can offer and the magic it can do.