Exchange Server 2016 DAG Cluster Troubleshooting; Disaster Recovery Steps –
Introduction
A perfectly running Exchange server 2016 with a Database Availability Group (DAG) cluster can go horribly wrong for many reasons. Some of these occurrences can be prevented since we have a DAG cluster UPS system and a regular backup. There are various items that can hinder the delicate Exchange Server environment, when you have a non-healthy or issues with the Active Directory or network. The most obvious culprit always remain the failure of a hardware such as motherboard, hard drive, RAID controller or any other item in between like fiber switch, cable, etc. Other major reason would be sudden loss of power from a power surge or a faulty power supply. Things that may cripple your Exchange Server can also be non-material such as an interrupted Windows Update, an antivirus or backup software which is not application aware, and viruses, malware or ransomware. All these not only hinder the operational feature of Exchange but can also corrupt your mailbox databases.
Steps to Deal with Disaster Recovery Scenario
Let’s take the example of an Exchange DAG with two servers on the primary side and two on the secondary side, with a witness server which is not one of them. In a normal scenario, where there is a hardware failure or a planned maintenance or upgrade, you should failover to the secondary servers.
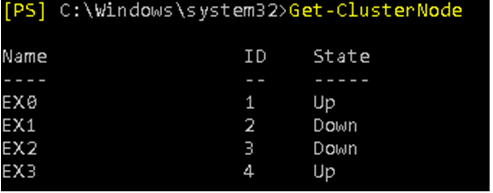
You need to check the status of the DAG by using the *Get-ClusterNode *which will show that the servers in the primary site are down.
The next move would be to stop the partially or totally failed server from the Database Availability Group by using the Stop-DatabaseAvailabilityGroupcommand, with the below parameters.
Stop-DatabaseAvailabilityGroup -Identity DAG01 -MailboxServer EX1 –ConfigurationOnly
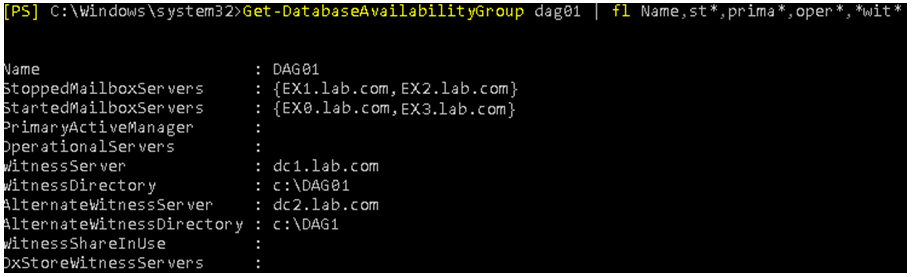
This must be done for all servers which are down. In this case,you need to run one for EX1 and one for EX2. Once confirmed, the mailbox server will be stopped from the DAG in your setup. To see that the selected servers have been stopped, use the Get-DatabaseAvailabilityGroup command.
The next step is to stop the cluster service on the nodes which are still up(In this example, these are EX0 and EX3). The Exchange server DAG works with having the Windows Cluster service installed on all Exchange servers. You can do this be using the Stop-Service clussvc or by opening the Services app.
With this,you remove the faulty servers from the DAG, and stop the cluster service.
The next step is to restore the DAG and start the cluster with healthy databases and cluster.
So, after you have stopped the cluster services, you need to rest the DAG with the *Restore-DatabaseAvailabilityGroup *command, as given below.
Restore-DatabaseAvailabilityGroup -Identity DAG02
Depending on the resources of servers, connectivity between servers and network speed, this process might take some time to finish.
Now, you need to remove restriction and activate the databases to start the replication process. This is the most crucial part of the restore as the databases will be mounted and resume the database copy. For this, use the Get-MailboxDatabaseCopyStatus | ResumeDatabaseCopy and then use the -server to specify the server to see the database status.

If all goes well and you’ve validated the status of databases and all databases are automatically mounted and healthy, you need to verify the status notes with the *Get-ClusterNode *command.
The result should show that both EX0 and EX3 are ‘Up’ with no issues. If you are planning to restore the failed servers, you need to install Exchange Server 2016, Windows Cluster Services and configuration of the network on new servers. Then, use the *Start-DatabaseAvailabilityGroup *commands to add the server and make them part of the DAG.
Start-DatabaseAvailabilitygroup -Identity DAG02 -mailboxServer EX01
Start-DatabaseAvailabilitygroup -Identity DAG02 -mailboxServer EX02
The next command i.e. Set-DatabaseAvailabilityGroup will make the member server an effective part of the cluster.
Set-DatabaseAvailabilityGroup -Identity DAG02
The above command must be executed on all the new members. In this example, these are EX01 and EX02.
Of course, this could be the ideal scenario where during the servers going offline, there was no damage to the databases. If this is the case, the databases will not mount. You will have to use the *EseUtil *with the /mh parameter to identify the problem and checking if the databases are in Dirty Shutdown state.
If this is the case, you need to perform the soft recovery. If it doesn’t work, the only way possible is to restore database from updated backup.