Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Introduction
As we've seen before, segment elimination can greatly reduce the amount of work required for the query processor to answer a query using columnstore indexes. So far, segment elimination has been limited to date range elimination in our discussions. That's because date range elimination is by far the most frequent form of filtering used in data warehouse queries.
But, with careful design, you can go beyond the ability to eliminate segments based on date ranges, to support segment elimination on more than one dimension. For example, you may want to divide data both by geography and time, if your queries filter on both of these attributes. Consider the following example. You may have data for call detail records from the entire United States. Suppose your business divides the United States into regions, numbered 1 through n, with each region having roughly the same number of people.
Query authors may want to analyze various subsets of this data as follows:
* "What are totals for regions 1, 2 and 3 for January through June of this year?"*
"What are the year-over-year comparisons for region 1 for the last quarter of the fiscal year for the last 5 years?
If we can cause data to be stored so that values with the same region and date are clustered together within the same columnstore segment, then we can accelerate queries that filter on both these attributes in the same query.
There are a couple of ways to accomplish this:
- Use SQL Server table partitioning to partition data by <date_range,region> clusters. Let's call this strategy partition clustering.
- Pre-sort data by <date_range,region>before building a columnstore index. Let's call this strategy order clustering.
Partition Clustering
Suppose the call detail records (CDRs) contain these fields:
(date_id int, region_id int, seconds_duration int, from_number bigint, to_number bigint, ...)
To implement partition clustering, we can create a table that holds these fields, plus a special extra field cluster_id to group data the way we want for clustering purposes to improve segment elimination. We could use the following table schema:
fact_CDR (cluster_id int, date_id int, region_id int, seconds_duration int, from_number bigint, to_number bigint, ...)
We'll design each cluster to contain one month of data for one region. To accomplish this, the cluster_id can be structured as an 8-digit number YYYYMMRR where YYYY is the year, MM is the month, and NN is the region number.
It's important that each cluster have at least a full segment worth (one million rows) of data. Otherwise, the overhead of interpreting the segment metadata during query execution may be too large, and can compromise query response time. You may need to vary the date range width or the region area to create segments that are large enough.
The following illustration shows how to create cluster ID numbers for three months and three regions:
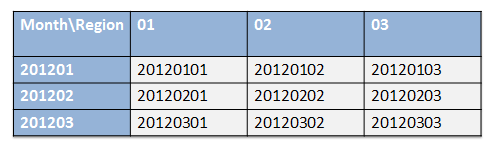
The following script shows how to use this numbering scheme to partition by (month,region) pairs, and get good segment elimination on both dimensions.
-- Create a mapping of numbers to regions.
create table dim_region(region_id int, name varchar(30));
insert dim_region values(1, 'West');
insert dim_region values(2, 'Central');
insert dim_region values(3, 'East');
go
-- Create a fact table partitioned by cluster_id integer values
-- of the form YYYYMMNN where YYYY=year, MM=month, NN=region.
create partition function cf (int) as range left for values
(20120101, 20120102, 20120103,
20120201, 20120202, 20120203,
20120301, 20120302, 20120303);
go
create partition scheme cs as partition cf ALL to ([PRIMARY]);
go
create table fact_CDR(cluster_id int, date_id int, region_id int,
from_number bigint, to_number bigint, duration int)
on cs(cluster_id);
set nocount on;
-- Add data with the appropriate region_id values, derived from
-- actual stored date_id and region_id.
-- region 1
insert fact_CDR values(20120101, 20120107, 1, 4255551234, 4255554321, 120);
insert fact_CDR values(20120201, 20120209, 1, 4255551234, 4255554321, 60);
insert fact_CDR values(20120301, 20120311, 1, 4255551234, 4255554321, 180);
go
-- region 2
insert fact_CDR values(20120102, 20120107, 2, 3125551234, 3125554321, 120);
insert fact_CDR values(20120202, 20120209, 2, 3125551234, 3125554321, 60);
insert fact_CDR values(20120302, 20120311, 2, 3125551234, 3125554321, 180);
-- region 3
insert fact_CDR values(20120103, 20120107, 3, 2125551234, 2125554321, 120);
insert fact_CDR values(20120203, 20120209, 3, 2125551234, 2125554321, 60);
insert fact_CDR values(20120303, 20120311, 3, 2125551234, 2125554321, 180);
-- check data
select * from fact_CDR;
-- Create a columnstore index on the fact table.
create nonclustered columnstore index csi on fact_CDR
(cluster_id, date_id, region_id, from_number, to_number, duration);
-- Turn on text output that shows when segments (row groups) are eliminated.
dbcc traceon(646, -1)
go
-- Direct trace flag text output to the SQL Server error log file.
dbcc traceon(3605, -1)
go
-- Find average call duration for region 1 for January 2012.
-- Error log file output shows that 8 segments are eliminated.
select f.region_id, avg(f.duration) avg_duration
from fact_CDR f
where f.region_id = 1
and f.date_id between 20120101 and 20120131
group by f.region_id
The following diagram shows which segments were eliminated for the query above (as identified by their cluster_id) and which was preserved.
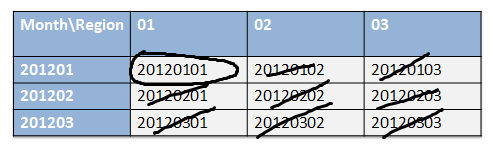
It's interesting that the cluster_id itself was not referenced in the query. We just used it as a tool to physically partition the data along multiple dimensions. The actual segment elimination was done on date_id and region_id columns directly.
The sliding window scenario, whereby you switch out old data and switch in new data, can still be expoited with partition clustering. To allow this, it's important to put the date portion of the cluster_id as the leading digits of the cluster_id, as in the example above. For example, you could switch out the first three partitions in the example to remove data for January 2012 (201201).
To improve on the example above, it will be convenient to create the cluster_id as a persisted computed column derived from other columns. Try this as an exercise! That will simplify ETL and reduce the chance of error. You'll have to omit the cluster_id column from the nonclustered columnstore index, because persisted computed columns are not supported in nonclustered columnstore indexes in SQL Server 2012 RTM. But since normally you will not query on cluster_id, that's not a problem.
Order Clustering
Order clustering is a little easier to manage in some ways because it doesn't require partitioning. But it can be a little harder to control. To implement order clustering, simply create a clustered index either on (cluster_id) or (date_id,region_id) before you create the non-clustered columnstore index. SQL Server preserves the clustered B-tree index order when building the columnstore index. If you have enough data so that each (date_id, region_id) pair will have a full segment or more, you can use (date_id, region_id) as the index key, and it's not necessary to create a cluster_id column. If this leaves segments underpopulated, you may need larger date ranges for each region to have a full segment. In that case, introduce a cluster_id as described above, and create the clustered B-tree on cluster_id.
Conclusion
Both partition clustering and order clustering have the additional benefit of improving compression, because the data in segments will be more closely correlated and thus have more redundancy that can be exploited.
In the examples used here, data was clustered using the date and region dimensions. But of course, it is possible to cluster on other dimensions (like store, product, or customer) as well if that is more appropriate for your application. The choice of how to cluster data is closely linked to what columns your queries use to filter (either directly or via join with a dimension table). Analyze queries for filtering patterns before attempting to cluster data to get better segment elimination.
Finally, this is an advanced technique and unless your database is extremeley large or you have highly demanding response time requirements, it may not be worth the effort. Columnstore indexes and batch mode query processing alone may give you adequate response time without going to the extra effort to improve segment elimination.